 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hierarchical Latent Variable Encoder-Decoder Model for Generating Dialogues
Paper and Code
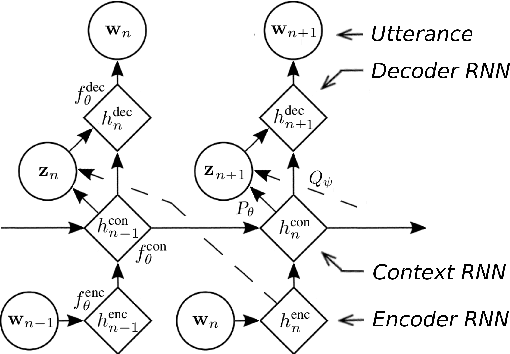
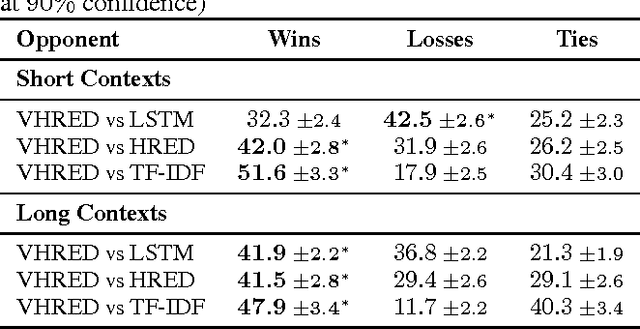

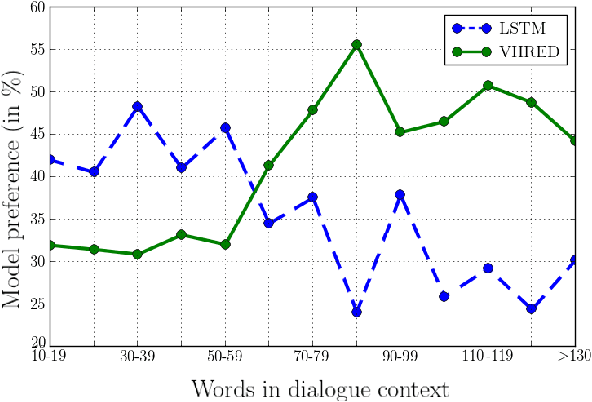
Sequential data often possesses a hierarchical structure with complex dependencies between subsequences, such as found between the utterances in a dialogue. In an effort to model this kind of generative process, we propose a neural network-based generative architecture, with latent stochastic variables that span a variable number of time steps. We apply the proposed model to the task of dialogue response generation and compare it with recent neural network architectures. We evaluate the model performance through automatic evaluation metrics and by carrying out a human evaluation. The experiments demonstrate that our model improves upon recently proposed models and that the latent variables facilitate the generation of long outputs and maintain the context.