 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Regularity of Sparse Structure in Convolutional Neural Networks
Paper and Code
Jun 05, 2017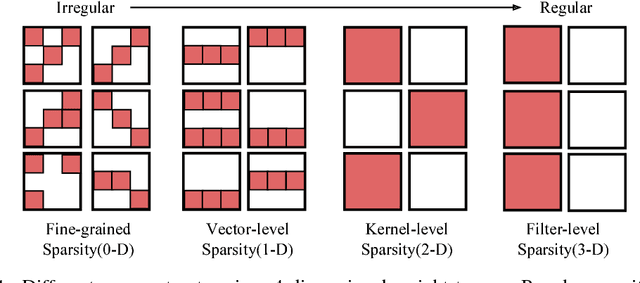
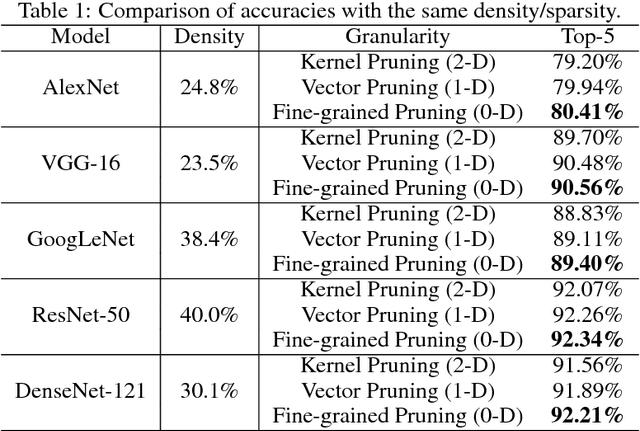
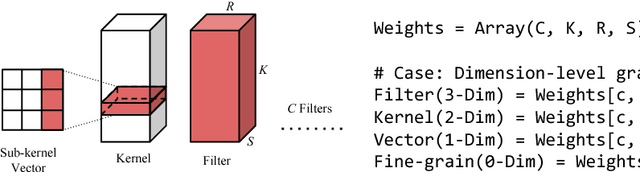
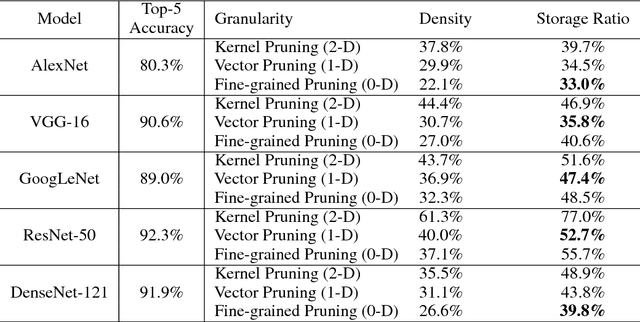
Sparsity helps reduce the computational complexity of deep neural networks by skipping zeros. Taking advantage of sparsity is listed as a high priority in next generation DNN accelerators such as TPU. The structure of sparsity, i.e., the granularity of pruning, affects the efficiency of hardware accelerator design as well as the prediction accuracy. Coarse-grained pruning creates regular sparsity patterns, making it more amenable for hardware acceleration but more challenging to maintain the same accuracy. In this paper we quantitatively measure the trade-off between sparsity regularity and prediction accuracy, providing insights in how to maintain accuracy while having more a more structured sparsity pattern. Our experimental results show that coarse-grained pruning can achieve a sparsity ratio similar to unstructured pruning without loss of accuracy. Moreover, due to the index saving effect, coarse-grained pruning is able to obtain a better compression ratio than fine-grained sparsity at the same accuracy threshold. Based on the recent sparse convolutional neural network accelerator (SCNN), our experiments further demonstrate that coarse-grained sparsity saves about 2x the memory references compared to fine-grained sparsity. Since memory reference is more than two orders of magnitude more expensive than arithmetic operations, the regularity of sparse structure leads to more efficient hardware design.