 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reconstruction-Classification Networks for Unsupervised Domain Adaptation
Paper and Code
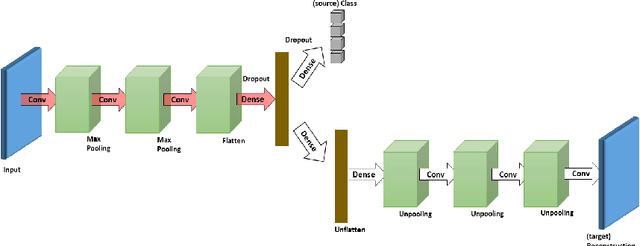
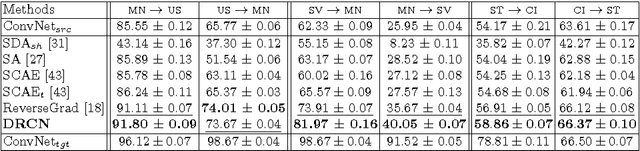


In this paper, we propose a novel unsupervised domain adaptation algorithm based on deep learning for visual object recognition. Specifically, we design a new model called Deep Reconstruction-Classification Network (DRCN), which jointly learns a shared encoding representation for two tasks: i) supervised classification of labeled source data, and ii) unsupervised reconstruction of unlabeled target data.In this way, the learnt representation not only preserves discriminability, but also encodes useful information from the target domain. Our new DRCN model can be optimized by using backpropagation similarly as the standard neural networks. We evaluate the performance of DRCN on a series of cross-domain object recognition tasks, where DRCN provides a considerable improvement (up to ~8% in accuracy) over the prior state-of-the-art algorithms. Interestingly, we also observe that the reconstruction pipeline of DRCN transforms images from the source domain into images whose appearance resembles the target dataset. This suggests that DRCN's performance is due to constructing a single composite representation that encodes information about both the structure of target images and the classification of source images. Finally, we provide a formal analysis to justify the algorithm's objective in domain adaptation context.