 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeErgodic Measure Preserving Flows
Aug 13, 2018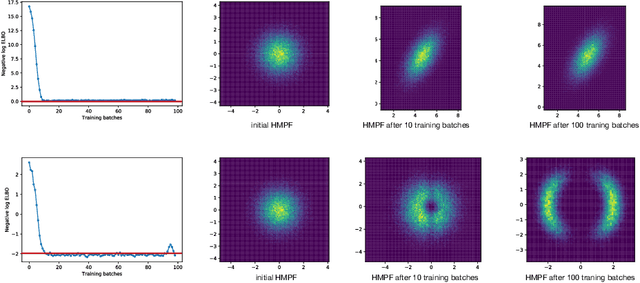
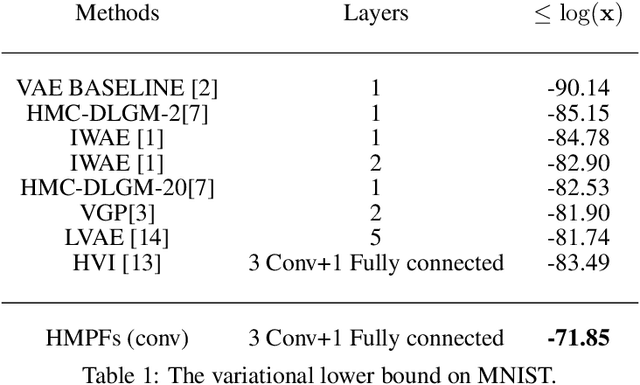
Probabilistic modelling is a general and elegant framework to capture the uncertainty, ambiguity and diversity of data. Probabilistic inference is the core technique for developing training and simulation algorithms on probabilistic models. However, the classic inference methods, like Markov chain Monte Carlo (MCMC) methods and mean-field variational inference (VI), are not computationally scalable for the recent developed probabilistic models with neural networks (NNs). This motivates many recent works on improving classic inference methods using NNs, especially, NN empowered VI. However, even with powerful NNs, VI still suffers its fundamental limitations. In this work, we propose a novel computational scalable general inference framework. With the theoretical foundation in ergodic theory, the proposed methods are not only computationally scalable like NN-based VI methods but also asymptotically accurate like MCMC. We test our method on popular benchmark problems and the results suggest that our methods can outperform NN-based VI and MCMC on deep generative models and Bayesian neural networks.
Antithetic and Monte Carlo kernel estimators for partial rankings
Jul 25, 2018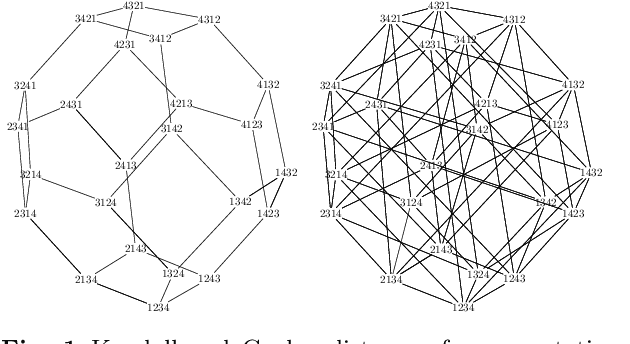
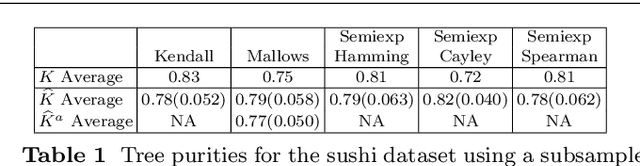
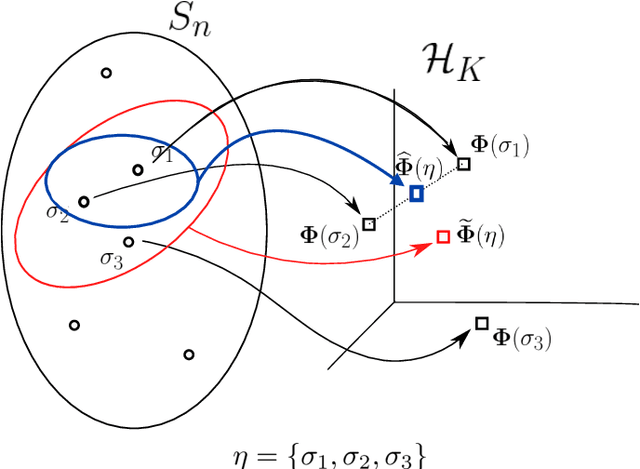
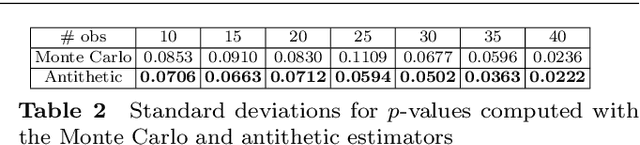
In the modern age, rankings data is ubiquitous and it is useful for a variety of applications such as recommender systems, multi-object tracking and preference learning. However, most rankings data encountered in the real world is incomplete, which prevents the direct application of existing modelling tools for complete rankings. Our contribution is a novel way to extend kernel methods for complete rankings to partial rankings, via