 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for the Volumetric Integration of Depth Images
Paper and Code
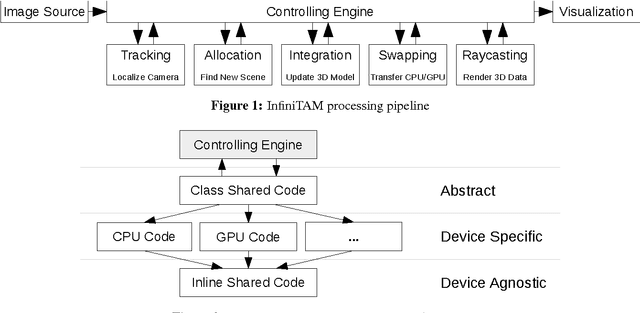
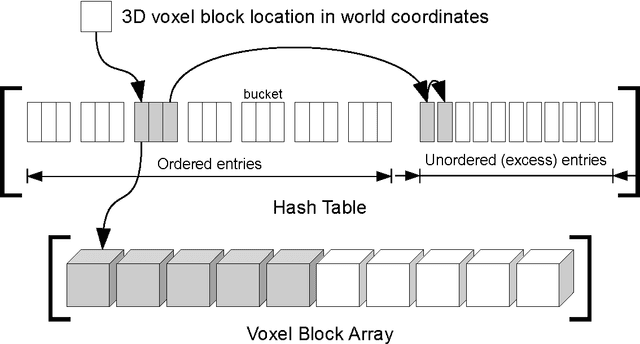
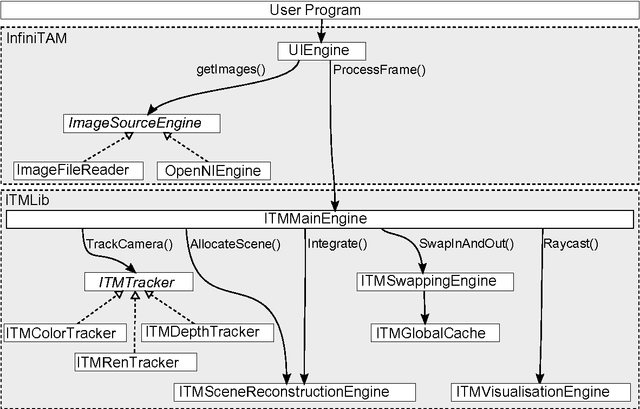
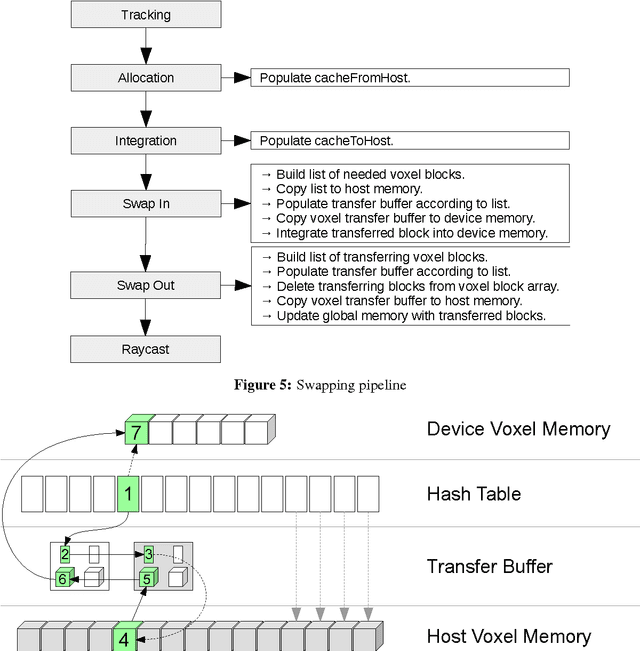
Volumetric models have become a popular representation for 3D scenes in recent years. One of the breakthroughs leading to their popularity was KinectFusion, where the focus is on 3D reconstruction using RGB-D sensors. However, monocular SLAM has since also been tackled with very similar approaches. Representing the reconstruction volumetrically as a truncated signed distance function leads to most of the simplicity and efficiency that can be achieved with GPU implementations of these systems. However, this representation is also memory-intensive and limits the applicability to small scale reconstructions. Several avenues have been explored for overcoming this limitation. With the aim of summarizing them and providing for a fast and flexible 3D reconstruction pipeline, we propose a new, unifying framework called InfiniTAM. The core idea is that individual steps like camera tracking, scene representation and integration of new data can easily be replaced and adapted to the needs of the user. Along with the framework we also provide a set of components for scalable reconstruction: two implementations of camera trackers, based on RGB data and on depth data, two representations of the 3D volumetric data, a dense volume and one based on hashes of subblocks, and an optional module for swapping subblocks in and out of the typically limited GPU memory.