 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic Modeling Using a Shallow CNN-HTSVM Architecture
Paper and Code
Jun 27, 2017
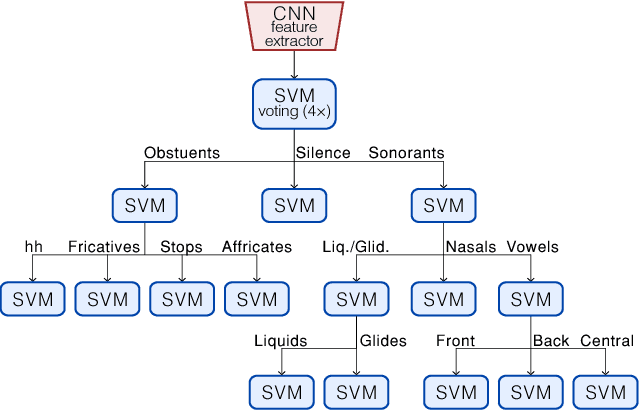
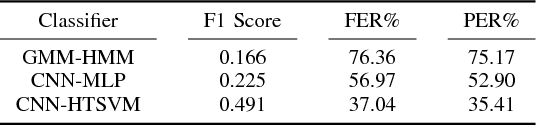
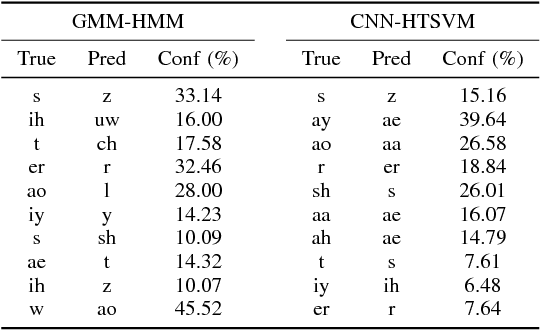
High-accuracy speech recognition is especially challenging when large datasets are not available. It is possible to bridge this gap with careful and knowledge-driven parsing combined with the biologically inspired CNN and the learning guarantees of the Vapnik Chervonenkis (VC) theory. This work presents a Shallow-CNN-HTSVM (Hierarchical Tree Support Vector Machine classifier) architecture which uses a predefined knowledge-based set of rules with statistical machine learning techniques. Here we show that gross errors present even in state-of-the-art systems can be avoided and that an accurate acoustic model can be built in a hierarchical fashion. The CNN-HTSVM acoustic model outperforms traditional GMM-HMM models and the HTSVM structure outperforms a MLP multi-class classifier. More importantly we isolate the performance of the acoustic model and provide results on both the frame and phoneme level considering the true robustness of the model. We show that even with a small amount of data accurate and robust recognition rates can be obtained.