consistent Monte Carlo estimators for Gram matrices: matrices of kernel values between pairs of observations. We also present a novel variance reduction scheme based on an antithetic variate construction between permutations to obtain an improved estimator for the Mallows kernel. The corresponding antithetic kernel estimator has lower variance and we demonstrate empirically that it has a better performance in a variety of Machine Learning tasks. Both kernel estimators are based on extending kernel mean embeddings to the embedding of a set of full rankings consistent with an observed partial ranking. They form a computationally tractable alternative to previous approaches for partial rankings data. An overview of the existing kernels and metrics for permutations is also provided.
Few-shot learning of neural networks from scratch by pseudo example optimization
Jul 05, 2018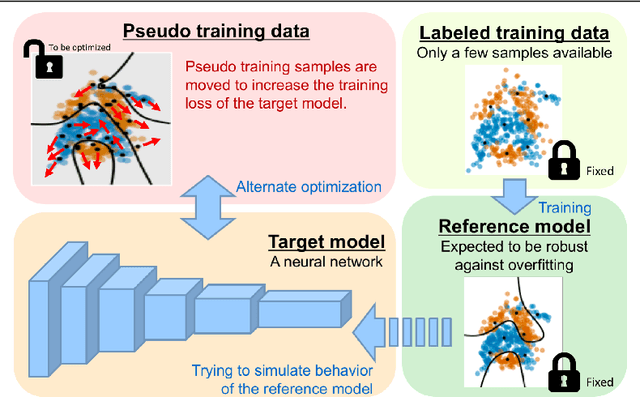
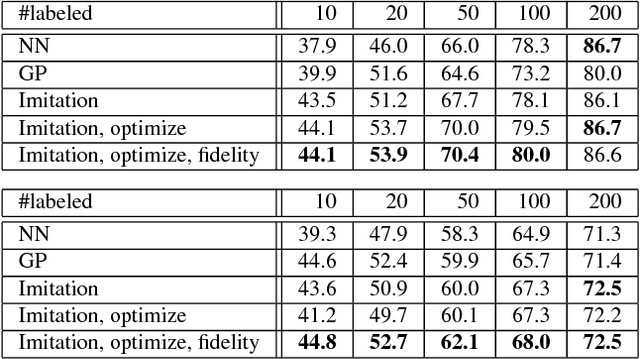
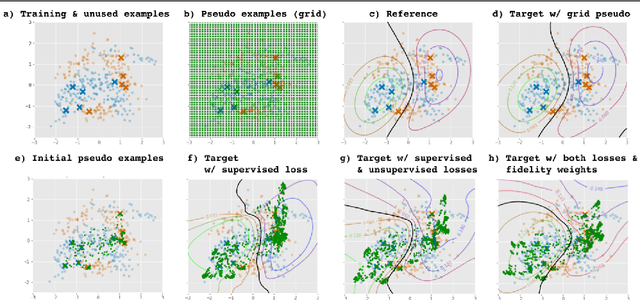
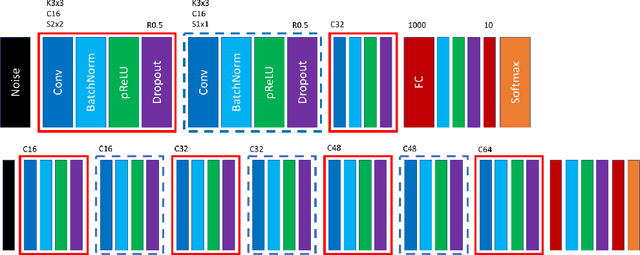
In this paper, we propose a simple but effective method for training neural networks with a limited amount of training data. Our approach inherits the idea of knowledge distillation that transfers knowledge from a deep or wide reference model to a shallow or narrow target model. The proposed method employs this idea to mimic predictions of reference estimators that are more robust against overfitting than the network we want to train. Different from almost all the previous work for knowledge distillation that requires a large amount of labeled training data, the proposed method requires only a small amount of training data. Instead, we introduce pseudo training examples that are optimized as a part of model parameters. Experimental results for several benchmark datasets demonstrate that the proposed method outperformed all the other baselines, such as naive training of the target model and standard knowledge distillation.
