 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking State-of-the-Art Deep Learning Software Tools
Paper and Code
Feb 17, 2017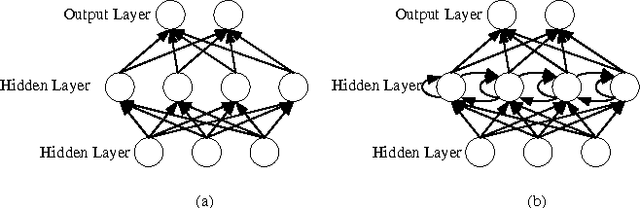

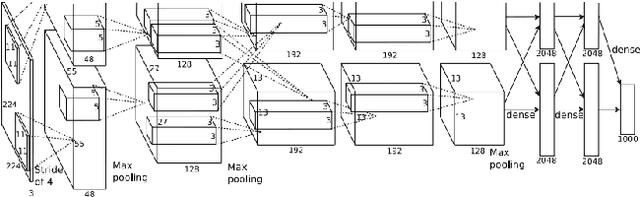
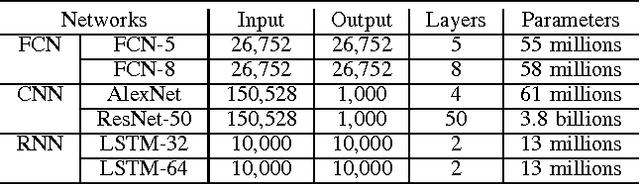
Deep learning has been shown as a successful machine learning method for a variety of tasks, and its popularity results in numerous open-source deep learning software tools. Training a deep network is usually a very time-consuming process. To address the computational challenge in deep learning, many tools exploit hardware features such as multi-core CPUs and many-core GPUs to shorten the training time. However, different tools exhibit different features and running performance when training different types of deep networks on different hardware platforms, which makes it difficult for end users to select an appropriate pair of software and hardware. In this paper, we aim to make a comparative study of the state-of-the-art GPU-accelerated deep learning software tools, including Caffe, CNTK, MXNet, TensorFlow, and Torch. We first benchmark the running performance of these tools with three popular types of neural networks on two CPU platforms and three GPU platforms. We then benchmark some distributed versions on multiple GPUs. Our contribution is two-fold. First, for end users of deep learning tools, our benchmarking results can serve as a guide to selecting appropriate hardware platforms and software tools. Second, for software developers of deep learning tools, our in-depth analysis points out possible future directions to further optimize the running performance.