Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering with Transitive Distance and K-Means Duality
Paper and Code
Nov 22, 2007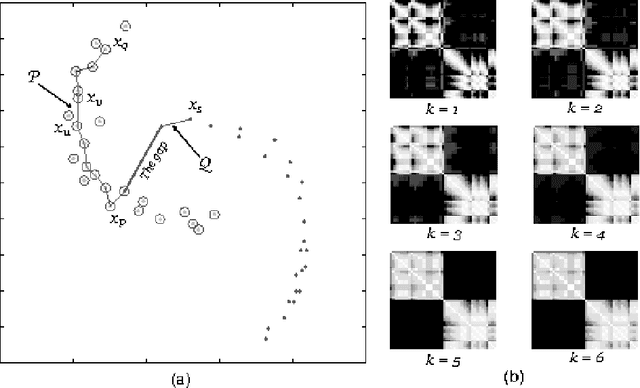

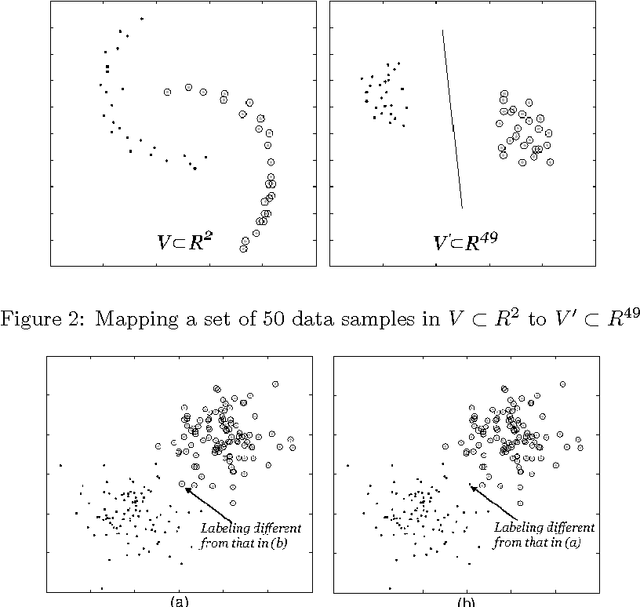
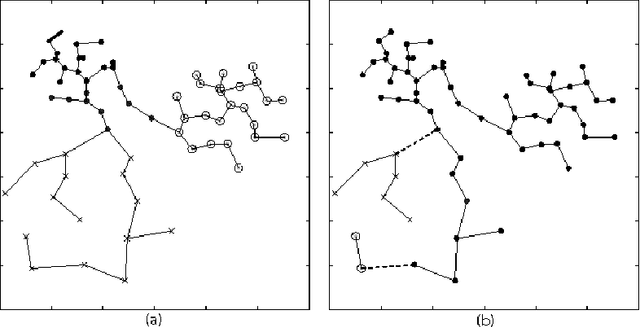
Recent spectral clustering methods are a propular and powerful technique for data clustering. These methods need to solve the eigenproblem whose computational complexity is $O(n^3)$, where $n$ is the number of data samples. In this paper, a non-eigenproblem based clustering method is proposed to deal with the clustering problem. Its performance is comparable to the spectral clustering algorithms but it is more efficient with computational complexity $O(n^2)$. We show that with a transitive distance and an observed property, called K-means duality, our algorithm can be used to handle data sets with complex cluster shapes, multi-scale clusters, and noise. Moreover, no parameters except the number of clusters need to be set in our algorithm.
* 13 pages, 6 figures
View paper on