 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance-Aware Self-Configurable Multi-Agent Networks: A Distributed Submodular Approach for Simultaneous Coordination and Network Design
Sep 02, 2024
We introduce the first, to our knowledge, rigorous approach that enables multi-agent networks to self-configure their communication topology to balance the trade-off between scalability and optimality during multi-agent planning. We are motivated by the future of ubiquitous collaborative autonomy where numerous distributed agents will be coordinating via agent-to-agent communication to execute complex tasks such as traffic monitoring, event detection, and environmental exploration. But the explosion of information in such large-scale networks currently curtails their deployment due to impractical decision times induced by the computational and communication requirements of the existing near-optimal coordination algorithms. To overcome this challenge, we present the AlterNAting COordination and Network-Design Algorithm (Anaconda), a scalable algorithm that also enjoys near-optimality guarantees. Subject to the agents' bandwidth constraints, Anaconda enables the agents to optimize their local communication neighborhoods such that the action-coordination approximation performance of the network is maximized. Compared to the state of the art, Anaconda is an anytime self-configurable algorithm that quantifies its suboptimality guarantee for any type of network, from fully disconnected to fully centralized, and that, for sparse networks, is one order faster in terms of decision speed. To develop the algorithm, we quantify the suboptimality cost due to decentralization, i.e., due to communication-minimal distributed coordination. We also employ tools inspired by the literature on multi-armed bandits and submodular maximization subject to cardinality constraints. We demonstrate Anaconda in simulated scenarios of area monitoring and compare it with a state-of-the-art algorithm.
Communication- and Computation-Efficient Distributed Decision-Making in Multi-Robot Networks
Jul 15, 2024



We provide a distributed coordination paradigm that enables scalable and near-optimal joint motion planning among multiple robots. Our coordination paradigm contrasts with current paradigms that are either near-optimal but impractical for replanning times or real-time but offer no near-optimality guarantees. We are motivated by the future of collaborative mobile autonomy, where distributed teams of robots will coordinate via vehicle-to-vehicle (v2v) communication to execute information-heavy tasks like mapping, surveillance, and target tracking. To enable rapid distributed coordination, we must curtail the explosion of information-sharing across the network, thus limiting robot coordination. However, this can lead to suboptimal plans, causing overlapping trajectories instead of complementary ones. We make theoretical and algorithmic contributions to balance the trade-off between decision speed and optimality. We introduce tools for distributed submodular optimization, a diminishing returns property in information-gathering tasks. Theoretically, we analyze how local network topology affects near-optimality at the global level. Algorithmically, we provide a communication- and computation-efficient coordination algorithm for agents to balance the trade-off. Our algorithm is up to two orders faster than competitive near-optimal algorithms. In simulations of surveillance tasks with up to 45 robots, it enables real-time planning at the order of 1 Hz with superior coverage performance. To enable the simulations, we provide a high-fidelity simulator that extends AirSim by integrating a collaborative autonomy pipeline and simulating v2v communication delays.
Infinite-Dimensional Feature Interaction
May 22, 2024



The past neural network design has largely focused on feature representation space dimension and its capacity scaling (e.g., width, depth), but overlooked the feature interaction space scaling. Recent advancements have shown shifted focus towards element-wise multiplication to facilitate higher-dimensional feature interaction space for better information transformation. Despite this progress, multiplications predominantly capture low-order interactions, thus remaining confined to a finite-dimensional interaction space. To transcend this limitation, classic kernel methods emerge as a promising solution to engage features in an infinite-dimensional space. We introduce InfiNet, a model architecture that enables feature interaction within an infinite-dimensional space created by RBF kernel. Our experiments reveal that InfiNet achieves new state-of-the-art, owing to its capability to leverage infinite-dimensional interactions, significantly enhancing model performance.
