 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiCANet: Learning Pixel-wise Contextual Attention for Saliency Detection
Paper and Code

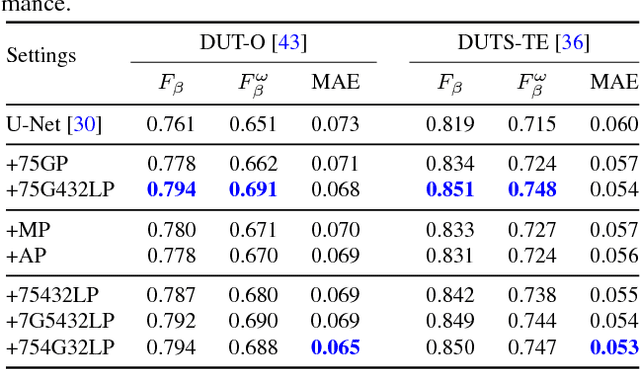
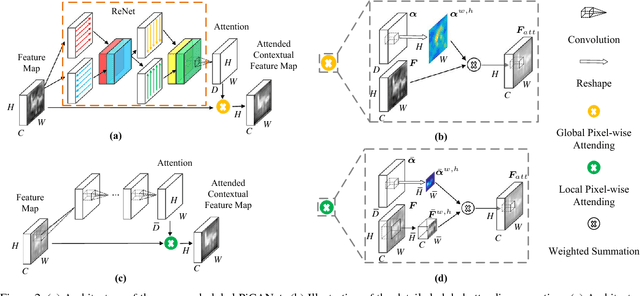
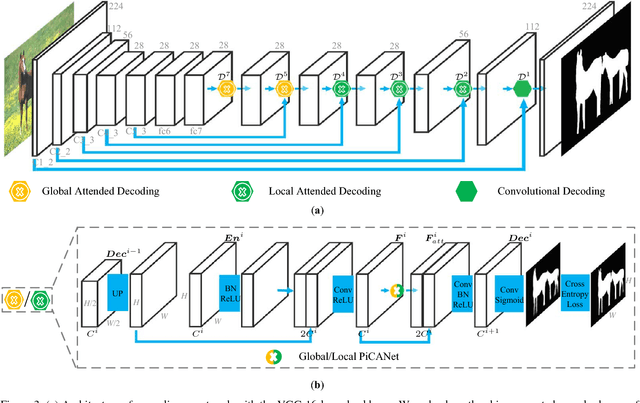
Contexts play an important role in the saliency detection task. However, given a context region, not all contextual information is helpful for the final task. In this paper, we propose a novel pixel-wise contextual attention network, i.e., the PiCANet, to learn to selectively attend to informative context locations for each pixel. Specifically, for each pixel, it can generate an attention map in which each attention weight corresponds to the contextual relevance at each context location. An attended contextual feature can then be constructed by selectively aggregating the contextual information. We formulate the proposed PiCANet in both global and local forms to attend to global and local contexts, respectively. Both models are fully differentiable and can be embedded into CNNs for joint training. We also incorporate the proposed models with the U-Net architecture to detect salient objects. Extensive experiments show that the proposed PiCANets can consistently improve saliency detection performance. The global and local PiCANets facilitate learning global contrast and homogeneousness, respectively. As a result, our saliency model can detect salient objects more accurately and uniformly, thus performing favorably against the state-of-the-art methods.