 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Object Tracking, Learning and Parsing with And-Or Graphs
Paper and Code


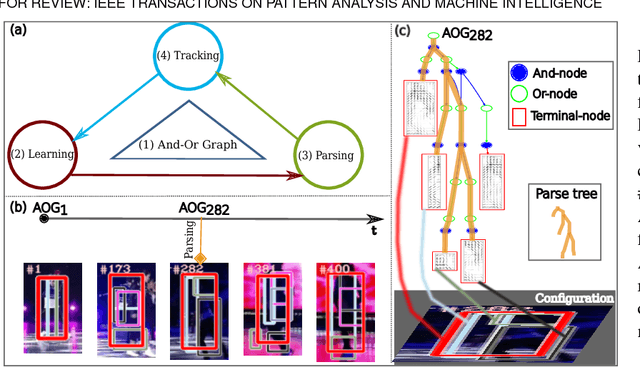
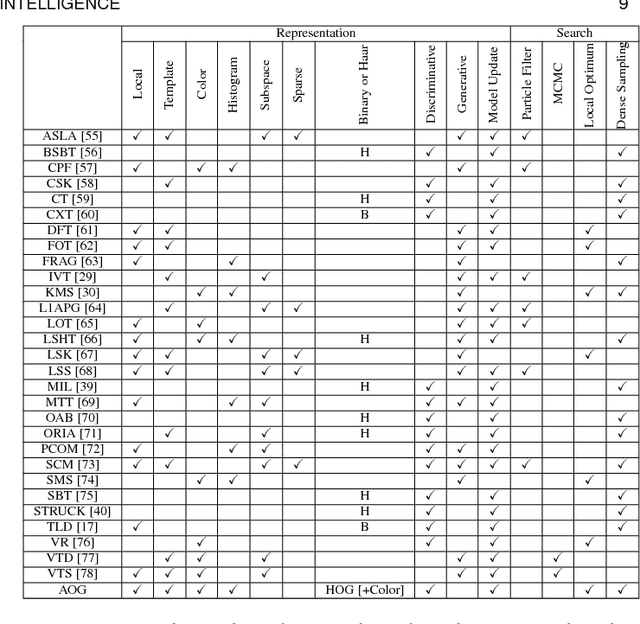
This paper presents a method, called AOGTracker, for simultaneously tracking, learning and parsing (TLP) of unknown objects in video sequences with a hierarchical and compositional And-Or graph (AOG) representation. %The AOG captures both structural and appearance variations of a target object in a principled way. The TLP method is formulated in the Bayesian framework with a spatial and a temporal dynamic programming (DP) algorithms inferring object bounding boxes on-the-fly. During online learning, the AOG is discriminatively learned using latent SVM to account for appearance (e.g., lighting and partial occlusion) and structural (e.g., different poses and viewpoints) variations of a tracked object, as well as distractors (e.g., similar objects) in background. Three key issues in online inference and learning are addressed: (i) maintaining purity of positive and negative examples collected online, (ii) controling model complexity in latent structure learning, and (iii) identifying critical moments to re-learn the structure of AOG based on its intrackability. The intrackability measures uncertainty of an AOG based on its score maps in a frame. In experiments, our AOGTracker is tested on two popular tracking benchmarks with the same parameter setting: the TB-100/50/CVPR2013 benchmarks, and the VOT benchmarks --- VOT 2013, 2014, 2015 and TIR2015 (thermal imagery tracking). In the former, our AOGTracker outperforms state-of-the-art tracking algorithms including two trackers based on deep convolutional network. In the latter, our AOGTracker outperforms all other trackers in VOT2013 and is comparable to the state-of-the-art methods in VOT2014, 2015 and TIR2015.