 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MGB-2 Challenge: Arabic Multi-Dialect Broadcast Media Recognition
Paper and Code
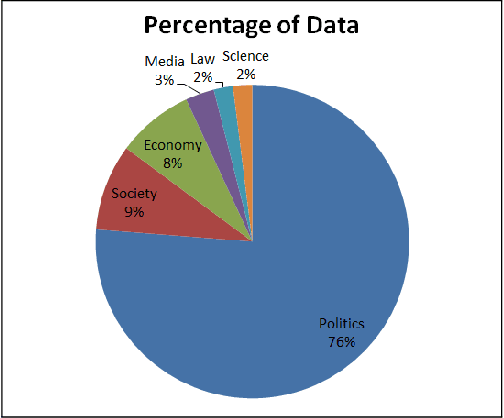
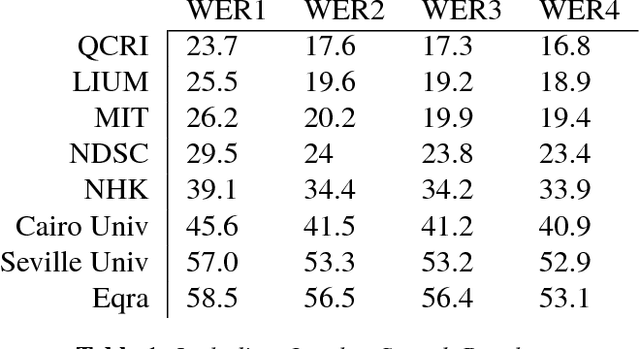
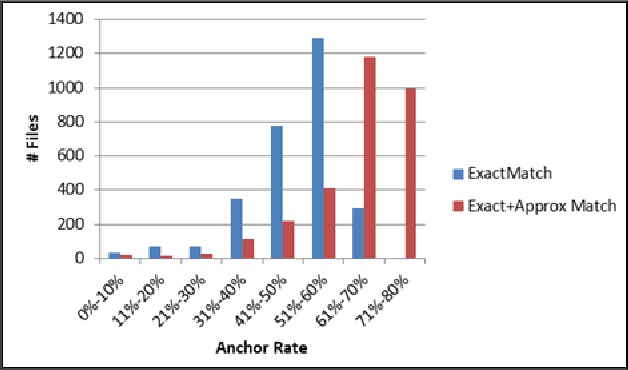
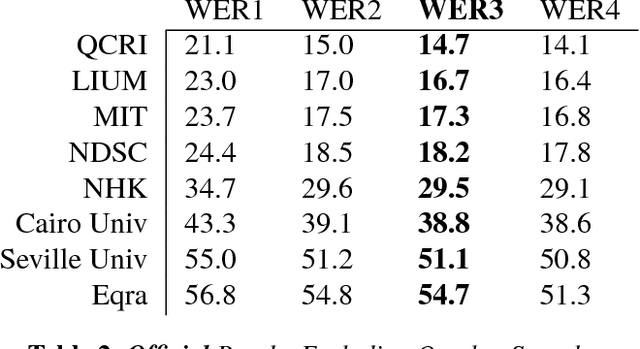
This paper describes the Arabic Multi-Genre Broadcast (MGB-2) Challenge for SLT-2016. Unlike last year's English MGB Challenge, which focused on recognition of diverse TV genres, this year, the challenge has an emphasis on handling the diversity in dialect in Arabic speech. Audio data comes from 19 distinct programmes from the Aljazeera Arabic TV channel between March 2005 and December 2015. Programmes are split into three groups: conversations, interviews, and reports. A total of 1,200 hours have been released with lightly supervised transcriptions for the acoustic modelling. For language modelling, we made available over 110M words crawled from Aljazeera Arabic website Aljazeera.net for a 10 year duration 2000-2011. Two lexicons have been provided, one phoneme based and one grapheme based. Finally, two tasks were proposed for this year's challenge: standard speech transcription, and word alignment. This paper describes the task data and evaluation process used in the MGB challenge, and summarises the results obtained.