 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Deterministic to Generative: Multi-Modal Stochastic RNNs for Video Captioning
Paper and Code
Oct 20, 2017
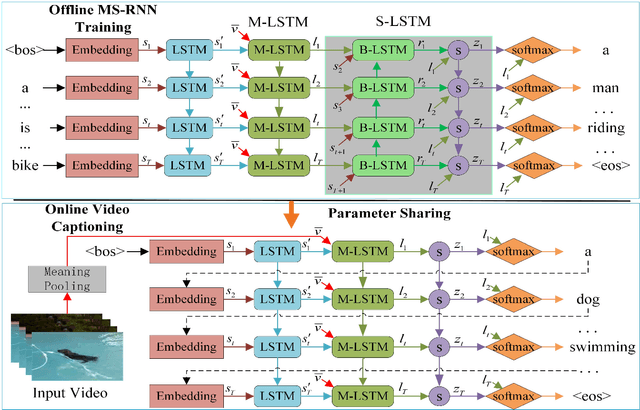
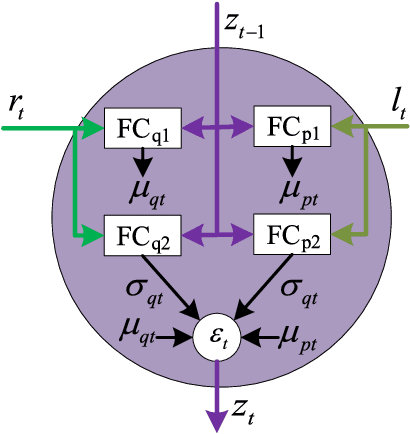
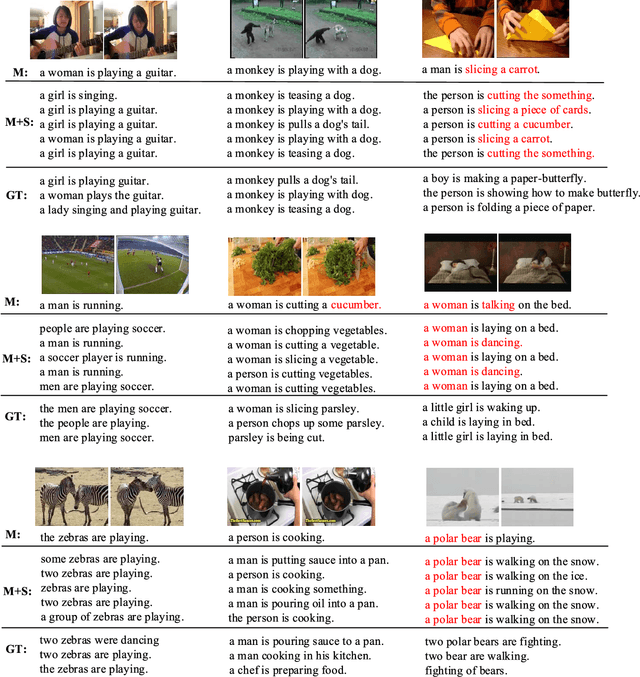
Video captioning in essential is a complex natural process, which is affected by various uncertainties stemming from video content, subjective judgment, etc. In this paper we build on the recent progress in using encoder-decoder framework for video captioning and address what we find to be a critical deficiency of the existing methods, that most of the decoders propagate deterministic hidden states. Such complex uncertainty cannot be modeled efficiently by the deterministic models. In this paper, we propose a generative approach, referred to as multi-modal stochastic RNNs networks (MS-RNN), which models the uncertainty observed in the data using latent stochastic variables. Therefore, MS-RNN can improve the performance of video captioning, and generate multiple sentences to describe a video considering different random factors. Specifically, a multi-modal LSTM (M-LSTM) is first proposed to interact with both visual and textual features to capture a high-level representation. Then, a backward stochastic LSTM (S-LSTM) is proposed to support uncertainty propagation by introducing latent variables. Experimental results on the challenging datasets MSVD and MSR-VTT show that our proposed MS-RNN approach outperforms the state-of-the-art video captioning benchmarks.