 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Deep Trajectory Descriptor for Action Recognition with Three-stream CNN
Paper and Code
Feb 10, 2017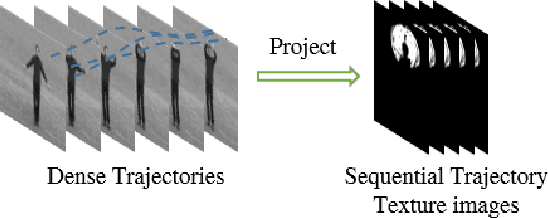

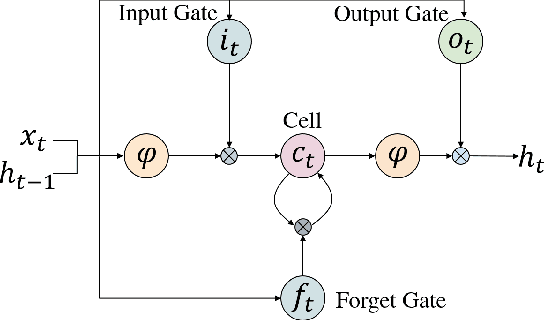
Learning the spatial-temporal representation of motion information is crucial to human action recognition. Nevertheless, most of the existing features or descriptors cannot capture motion information effectively, especially for long-term motion. To address this problem, this paper proposes a long-term motion descriptor called sequential Deep Trajectory Descriptor (sDTD). Specifically, we project dense trajectories into two-dimensional planes, and subsequently a CNN-RNN network is employed to learn an effective representation for long-term motion. Unlike the popular two-stream ConvNets, the sDTD stream is introduced into a three-stream framework so as to identify actions from a video sequence. Consequently, this three-stream framework can simultaneously capture static spatial features, short-term motion and long-term motion in the video. Extensive experiments were conducted on three challenging datasets: KTH, HMDB51 and UCF101. Experimental results show that our method achieves state-of-the-art performance on the KTH and UCF101 datasets, and is comparable to the state-of-the-art methods on the HMDB51 dataset.