 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Attentions for Visual Question Answering
Paper and Code
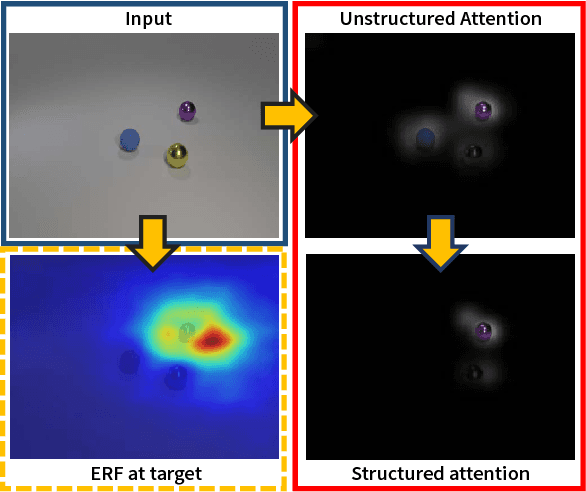
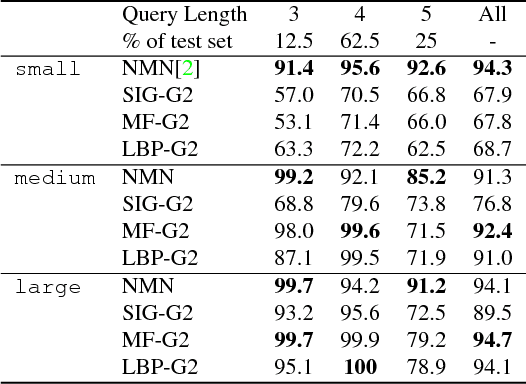
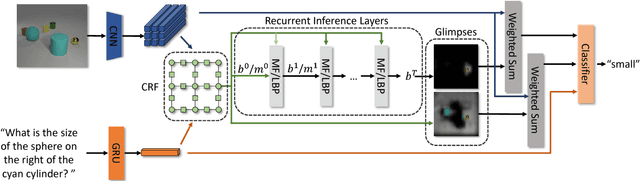
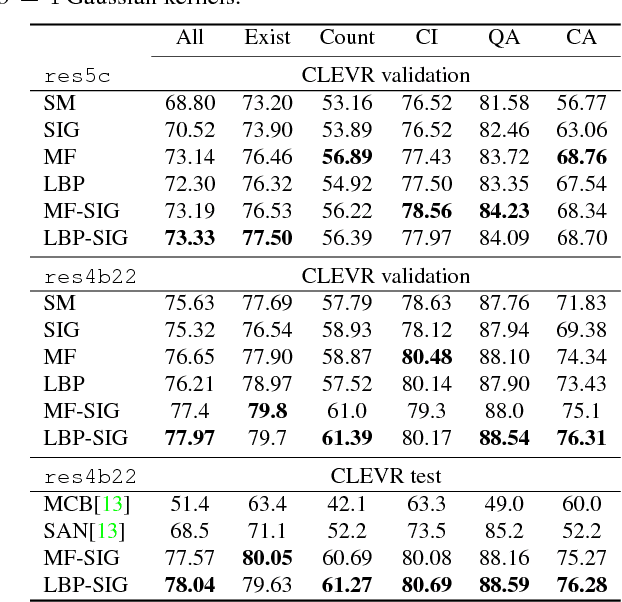
Visual attention, which assigns weights to image regions according to their relevance to a question, is considered as an indispensable part by most Visual Question Answering models. Although the questions may involve complex relations among multiple regions, few attention models can effectively encode such cross-region relations. In this paper, we demonstrate the importance of encoding such relations by showing the limited effective receptive field of ResNet on two datasets, and propose to model the visual attention as a multivariate distribution over a grid-structured Conditional Random Field on image regions. We demonstrate how to convert the iterative inference algorithms, Mean Field and Loopy Belief Propagation, as recurrent layers of an end-to-end neural network. We empirically evaluated our model on 3 datasets, in which it surpasses the best baseline model of the newly released CLEVR dataset by 9.5%, and the best published model on the VQA dataset by 1.25%. Source code is available at https: //github.com/zhuchen03/vqa-sva.