Variational Bayesian dropout: pitfalls and fixes
Jul 05, 2018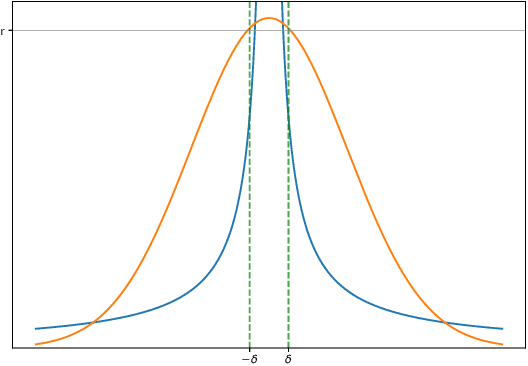
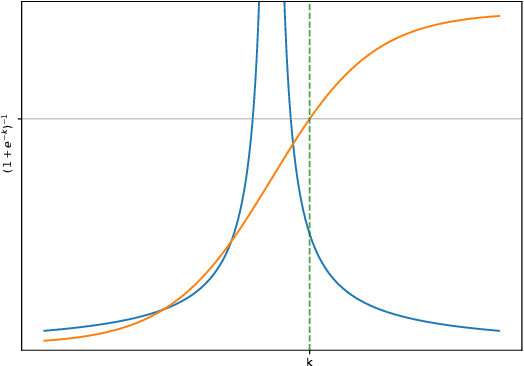
Dropout, a stochastic regularisation technique for training of neural networks, has recently been reinterpreted as a specific type of approximate inference algorithm for Bayesian neural networks. The main contribution of the reinterpretation is in providing a theoretical framework useful for analysing and extending the algorithm. We show that the proposed framework suffers from several issues; from undefined or pathological behaviour of the true posterior related to use of improper priors, to an ill-defined variational objective due to singularity of the approximating distribution relative to the true posterior. Our analysis of the improper log uniform prior used in variational Gaussian dropout suggests the pathologies are generally irredeemable, and that the algorithm still works only because the variational formulation annuls some of the pathologies. To address the singularity issue, we proffer Quasi-KL (QKL) divergence, a new approximate inference objective for approximation of high-dimensional distributions. We show that motivations for variational Bernoulli dropout based on discretisation and noise have QKL as a limit. Properties of QKL are studied both theoretically and on a simple practical example which shows that the QKL-optimal approximation of a full rank Gaussian with a degenerate one naturally leads to the Principal Component Analysis solution.
Probabilistic Deep Learning using Random Sum-Product Networks
Jun 22, 2018
The need for consistent treatment of uncertainty has recently triggered increased interest in probabilistic deep learning methods. However, most current approaches have severe limitations when it comes to inference, since many of these models do not even permit to evaluate exact data likelihoods. Sum-product networks (SPNs), on the other hand, are an excellent architecture in that regard, as they allow to efficiently evaluate likelihoods, as well as arbitrary marginalization and conditioning tasks. Nevertheless, SPNs have not been fully explored as serious deep learning models, likely due to their special structural requirements, which complicate learning. In this paper, we make a drastic simplification and use random SPN structures which are trained in a "classical deep learning manner", i.e. employing automatic differentiation, SGD, and GPU support. The resulting models, called RAT-SPNs, yield prediction results comparable to deep neural networks, while still being interpretable as generative model and maintaining well-calibrated uncertainties. This property makes them highly robust under missing input features and enables them to naturally detect outliers and peculiar samples.