Out-of-Distribution Detection via Deep Multi-Comprehension Ensemble
Mar 24, 2024



Recent research underscores the pivotal role of the Out-of-Distribution (OOD) feature representation field scale in determining the efficacy of models in OOD detection. Consequently, the adoption of model ensembles has emerged as a prominent strategy to augment this feature representation field, capitalizing on anticipated model diversity. However, our introduction of novel qualitative and quantitative model ensemble evaluation methods, specifically Loss Basin/Barrier Visualization and the Self-Coupling Index, reveals a critical drawback in existing ensemble methods. We find that these methods incorporate weights that are affine-transformable, exhibiting limited variability and thus failing to achieve the desired diversity in feature representation. To address this limitation, we elevate the dimensions of traditional model ensembles, incorporating various factors such as different weight initializations, data holdout, etc., into distinct supervision tasks. This innovative approach, termed Multi-Comprehension (MC) Ensemble, leverages diverse training tasks to generate distinct comprehensions of the data and labels, thereby extending the feature representation field. Our experimental results demonstrate the superior performance of the MC Ensemble strategy in OOD detection compared to both the naive Deep Ensemble method and a standalone model of comparable size. This underscores the effectiveness of our proposed approach in enhancing the model's capability to detect instances outside its training distribution.
QuadraNet: Improving High-Order Neural Interaction Efficiency with Hardware-Aware Quadratic Neural Networks
Nov 29, 2023Recent progress in computer vision-oriented neural network designs is mostly driven by capturing high-order neural interactions among inputs and features. And there emerged a variety of approaches to accomplish this, such as Transformers and its variants. However, these interactions generate a large amount of intermediate state and/or strong data dependency, leading to considerable memory consumption and computing cost, and therefore compromising the overall runtime performance. To address this challenge, we rethink the high-order interactive neural network design with a quadratic computing approach. Specifically, we propose QuadraNet -- a comprehensive model design methodology from neuron reconstruction to structural block and eventually to the overall neural network implementation. Leveraging quadratic neurons' intrinsic high-order advantages and dedicated computation optimization schemes, QuadraNet could effectively achieve optimal cognition and computation performance. Incorporating state-of-the-art hardware-aware neural architecture search and system integration techniques, QuadraNet could also be well generalized in different hardware constraint settings and deployment scenarios. The experiment shows thatQuadraNet achieves up to 1.5$\times$ throughput, 30% less memory footprint, and similar cognition performance, compared with the state-of-the-art high-order approaches.
Leveraging Untrustworthy Commands for Multi-Robot Coordination in Unpredictable Environments: A Bandit Submodular Maximization Approach
Sep 28, 2023



We study the problem of multi-agent coordination in unpredictable and partially-observable environments with untrustworthy external commands. The commands are actions suggested to the robots, and are untrustworthy in that their performance guarantees, if any, are unknown. Such commands may be generated by human operators or machine learning algorithms and, although untrustworthy, can often increase the robots' performance in complex multi-robot tasks. We are motivated by complex multi-robot tasks such as target tracking, environmental mapping, and area monitoring. Such tasks are often modeled as submodular maximization problems due to the information overlap among the robots. We provide an algorithm, Meta Bandit Sequential Greedy (MetaBSG), which enjoys performance guarantees even when the external commands are arbitrarily bad. MetaBSG leverages a meta-algorithm to learn whether the robots should follow the commands or a recently developed submodular coordination algorithm, Bandit Sequential Greedy (BSG) [1], which has performance guarantees even in unpredictable and partially-observable environments. Particularly, MetaBSG asymptotically can achieve the better performance out of the commands and the BSG algorithm, quantifying its suboptimality against the optimal time-varying multi-robot actions in hindsight. Thus, MetaBSG can be interpreted as robustifying the untrustworthy commands. We validate our algorithm in simulated scenarios of multi-target tracking.
Bandit Submodular Maximization for Multi-Robot Coordination in Unpredictable and Partially Observable Environments
May 26, 2023



We study the problem of multi-agent coordination in unpredictable and partially observable environments, that is, environments whose future evolution is unknown a priori and that can only be partially observed. We are motivated by the future of autonomy that involves multiple robots coordinating actions in dynamic, unstructured, and partially observable environments to complete complex tasks such as target tracking, environmental mapping, and area monitoring. Such tasks are often modeled as submodular maximization coordination problems due to the information overlap among the robots. We introduce the first submodular coordination algorithm with bandit feedback and bounded tracking regret -- bandit feedback is the robots' ability to compute in hindsight only the effect of their chosen actions, instead of all the alternative actions that they could have chosen instead, due to the partial observability; and tracking regret is the algorithm's suboptimality with respect to the optimal time-varying actions that fully know the future a priori. The bound gracefully degrades with the environments' capacity to change adversarially, quantifying how often the robots should re-select actions to learn to coordinate as if they fully knew the future a priori. The algorithm generalizes the seminal Sequential Greedy algorithm by Fisher et al. to the bandit setting, by leveraging submodularity and algorithms for the problem of tracking the best action. We validate our algorithm in simulated scenarios of multi-target tracking.
