 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Attention-based Large Vocabulary Speech Recognition
Paper and Code
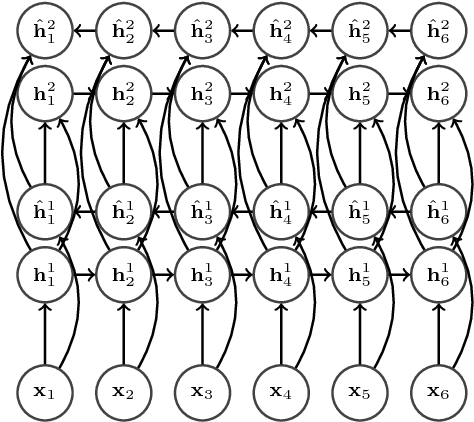
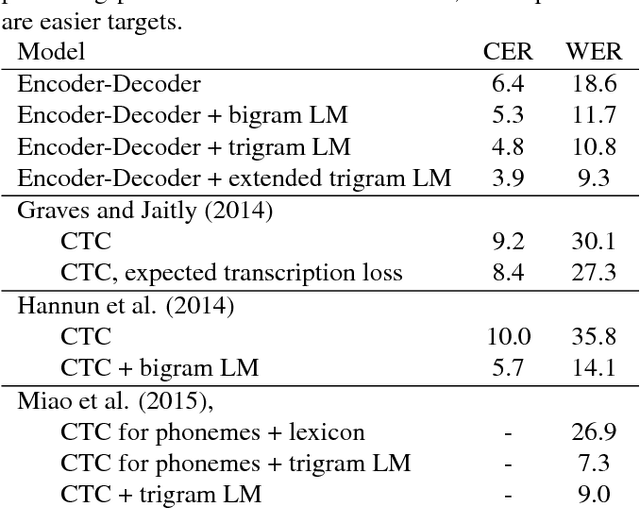
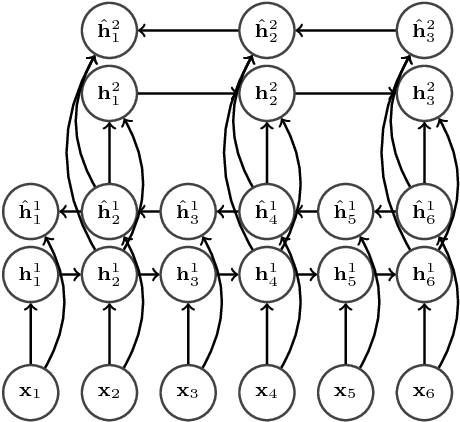
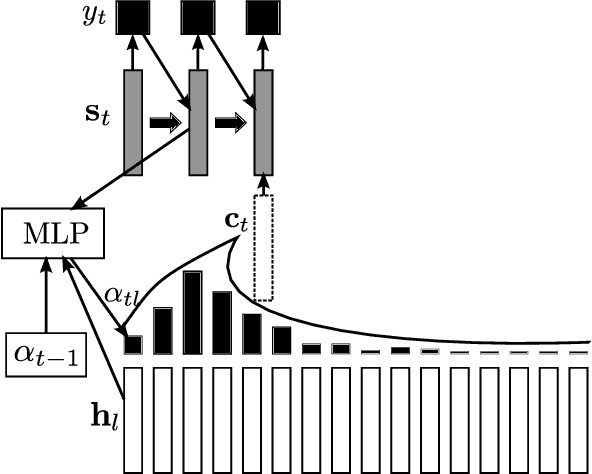
Many of the current state-of-the-art Large Vocabulary Continuous Speech Recognition Systems (LVCSR) are hybrids of neural networks and Hidden Markov Models (HMMs). Most of these systems contain separate components that deal with the acoustic modelling, language modelling and sequence decoding. We investigate a more direct approach in which the HMM is replaced with a Recurrent Neural Network (RNN) that performs sequence prediction directly at the character level. Alignment between the input features and the desired character sequence is learned automatically by an attention mechanism built into the RNN. For each predicted character, the attention mechanism scans the input sequence and chooses relevant frames. We propose two methods to speed up this operation: limiting the scan to a subset of most promising frames and pooling over time the information contained in neighboring frames, thereby reducing source sequence length. Integrating an n-gram language model into the decoding process yields recognition accuracies similar to other HMM-free RNN-based approaches.