 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Headline Generation with Sentence-wise Optimization
Paper and Code
Oct 09, 2016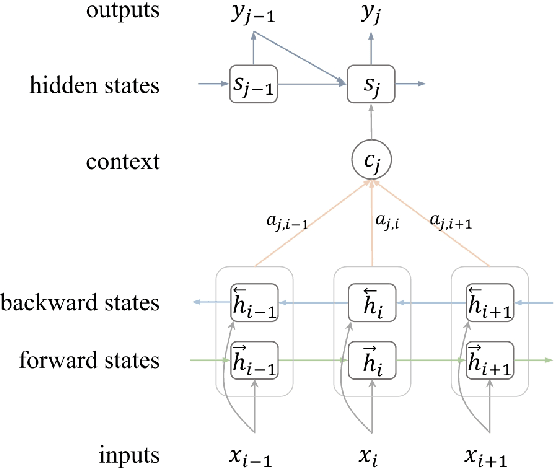
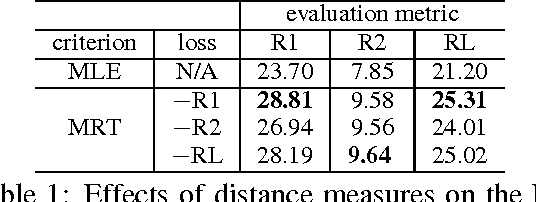
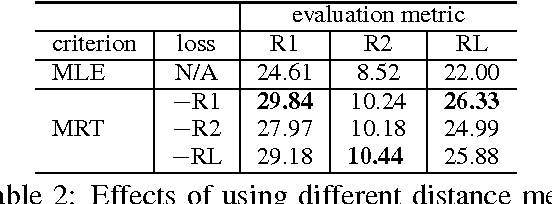
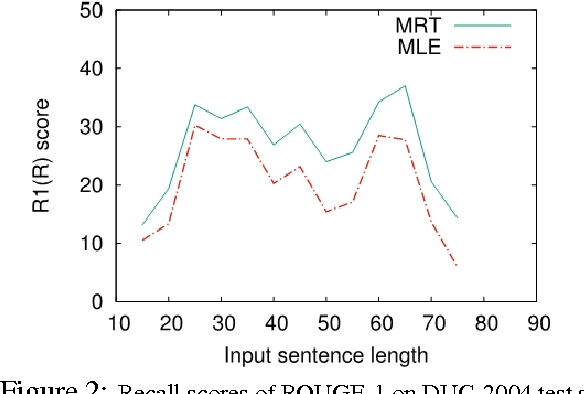
Recently, neural models have been proposed for headline generation by learning to map documents to headlines with recurrent neural networks. Nevertheless, as traditional neural network utilizes maximum likelihood estimation for parameter optimization, it essentially constrains the expected training objective within word level rather than sentence level. Moreover, the performance of model prediction significantly relies on training data distribution. To overcome these drawbacks, we employ minimum risk training strategy in this paper, which directly optimizes model parameters in sentence level with respect to evaluation metrics and leads to significant improvements for headline generation. Experiment results show that our models outperforms state-of-the-art systems on both English and Chinese headline generation tasks.