 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebVision Database: Visual Learning and Understanding from Web Data
Paper and Code

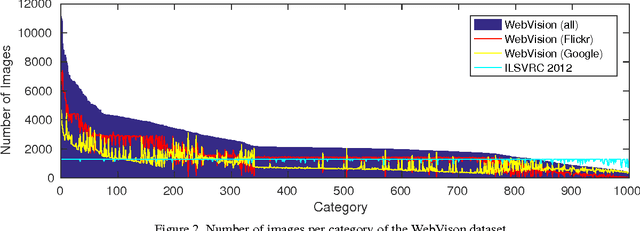
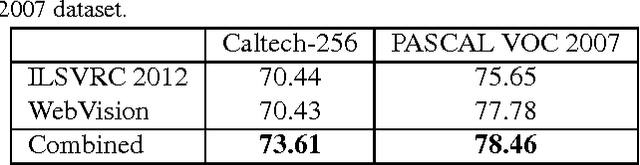

In this paper, we present a study on learning visual recognition models from large scale noisy web data. We build a new database called WebVision, which contains more than $2.4$ million web images crawled from the Internet by using queries generated from the 1,000 semantic concepts of the benchmark ILSVRC 2012 dataset. Meta information along with those web images (e.g., title, description, tags, etc.) are also crawled. A validation set and test set containing human annotated images are also provided to facilitate algorithmic development. Based on our new database, we obtain a few interesting observations: 1) the noisy web images are sufficient for training a good deep CNN model for visual recognition; 2) the model learnt from our WebVision database exhibits comparable or even better generalization ability than the one trained from the ILSVRC 2012 dataset when being transferred to new datasets and tasks; 3) a domain adaptation issue (a.k.a., dataset bias) is observed, which means the dataset can be used as the largest benchmark dataset for visual domain adaptation. Our new WebVision database and relevant studies in this work would benefit the advance of learning state-of-the-art visual models with minimum supervision based on web data.