Efficient Online Learning with Memory via Frank-Wolfe Optimization: Algorithms with Bounded Dynamic Regret and Applications to Control
Jan 02, 2023


Projection operations are a typical computation bottleneck in online learning. In this paper, we enable projection-free online learning within the framework of Online Convex Optimization with Memory (OCO-M) -- OCO-M captures how the history of decisions affects the current outcome by allowing the online learning loss functions to depend on both current and past decisions. Particularly, we introduce the first projection-free meta-base learning algorithm with memory that minimizes dynamic regret, i.e., that minimizes the suboptimality against any sequence of time-varying decisions. We are motivated by artificial intelligence applications where autonomous agents need to adapt to time-varying environments in real-time, accounting for how past decisions affect the present. Examples of such applications are: online control of dynamical systems; statistical arbitrage; and time series prediction. The algorithm builds on the Online Frank-Wolfe (OFW) and Hedge algorithms. We demonstrate how our algorithm can be applied to the online control of linear time-varying systems in the presence of unpredictable process noise. To this end, we develop the first controller with memory and bounded dynamic regret against any optimal time-varying linear feedback control policy. We validate our algorithm in simulated scenarios of online control of linear time-invariant systems.
Online Submodular Coordination with Bounded Tracking Regret: Theory, Algorithm, and Applications to Multi-Robot Coordination
Sep 26, 2022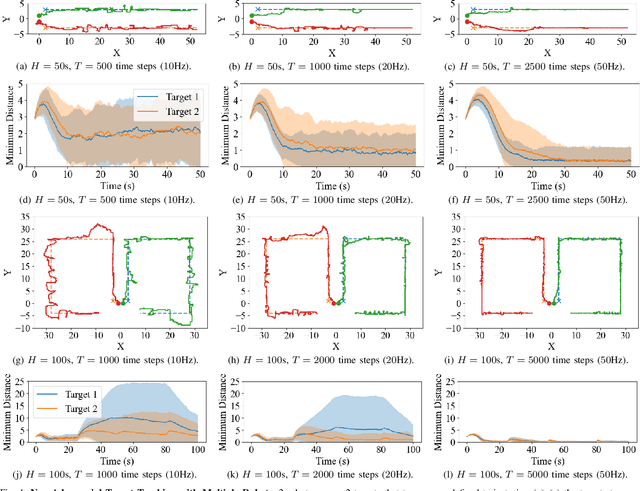
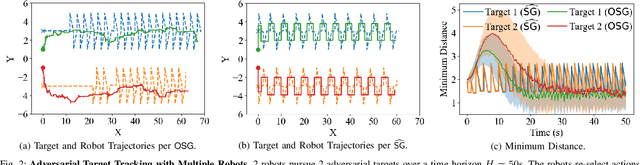
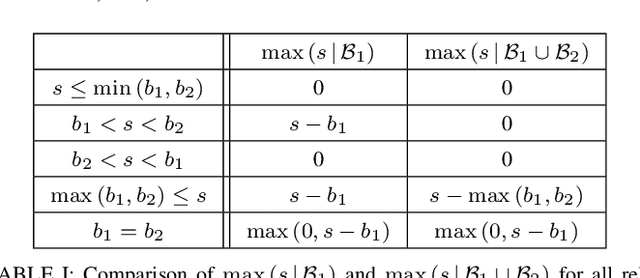
We enable efficient and effective coordination in unpredictable environments, ie., in environments whose future evolution is unknown a priori and even adversarial. We are motivated by the future of autonomy that involves multiple robots coordinating in dynamic, unstructured, and adversarial environments to complete complex tasks such as target tracking, image covering, and area monitoring. Such tasks are often modeled as submodular maximization coordination problems. We thus introduce the first submodular coordination algorithm with bounded tracking regret, ie., with bounded suboptimality with respect to optimal time-varying actions that know the future a priori. The bound gracefully degrades with the environments' capacity to change adversarially. It also quantifies how often the robots must re-select actions to "learn" to coordinate as if they knew the future a priori. Our algorithm generalizes the seminal Sequential Greedy algorithm by Fisher et al. to unpredictable environments, leveraging submodularity and algorithms for the problem of tracking the best expert. We validate our algorithm in simulated scenarios of target tracking.
