 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Need One Detector: Unified Object Detector for Different Modalities based on Vision Transformers
Jul 03, 2022


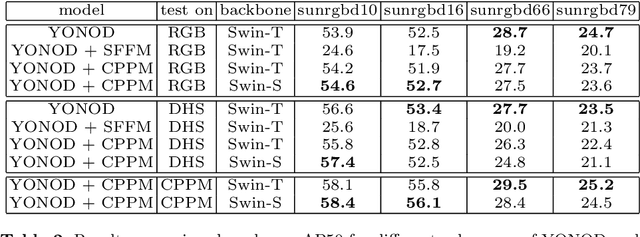
Most systems use different models for different modalities, such as one model for processing RGB images and one for depth images. Meanwhile, some recent works discovered that an identical model for one modality can be used for another modality with the help of cross modality transfer learning. In this article, we further find out that by using a vision transformer together with cross/inter modality transfer learning, a unified detector can achieve better performances when using different modalities as inputs. The unified model is useful as we don't need to maintain separate models or weights for robotics, hence, it is more efficient. One application scenario of our unified system for robotics can be: without any model architecture and model weights updating, robotics can switch smoothly on using RGB camera or both RGB and Depth Sensor during the day time and Depth sensor during the night time . Experiments on SUN RGB-D dataset show: Our unified model is not only efficient, but also has a similar or better performance in terms of mAP50 based on SUNRGBD16 category: compare with the RGB only one, ours is slightly worse (52.3 $\to$ 51.9). compare with the point cloud only one, we have similar performance (52.7 $\to$ 52.8); When using the novel inter modality mixing method proposed in this work, our model can achieve a significantly better performance with 3.1 (52.7 $\to$ 55.8) absolute improvement comparing with the previous best result. Code (including training/inference logs and model checkpoints) is available: \url{https://github.com/liketheflower/YONOD.git}
simCrossTrans: A Simple Cross-Modality Transfer Learning for Object Detection with ConvNets or Vision Transformers
Mar 20, 2022

