 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascade one-vs-rest detection network for fine-grained recognition without part annotations
Paper and Code
Aug 23, 2017

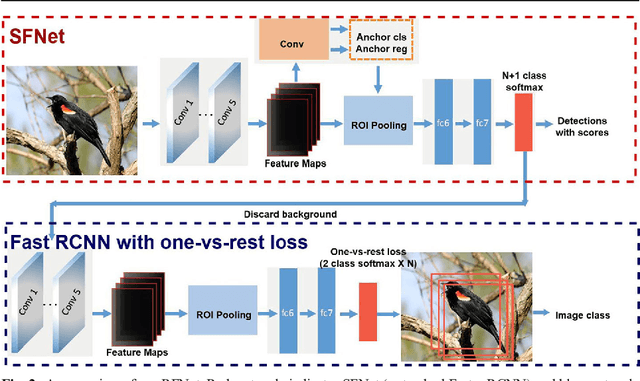

Fine-grained recognition is a challenging task due to the small intra-category variances. Most of top-performing fine-grained recognition methods leverage parts of objects for better performance. Therefore, part annotations which are extremely computationally expensive are required. In this paper, we propose a novel cascaded deep CNN detection framework for fine-grained recognition which is trained to detect the whole object without considering parts. Nevertheless, most of current top-performing detection networks use the N+1 class (N object categories plus background) softmax loss, and the background category with much more training samples dominates the feature learning progress so that the features are not good for object categories with fewer samples. To bridge this gap, we introduce a cascaded structure to eliminate background and exploit a one-vs-rest loss to capture more minute variances among different subordinate categories. Experiments show that our proposed recognition framework achieves comparable performance with state-of-the-art, part-free, fine-grained recognition methods on the CUB-200-2011 Bird dataset. Moreover, our method even outperforms most of part-based methods while does not need part annotations at the training stage and is free from any annotations at test stage.