The Mirage of Action-Dependent Baselines in Reinforcement Learning
Apr 06, 2018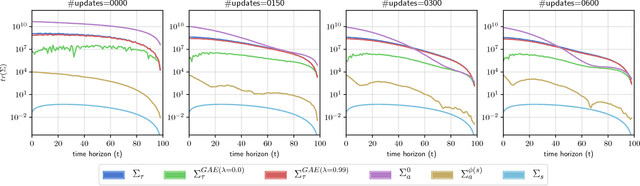
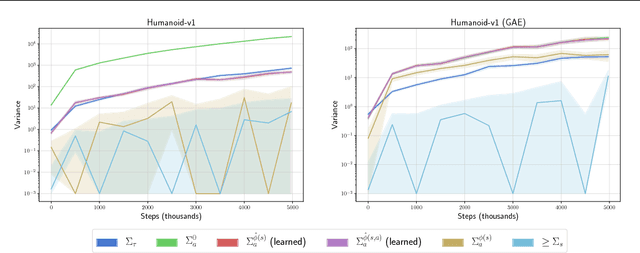
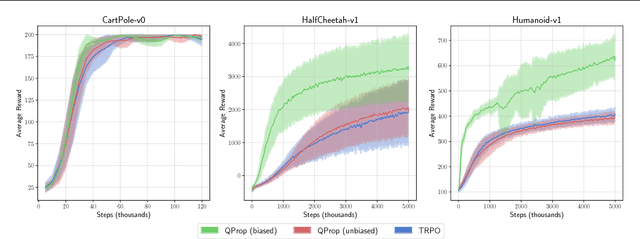
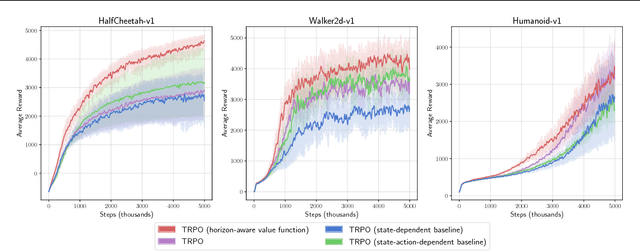
Policy gradient methods are a widely used class of model-free reinforcement learning algorithms where a state-dependent baseline is used to reduce gradient estimator variance. Several recent papers extend the baseline to depend on both the state and action and suggest that this significantly reduces variance and improves sample efficiency without introducing bias into the gradient estimates. To better understand this development, we decompose the variance of the policy gradient estimator and numerically show that learned state-action-dependent baselines do not in fact reduce variance over a state-dependent baseline in commonly tested benchmark domains. We confirm this unexpected result by reviewing the open-source code accompanying these prior papers, and show that subtle implementation decisions cause deviations from the methods presented in the papers and explain the source of the previously observed empirical gains. Furthermore, the variance decomposition highlights areas for improvement, which we demonstrate by illustrating a simple change to the typical value function parameterization that can significantly improve performance.
