 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple to Complex Cross-modal Learning to Rank
Paper and Code
Jul 07, 2017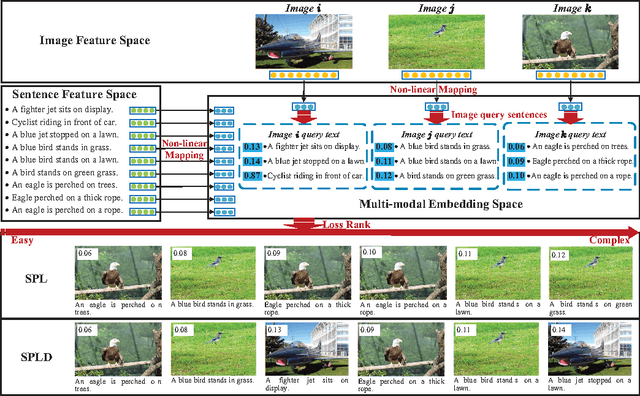
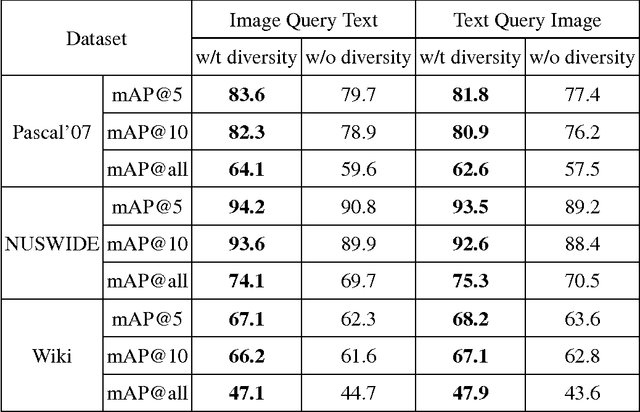

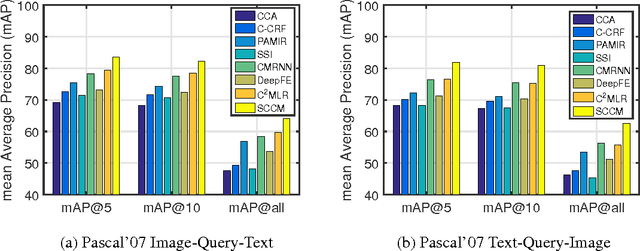
The heterogeneity-gap between different modalities brings a significant challenge to multimedia information retrieval. Some studies formalize the cross-modal retrieval tasks as a ranking problem and learn a shared multi-modal embedding space to measure the cross-modality similarity. However, previous methods often establish the shared embedding space based on linear mapping functions which might not be sophisticated enough to reveal more complicated inter-modal correspondences. Additionally, current studies assume that the rankings are of equal importance, and thus all rankings are used simultaneously, or a small number of rankings are selected randomly to train the embedding space at each iteration. Such strategies, however, always suffer from outliers as well as reduced generalization capability due to their lack of insightful understanding of procedure of human cognition. In this paper, we involve the self-paced learning theory with diversity into the cross-modal learning to rank and learn an optimal multi-modal embedding space based on non-linear mapping functions. This strategy enhances the model's robustness to outliers and achieves better generalization via training the model gradually from easy rankings by diverse queries to more complex ones. An efficient alternative algorithm is exploited to solve the proposed challenging problem with fast convergence in practice. Extensive experimental results on several benchmark datasets indicate that the proposed method achieves significant improvements over the state-of-the-arts in this literature.