 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Automated Parameter Optimization on Transfer Learning for CPDP: An Empirical Study
Feb 08, 2020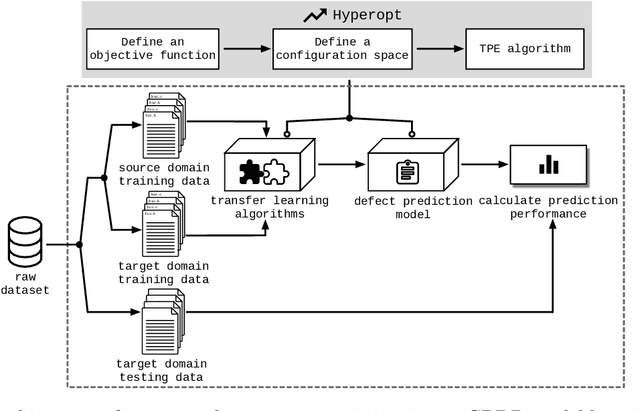
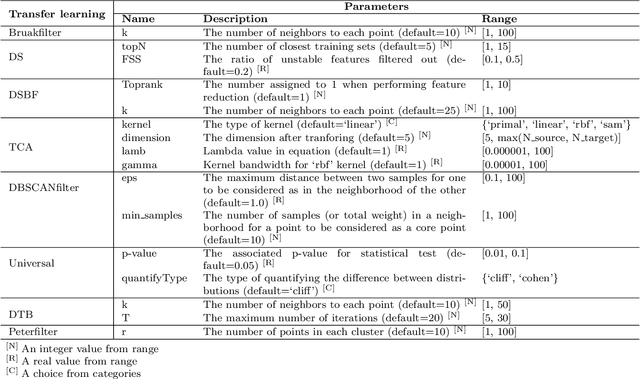
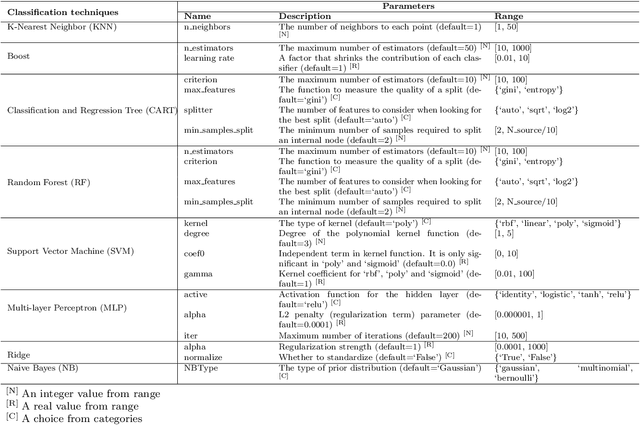
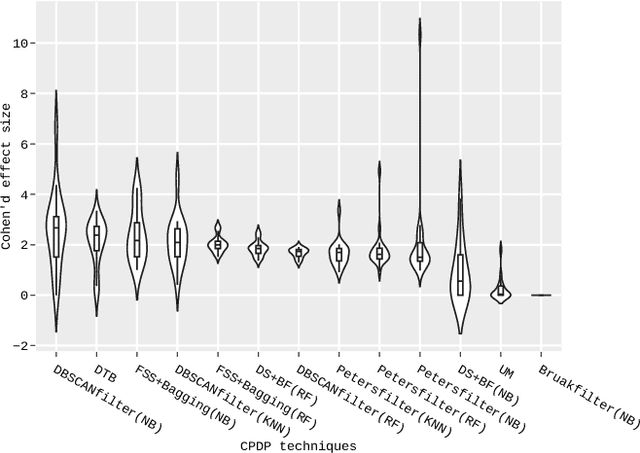
Data-driven defect prediction has become increasingly important in software engineering process. Since it is not uncommon that data from a software project is insufficient for training a reliable defect prediction model, transfer learning that borrows data/knowledge from other projects to facilitate the model building at the current project, namely cross-project defect prediction (CPDP), is naturally plausible. Most CPDP techniques involve two major steps, i.e., transfer learning and classification, each of which has at least one parameter to be tuned to achieve their optimal performance. This practice fits well with the purpose of automated parameter optimization. However, there is a lack of thorough understanding about what are the impacts of automated parameter optimization on various CPDP techniques. In this paper, we present the first empirical study that looks into such impacts on 62 CPDP techniques, 13 of which are chosen from the existing CPDP literature while the other 49 ones have not been explored before. We build defect prediction models over 20 real-world software projects that are of different scales and characteristics. Our findings demonstrate that: (1) Automated parameter optimization substantially improves the defect prediction performance of 77\% CPDP techniques with a manageable computational cost. Thus more efforts on this aspect are required in future CPDP studies. (2) Transfer learning is of ultimate importance in CPDP. Given a tight computational budget, it is more cost-effective to focus on optimizing the parameter configuration of transfer learning algorithms (3) The research on CPDP is far from mature where it is "not difficult" to find a better alternative by making a combination of existing transfer learning and classification techniques. This finding provides important insights about the future design of CPDP techniques.
