 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource-LDA: Enhancing probabilistic topic models using prior knowledge sources
Paper and Code
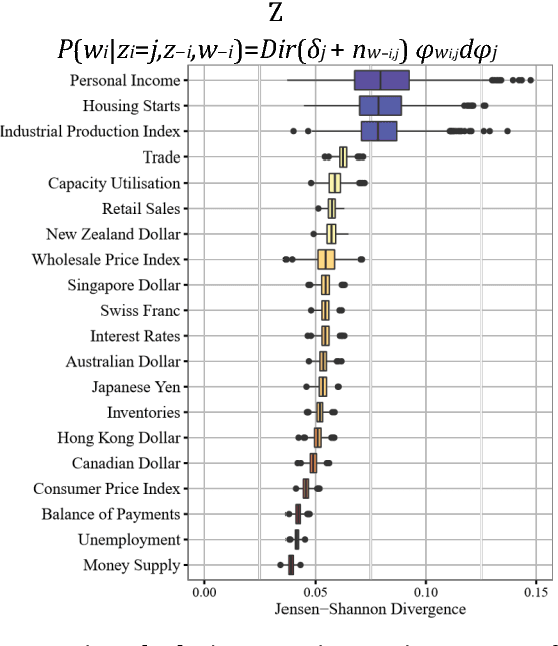
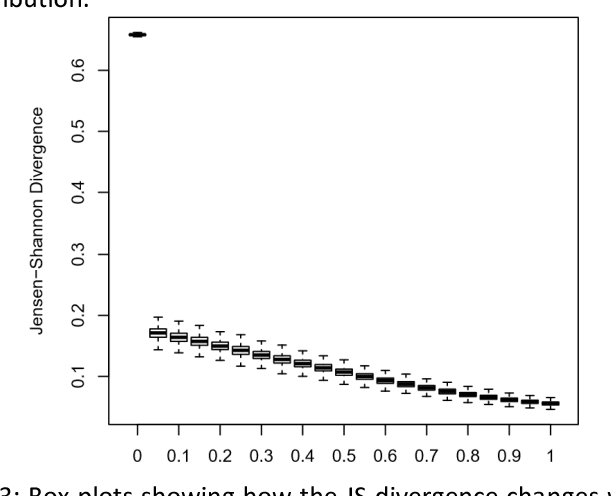
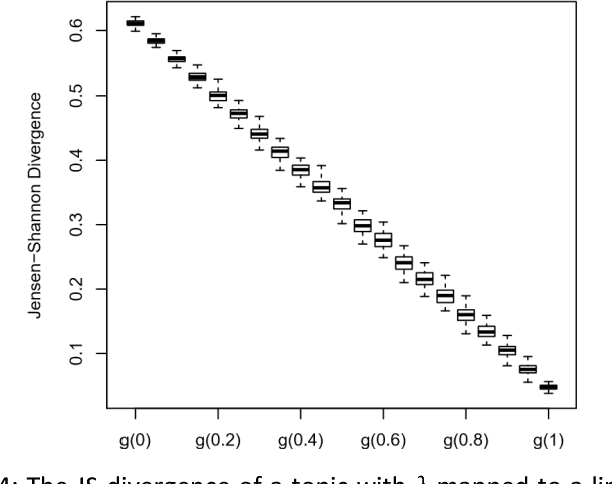
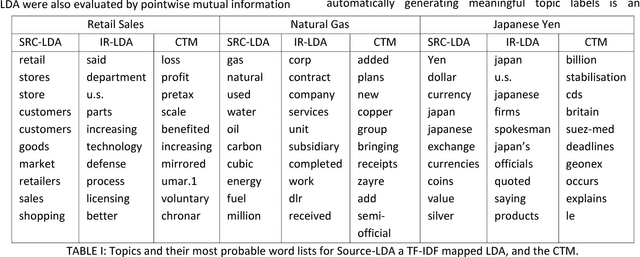
A popular approach to topic modeling involves extracting co-occurring n-grams of a corpus into semantic themes. The set of n-grams in a theme represents an underlying topic, but most topic modeling approaches are not able to label these sets of words with a single n-gram. Such labels are useful for topic identification in summarization systems. This paper introduces a novel approach to labeling a group of n-grams comprising an individual topic. The approach taken is to complement the existing topic distributions over words with a known distribution based on a predefined set of topics. This is done by integrating existing labeled knowledge sources representing known potential topics into the probabilistic topic model. These knowledge sources are translated into a distribution and used to set the hyperparameters of the Dirichlet generated distribution over words. In the inference these modified distributions guide the convergence of the latent topics to conform with the complementary distributions. This approach ensures that the topic inference process is consistent with existing knowledge. The label assignment from the complementary knowledge sources are then transferred to the latent topics of the corpus. The results show both accurate label assignment to topics as well as improved topic generation than those obtained using various labeling approaches based off Latent Dirichlet allocation (LDA).