 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Fast Dropout and its Applicability to Recurrent Networks
Paper and Code
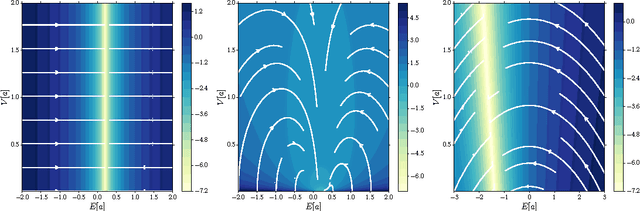
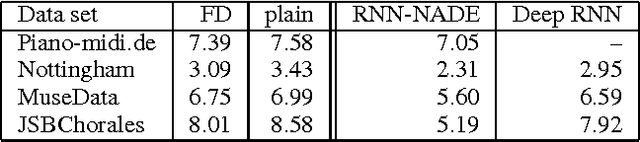
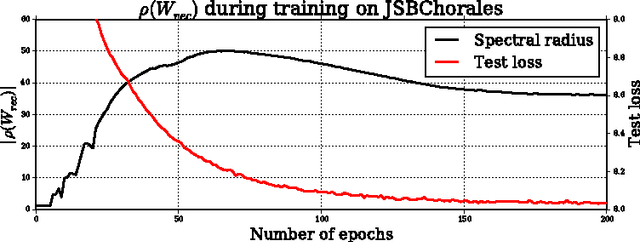

Recurrent Neural Networks (RNNs) are rich models for the processing of sequential data. Recent work on advancing the state of the art has been focused on the optimization or modelling of RNNs, mostly motivated by adressing the problems of the vanishing and exploding gradients. The control of overfitting has seen considerably less attention. This paper contributes to that by analyzing fast dropout, a recent regularization method for generalized linear models and neural networks from a back-propagation inspired perspective. We show that fast dropout implements a quadratic form of an adaptive, per-parameter regularizer, which rewards large weights in the light of underfitting, penalizes them for overconfident predictions and vanishes at minima of an unregularized training loss. The derivatives of that regularizer are exclusively based on the training error signal. One consequence of this is the absense of a global weight attractor, which is particularly appealing for RNNs, since the dynamics are not biased towards a certain regime. We positively test the hypothesis that this improves the performance of RNNs on four musical data sets.