 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Dialect Detection in Arabic Broadcast Speech
Paper and Code
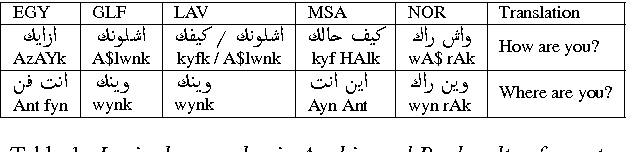
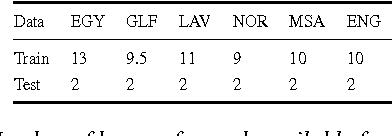

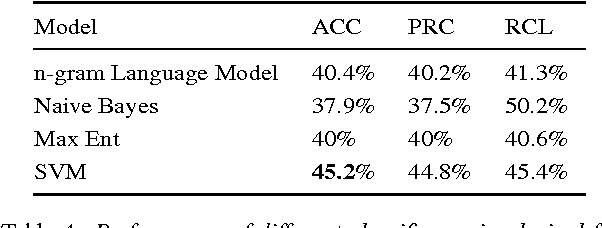
We investigate different approaches for dialect identification in Arabic broadcast speech, using phonetic, lexical features obtained from a speech recognition system, and acoustic features using the i-vector framework. We studied both generative and discriminate classifiers, and we combined these features using a multi-class Support Vector Machine (SVM). We validated our results on an Arabic/English language identification task, with an accuracy of 100%. We used these features in a binary classifier to discriminate between Modern Standard Arabic (MSA) and Dialectal Arabic, with an accuracy of 100%. We further report results using the proposed method to discriminate between the five most widely used dialects of Arabic: namely Egyptian, Gulf, Levantine, North African, and MSA, with an accuracy of 52%. We discuss dialect identification errors in the context of dialect code-switching between Dialectal Arabic and MSA, and compare the error pattern between manually labeled data, and the output from our classifier. We also release the train and test data as standard corpus for dialect identification.