General Latent Feature Models for Heterogeneous Datasets
Mar 08, 2018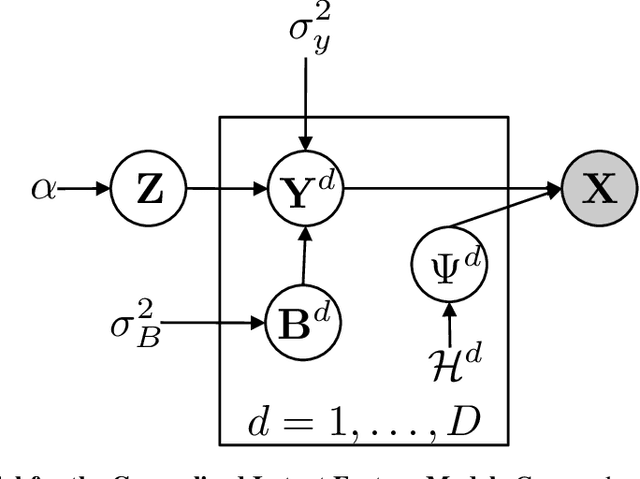
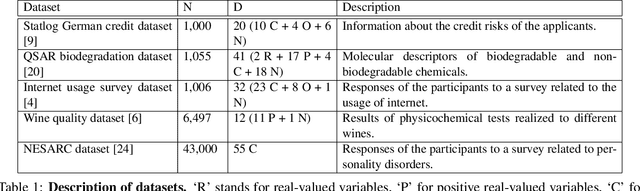
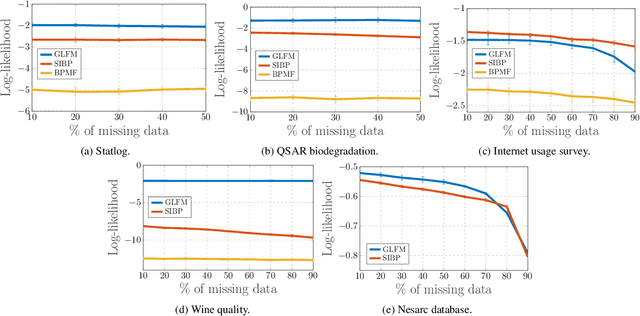

Latent feature modeling allows capturing the latent structure responsible for generating the observed properties of a set of objects. It is often used to make predictions either for new values of interest or missing information in the original data, as well as to perform data exploratory analysis. However, although there is an extensive literature on latent feature models for homogeneous datasets, where all the attributes that describe each object are of the same (continuous or discrete) nature, there is a lack of work on latent feature modeling for heterogeneous databases. In this paper, we introduce a general Bayesian nonparametric latent feature model suitable for heterogeneous datasets, where the attributes describing each object can be either discrete, continuous or mixed variables. The proposed model presents several important properties. First, it accounts for heterogeneous data while keeping the properties of conjugate models, which allow us to infer the model in linear time with respect to the number of objects and attributes. Second, its Bayesian nonparametric nature allows us to automatically infer the model complexity from the data, i.e., the number of features necessary to capture the latent structure in the data. Third, the latent features in the model are binary-valued variables, easing the interpretability of the obtained latent features in data exploratory analysis. We show the flexibility of the proposed model by solving both prediction and data analysis tasks on several real-world datasets. Moreover, a software package of the GLFM is publicly available for other researcher to use and improve it.
Weakly supervised collective feature learning from curated media
Feb 13, 2018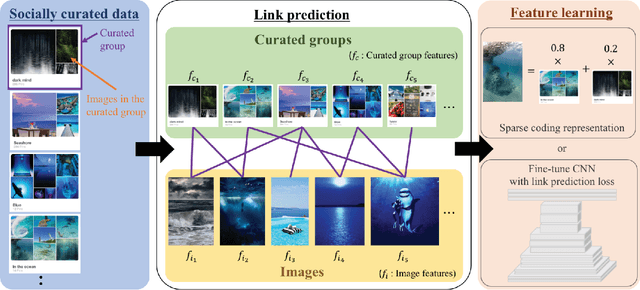
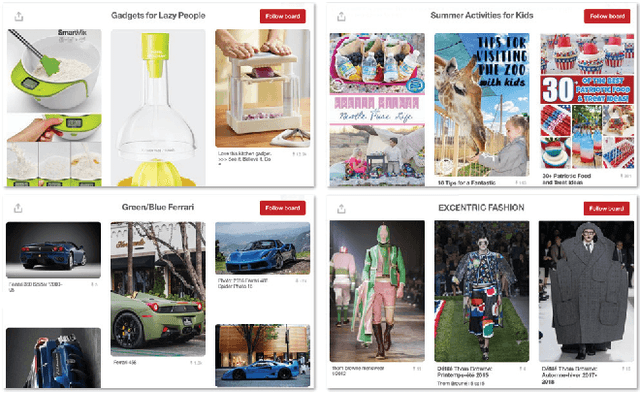

The current state-of-the-art in feature learning relies on the supervised learning of large-scale datasets consisting of target content items and their respective category labels. However, constructing such large-scale fully-labeled datasets generally requires painstaking manual effort. One possible solution to this problem is to employ community contributed text tags as weak labels, however, the concepts underlying a single text tag strongly depends on the users. We instead present a new paradigm for learning discriminative features by making full use of the human curation process on social networking services (SNSs). During the process of content curation, SNS users collect content items manually from various sources and group them by context, all for their own benefit. Due to the nature of this process, we can assume that (1) content items in the same group share the same semantic concept and (2) groups sharing the same images might have related semantic concepts. Through these insights, we can define human curated groups as weak labels from which our proposed framework can learn discriminative features as a representation in the space of semantic concepts the users intended when creating the groups. We show that this feature learning can be formulated as a problem of link prediction for a bipartite graph whose nodes corresponds to content items and human curated groups, and propose a novel method for feature learning based on sparse coding or network fine-tuning.
