 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Summarization with Read-Again and Copy Mechanism
Paper and Code
Nov 10, 2016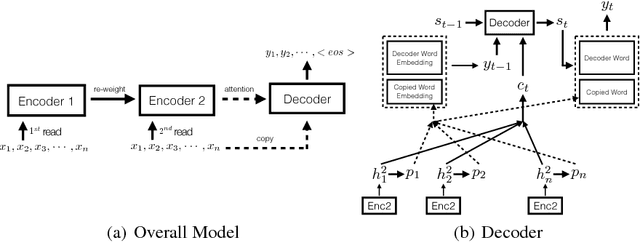
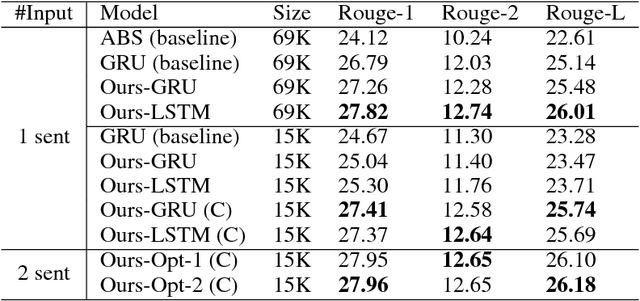
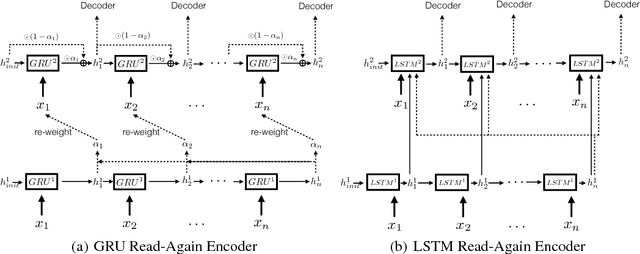
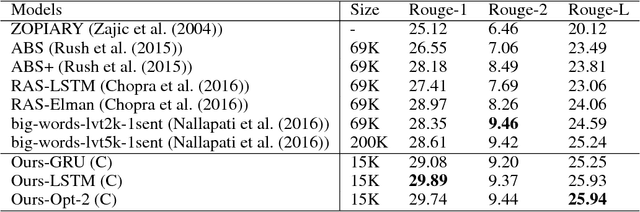
Encoder-decoder models have been widely used to solve sequence to sequence prediction tasks. However current approaches suffer from two shortcomings. First, the encoders compute a representation of each word taking into account only the history of the words it has read so far, yielding suboptimal representations. Second, current decoders utilize large vocabularies in order to minimize the problem of unknown words, resulting in slow decoding times. In this paper we address both shortcomings. Towards this goal, we first introduce a simple mechanism that first reads the input sequence before committing to a representation of each word. Furthermore, we propose a simple copy mechanism that is able to exploit very small vocabularies and handle out-of-vocabulary words. We demonstrate the effectiveness of our approach on the Gigaword dataset and DUC competition outperforming the state-of-the-art.