 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEase.ml: Towards Multi-tenant Resource Sharing for Machine Learning Workloads
Paper and Code
Aug 24, 2017
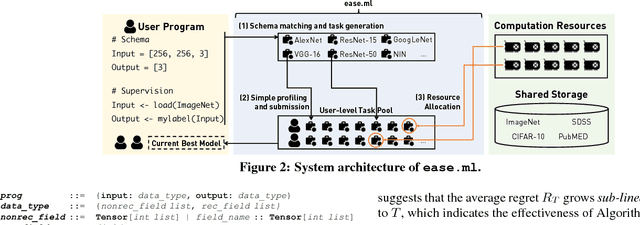
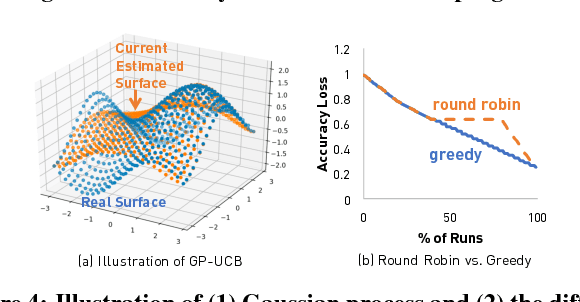
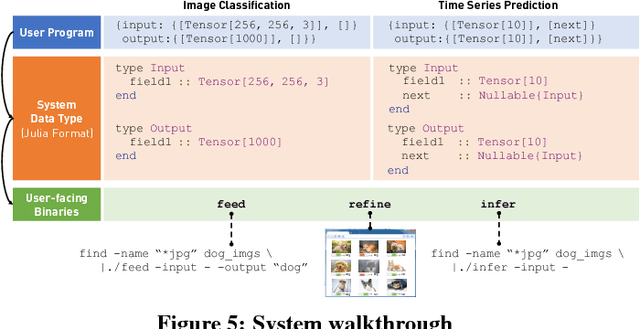
We present ease.ml, a declarative machine learning service platform we built to support more than ten research groups outside the computer science departments at ETH Zurich for their machine learning needs. With ease.ml, a user defines the high-level schema of a machine learning application and submits the task via a Web interface. The system automatically deals with the rest, such as model selection and data movement. In this paper, we describe the ease.ml architecture and focus on a novel technical problem introduced by ease.ml regarding resource allocation. We ask, as a "service provider" that manages a shared cluster of machines among all our users running machine learning workloads, what is the resource allocation strategy that maximizes the global satisfaction of all our users? Resource allocation is a critical yet subtle issue in this multi-tenant scenario, as we have to balance between efficiency and fairness. We first formalize the problem that we call multi-tenant model selection, aiming for minimizing the total regret of all users running automatic model selection tasks. We then develop a novel algorithm that combines multi-armed bandits with Bayesian optimization and prove a regret bound under the multi-tenant setting. Finally, we report our evaluation of ease.ml on synthetic data and on one service we are providing to our users, namely, image classification with deep neural networks. Our experimental evaluation results show that our proposed solution can be up to 9.8x faster in achieving the same global quality for all users as the two popular heuristics used by our users before ease.ml.