Variational Gaussian Dropout is not Bayesian
Nov 08, 2017Gaussian multiplicative noise is commonly used as a stochastic regularisation technique in training of deterministic neural networks. A recent paper reinterpreted the technique as a specific algorithm for approximate inference in Bayesian neural networks; several extensions ensued. We show that the log-uniform prior used in all the above publications does not generally induce a proper posterior, and thus Bayesian inference in such models is ill-posed. Independent of the log-uniform prior, the correlated weight noise approximation has further issues leading to either infinite objective or high risk of overfitting. The above implies that the reported sparsity of obtained solutions cannot be explained by Bayesian or the related minimum description length arguments. We thus study the objective from a non-Bayesian perspective, provide its previously unknown analytical form which allows exact gradient evaluation, and show that the later proposed additive reparametrisation introduces minima not present in the original multiplicative parametrisation. Implications and future research directions are discussed.
Magnetic Hamiltonian Monte Carlo
Aug 19, 2017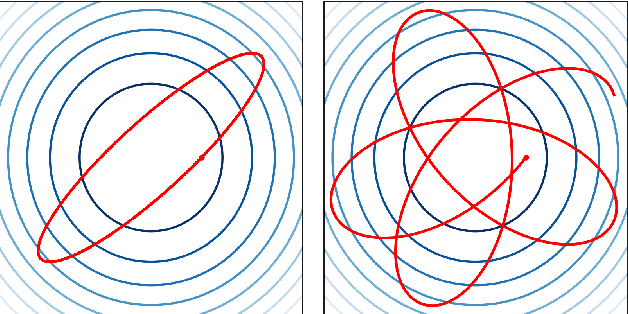


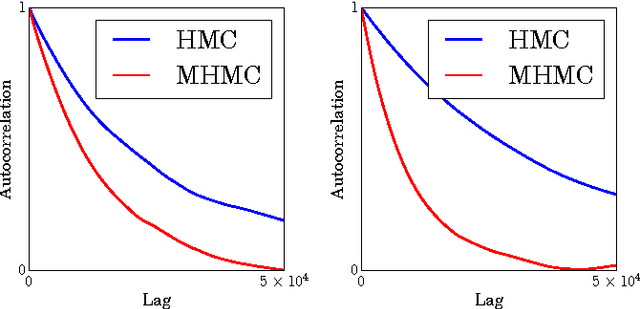
Hamiltonian Monte Carlo (HMC) exploits Hamiltonian dynamics to construct efficient proposals for Markov chain Monte Carlo (MCMC). In this paper, we present a generalization of HMC which exploits \textit{non-canonical} Hamiltonian dynamics. We refer to this algorithm as magnetic HMC, since in 3 dimensions a subset of the dynamics map onto the mechanics of a charged particle coupled to a magnetic field. We establish a theoretical basis for the use of non-canonical Hamiltonian dynamics in MCMC, and construct a symplectic, leapfrog-like integrator allowing for the implementation of magnetic HMC. Finally, we exhibit several examples where these non-canonical dynamics can lead to improved mixing of magnetic HMC relative to ordinary HMC.