Which Surrogate Works for Empirical Performance Modelling? A Case Study with Differential Evolution
Jan 30, 2019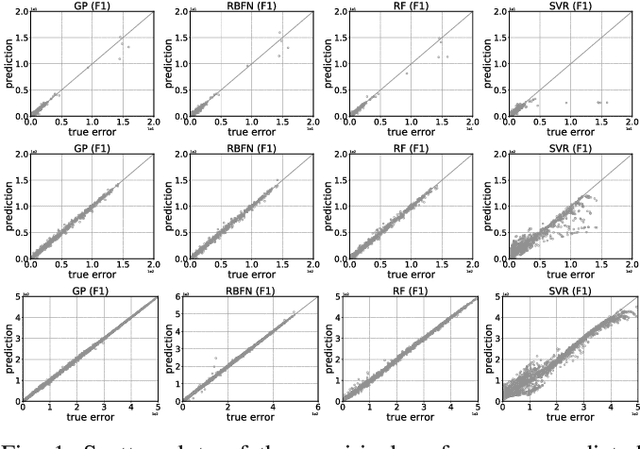
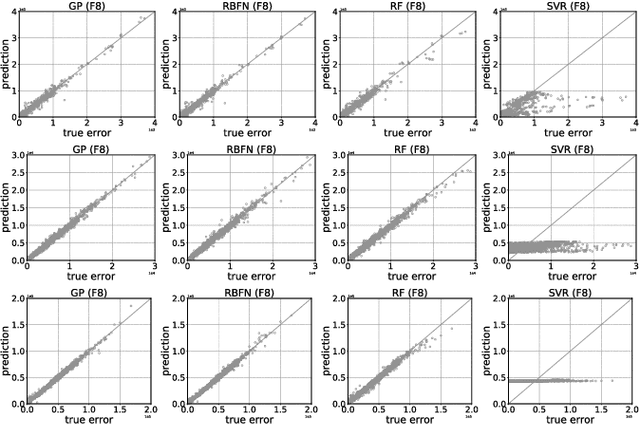
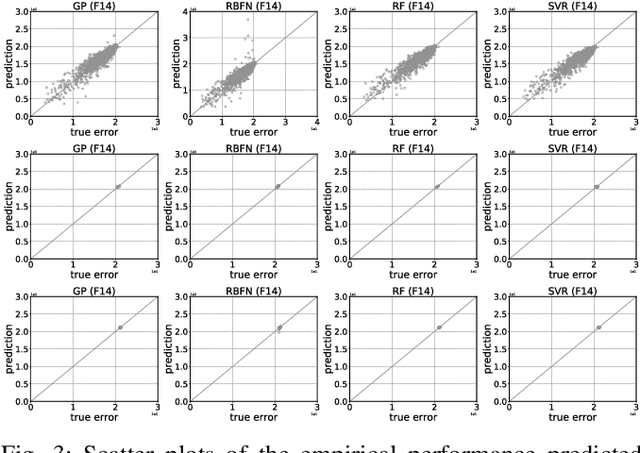
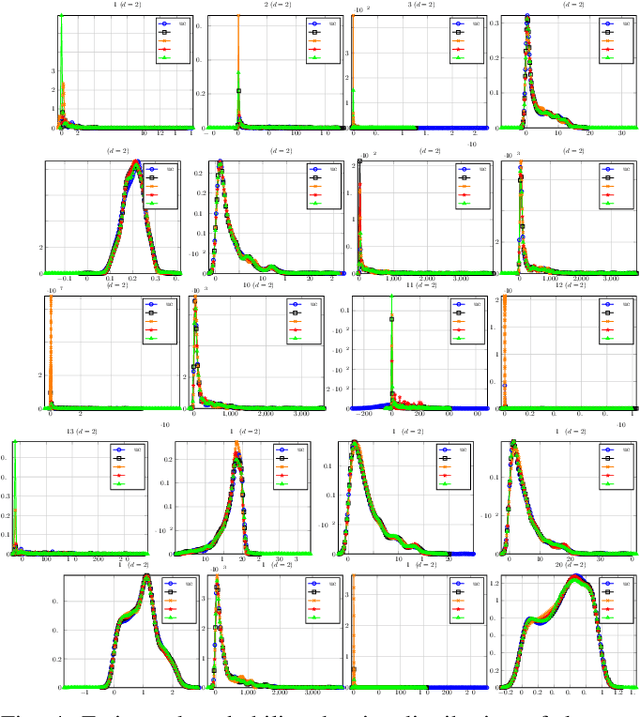
It is not uncommon that meta-heuristic algorithms contain some intrinsic parameters, the optimal configuration of which is crucial for achieving their peak performance. However, evaluating the effectiveness of a configuration is expensive, as it involves many costly runs of the target algorithm. Perhaps surprisingly, it is possible to build a cheap-to-evaluate surrogate that models the algorithm's empirical performance as a function of its parameters. Such surrogates constitute an important building block for understanding algorithm performance, algorithm portfolio/selection, and the automatic algorithm configuration. In principle, many off-the-shelf machine learning techniques can be used to build surrogates. In this paper, we take the differential evolution (DE) as the baseline algorithm for proof-of-concept study. Regression models are trained to model the DE's empirical performance given a parameter configuration. In particular, we evaluate and compare four popular regression algorithms both in terms of how well they predict the empirical performance with respect to a particular parameter configuration, and also how well they approximate the parameter versus the empirical performance landscapes.