 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing Skills with Semi-Supervised Reinforcement Learning
Paper and Code

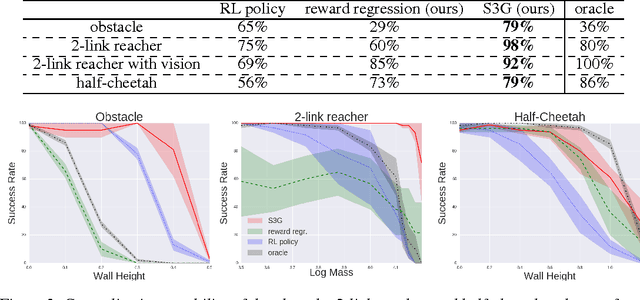
Deep reinforcement learning (RL) can acquire complex behaviors from low-level inputs, such as images. However, real-world applications of such methods require generalizing to the vast variability of the real world. Deep networks are known to achieve remarkable generalization when provided with massive amounts of labeled data, but can we provide this breadth of experience to an RL agent, such as a robot? The robot might continuously learn as it explores the world around it, even while deployed. However, this learning requires access to a reward function, which is often hard to measure in real-world domains, where the reward could depend on, for example, unknown positions of objects or the emotional state of the user. Conversely, it is often quite practical to provide the agent with reward functions in a limited set of situations, such as when a human supervisor is present or in a controlled setting. Can we make use of this limited supervision, and still benefit from the breadth of experience an agent might collect on its own? In this paper, we formalize this problem as semisupervised reinforcement learning, where the reward function can only be evaluated in a set of "labeled" MDPs, and the agent must generalize its behavior to the wide range of states it might encounter in a set of "unlabeled" MDPs, by using experience from both settings. Our proposed method infers the task objective in the unlabeled MDPs through an algorithm that resembles inverse RL, using the agent's own prior experience in the labeled MDPs as a kind of demonstration of optimal behavior. We evaluate our method on challenging tasks that require control directly from images, and show that our approach can improve the generalization of a learned deep neural network policy by using experience for which no reward function is available. We also show that our method outperforms direct supervised learning of the reward.