 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Recurrent Regression for Facial Landmark Detection
Paper and Code
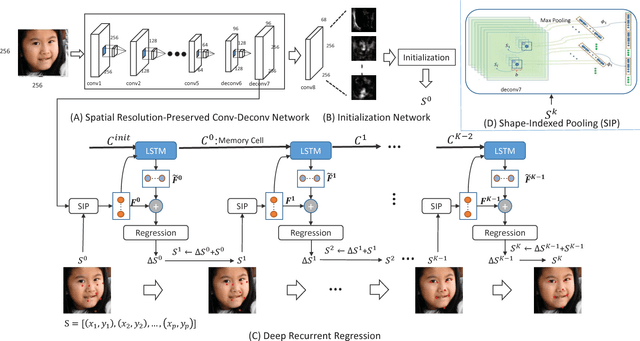
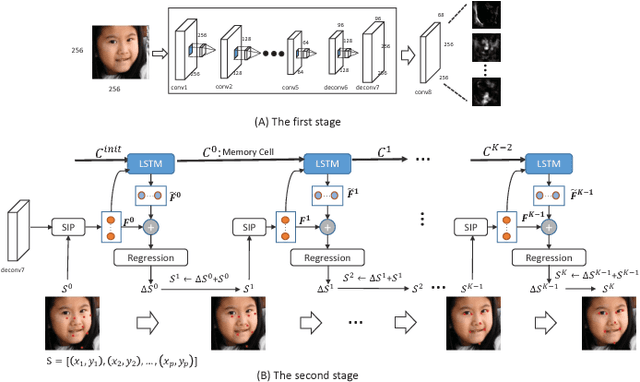
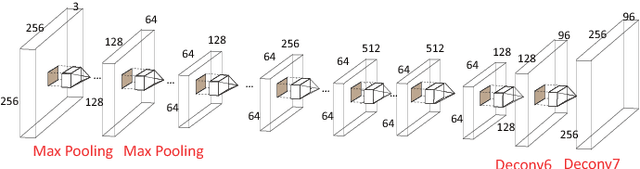
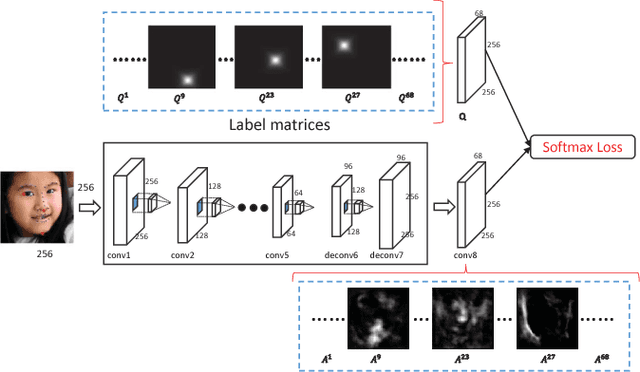
We propose a novel end-to-end deep architecture for face landmark detection, based on a deep convolutional and deconvolutional network followed by carefully designed recurrent network structures. The pipeline of this architecture consists of three parts. Through the first part, we encode an input face image to resolution-preserved deconvolutional feature maps via a deep network with stacked convolutional and deconvolutional layers. Then, in the second part, we estimate the initial coordinates of the facial key points by an additional convolutional layer on top of these deconvolutional feature maps. In the last part, by using the deconvolutional feature maps and the initial facial key points as input, we refine the coordinates of the facial key points by a recurrent network that consists of multiple Long-Short Term Memory (LSTM) components. Extensive evaluations on several benchmark datasets show that the proposed deep architecture has superior performance against the state-of-the-art methods.