 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplit the Differences, Pool the Rest: Provably Efficient Multi-Objective Imitation
May 12, 2026This work investigates multi-objective imitation learning: the problem of recovering policies that lie on the Pareto front given demonstrations from multiple Pareto-optimal experts in a Multi-Objective Markov Decision Process (MOMDP). Standard imitation approaches are ill-equipped for this regime, as naively aggregating conflicting expert trajectories can result in dominated policies. To address this, we introduce Multi-Output Augmented Behavioral Cloning (MA-BC), an algorithm that systematically partitions divergent expert data while pooling state-action pairs where no behavior conflict is observed. Theoretically, we prove that MA-BC converges to Pareto-optimal policies at a faster statistical rate than any learner that considers each expert dataset independently. Furthermore, we establish a novel lower bound for multi-objective imitation learning, demonstrating that MA-BC is minimax optimal. Finally, we empirically validate our algorithm across diverse discrete environments and, guided by our theoretical insights, extend and evaluate MA-BC on a continuous Linear Quadratic Regulator (LQR) control task.
Efficient Personalization of Generative Models via Optimal Experimental Design
Dec 22, 2025Preference learning from human feedback has the ability to align generative models with the needs of end-users. Human feedback is costly and time-consuming to obtain, which creates demand for data-efficient query selection methods. This work presents a novel approach that leverages optimal experimental design to ask humans the most informative preference queries, from which we can elucidate the latent reward function modeling user preferences efficiently. We formulate the problem of preference query selection as the one that maximizes the information about the underlying latent preference model. We show that this problem has a convex optimization formulation, and introduce a statistically and computationally efficient algorithm ED-PBRL that is supported by theoretical guarantees and can efficiently construct structured queries such as images or text. We empirically present the proposed framework by personalizing a text-to-image generative model to user-specific styles, showing that it requires less preference queries compared to random query selection.
Quantization-Free Autoregressive Action Transformer
Mar 18, 2025



Current transformer-based imitation learning approaches introduce discrete action representations and train an autoregressive transformer decoder on the resulting latent code. However, the initial quantization breaks the continuous structure of the action space thereby limiting the capabilities of the generative model. We propose a quantization-free method instead that leverages Generative Infinite-Vocabulary Transformers (GIVT) as a direct, continuous policy parametrization for autoregressive transformers. This simplifies the imitation learning pipeline while achieving state-of-the-art performance on a variety of popular simulated robotics tasks. We enhance our policy roll-outs by carefully studying sampling algorithms, further improving the results.
Safe Deep Reinforcement Learning for Multi-Agent Systems with Continuous Action Spaces
Aug 11, 2021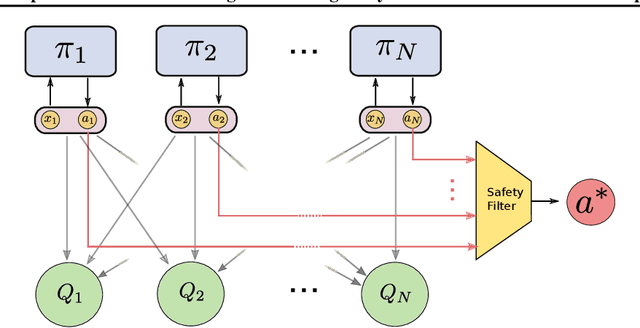
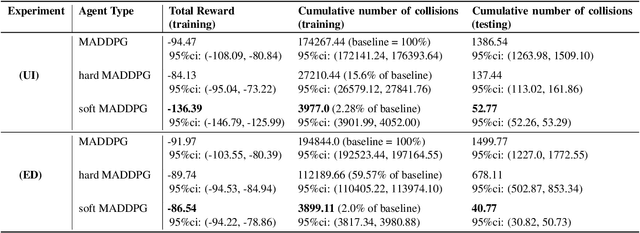
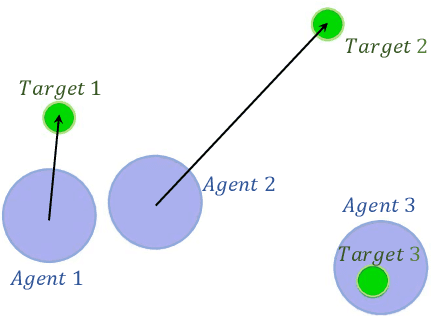

Multi-agent control problems constitute an interesting area of application for deep reinforcement learning models with continuous action spaces. Such real-world applications, however, typically come with critical safety constraints that must not be violated. In order to ensure safety, we enhance the well-known multi-agent deep deterministic policy gradient (MADDPG) framework by adding a safety layer to the deep policy network. In particular, we extend the idea of linearizing the single-step transition dynamics, as was done for single-agent systems in Safe DDPG (Dalal et al., 2018), to multi-agent settings. We additionally propose to circumvent infeasibility problems in the action correction step using soft constraints (Kerrigan & Maciejowski, 2000). Results from the theory of exact penalty functions can be used to guarantee constraint satisfaction of the soft constraints under mild assumptions. We empirically find that the soft formulation achieves a dramatic decrease in constraint violations, making safety available even during the learning procedure.