Resource-Aware Distributed Submodular Maximization: A Paradigm for Multi-Robot Decision-Making
Apr 15, 2022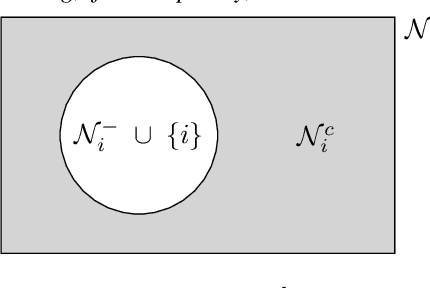
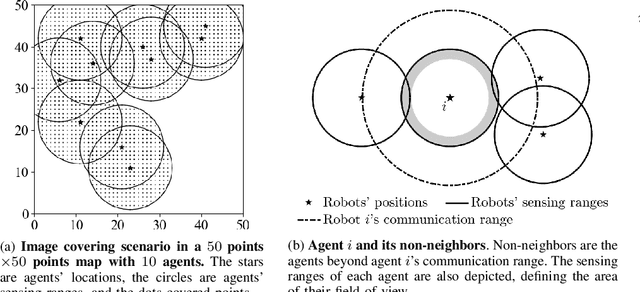
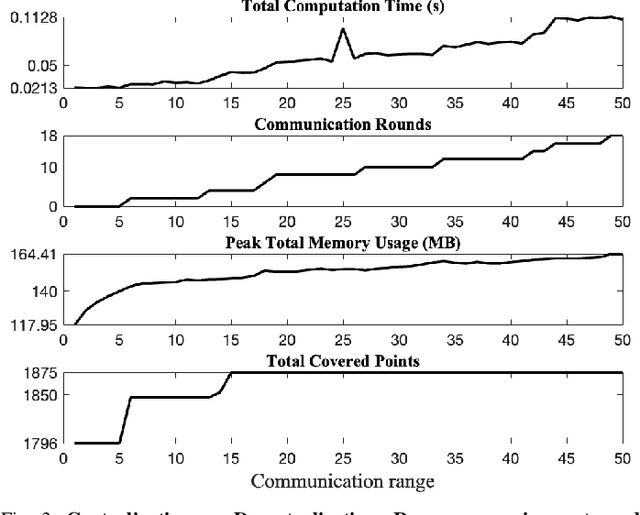
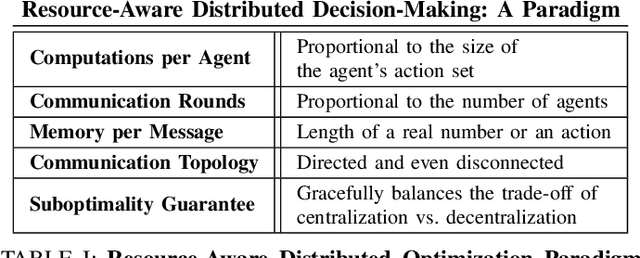
We introduce the first algorithm for distributed decision-making that provably balances the trade-off of centralization, for global near-optimality, vs. decentralization, for near-minimal on-board computation, communication, and memory resources. We are motivated by the future of autonomy that involves heterogeneous robots collaborating in complex~tasks, such as image covering, target tracking, and area monitoring. Current algorithms, such as consensus algorithms, are insufficient to fulfill this future: they achieve distributed communication only, at the expense of high communication, computation, and memory overloads. A shift to resource-aware algorithms is needed, that can account for each robot's on-board resources, independently. We provide the first resource-aware algorithm, Resource-Aware distributed Greedy (RAG). We focus on maximization problems involving monotone and "doubly" submodular functions, a diminishing returns property. RAG has near-minimal on-board resource requirements. Each agent can afford to run the algorithm by adjusting the size of its neighborhood, even if that means selecting actions in complete isolation. RAG has provable approximation performance, where each agent can independently determine its contribution. All in all, RAG is the first algorithm to quantify the trade-off of centralization, for global near-optimality, vs. decentralization, for near-minimal on-board resource requirements. To capture the trade-off, we introduce the notion of Centralization Of Information among non-Neighbors (COIN). We validate RAG in simulated scenarios of image covering with mobile robots.