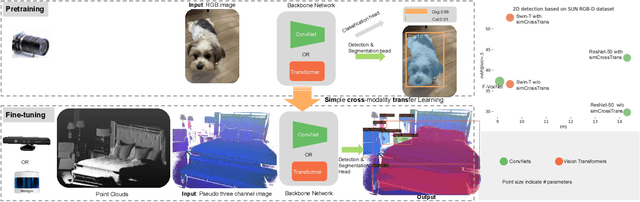

Transfer learning is widely used in computer vision (CV), natural language processing (NLP) and achieves great success. Most transfer learning systems are based on the same modality (e.g. RGB image in CV and text in NLP). However, the cross-modality transfer learning (CMTL) systems are scarce. In this work, we study CMTL from 2D to 3D sensor to explore the upper bound performance of 3D sensor only systems, which play critical roles in robotic navigation and perform well in low light scenarios. While most CMTL pipelines from 2D to 3D vision are complicated and based on Convolutional Neural Networks (ConvNets), ours is easy to implement, expand and based on both ConvNets and Vision transformers(ViTs): 1) By converting point clouds to pseudo-images, we can use an almost identical network from pre-trained models based on 2D images. This makes our system easy to implement and expand. 2) Recently ViTs have been showing good performance and robustness to occlusions, one of the key reasons for poor performance of 3D vision systems. We explored both ViT and ConvNet with similar model sizes to investigate the performance difference. We name our approach simCrossTrans: simple cross-modality transfer learning with ConvNets or ViTs. Experiments on SUN RGB-D dataset show: with simCrossTrans we achieve $13.2\%$ and $16.1\%$ absolute performance gain based on ConvNets and ViTs separately. We also observed the ViTs based performs $9.7\%$ better than the ConvNets one, showing the power of simCrossTrans with ViT. simCrossTrans with ViTs surpasses the previous state-of-the-art (SOTA) by a large margin of $+15.4\%$ mAP50. Compared with the previous 2D detection SOTA based RGB images, our depth image only system only has a $1\%$ gap. The code, training/inference logs and models are publicly available at https://github.com/liketheflower/simCrossTrans
Frustum VoxNet for 3D object detection from RGB-D or Depth images
Oct 12, 2019
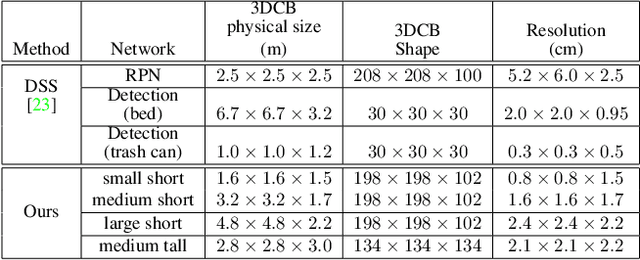
Recently, there have been a plethora of classification and detection systems from RGB as well as 3D images. In this work, we describe a new 3D object detection system from an RGB-D or depth-only point cloud. Our system first detects objects in 2D (either RGB, or pseudo-RGB constructed from depth). The next step is to detect 3D objects within the 3D frustums these 2D detections define. This is achieved by voxelizing parts of the frustums (since frustums can be really large), instead of using the whole frustums as done in earlier work. The main novelty of our system has to do with determining which parts (3D proposals) of the frustums to voxelize, thus allowing us to provide high resolution representations around the objects of interest. It also allows our system to have reduced memory requirements. These 3D proposals are fed to an efficient ResNet-based 3D Fully Convolutional Network (FCN). Our 3D detection system is fast, and can be integrated into a robotics platform. With respect to systems that do not perform voxelization (such as PointNet), our methods can operate without the requirement of subsampling of the datasets. We have also introduced a pipelining approach that further improves the efficiency of our system. Results on SUN RGB-D dataset show that our system, which is based on a small network, can process 20 frames per second with comparable detection results to the state-of-the-art , achieving a 2x speedup.
A survey of Object Classification and Detection based on 2D/3D data
May 29, 2019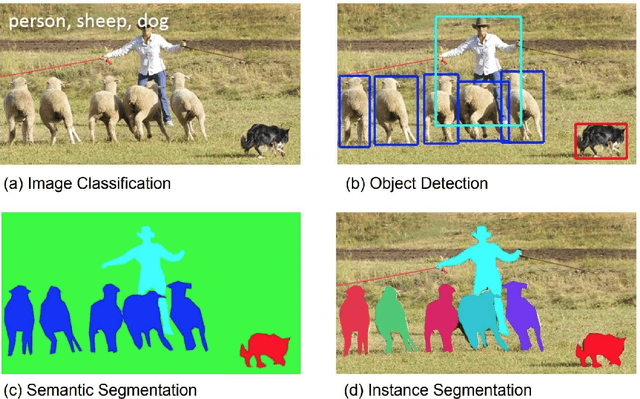
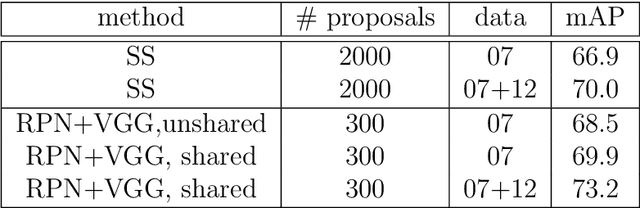
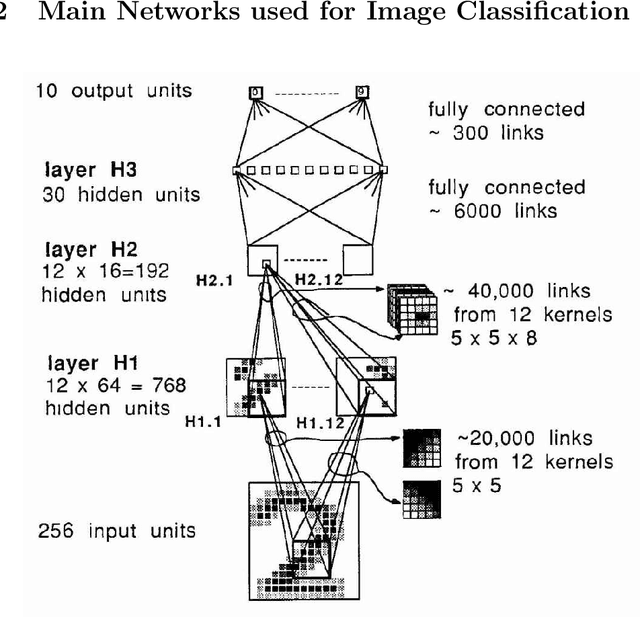

Recently, by using deep neural network based algorithms, object classification, detection and semantic segmentation solutions are significantly improved. However, one challenge for 2D image-based systems is that they cannot provide accurate 3D location information. This is critical for location sensitive applications such as autonomous driving and robot navigation. On the other hand, 3D methods, such as RGB-D and RGB-LiDAR based systems, can provide solutions that significantly improve the RGB only approaches. That is why this is an interesting research area for both industry and academia. Compared with 2D image-based systems, 3D-based systems are more complicated due to the following five reasons: 1) Data representation itself is more complicated. 3D images can be represented by point clouds, meshes, volumes. 2D images have pixel grid representations. 2) The computation and memory resource requirement is higher as an extra dimension is added. 3) Different distribution of the objects and difference in scene areas between indoor and outdoor make one unified framework hard to achieve. 4) 3D data, especially for the outdoor scenario, is sparse compared with the dense 2D images which makes the detection task more challenging. Finally, large size labelled datasets, which are extremely important for supervised based algorithms, are still under construction compared with well-built 2D datasets such as ImageNet. Based on challenges listed above, the described systems are organized by application scenarios, data representation methods and main tasks addressed. At the same time, critical 2D based systems which greatly influence the 3D ones are also introduced to show the connection between them.