 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Understanding the Population Dynamics of the NSGA-II to the First Proven Lower Bounds
Sep 28, 2022
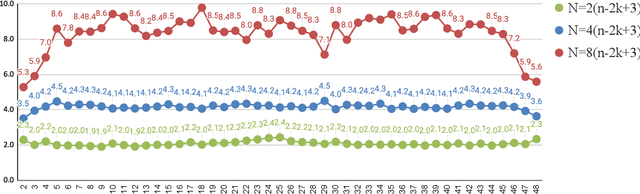
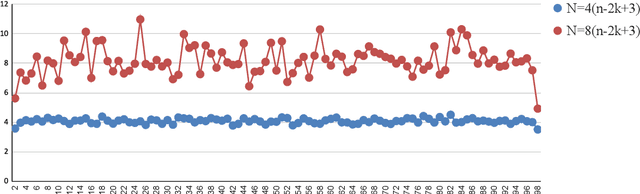
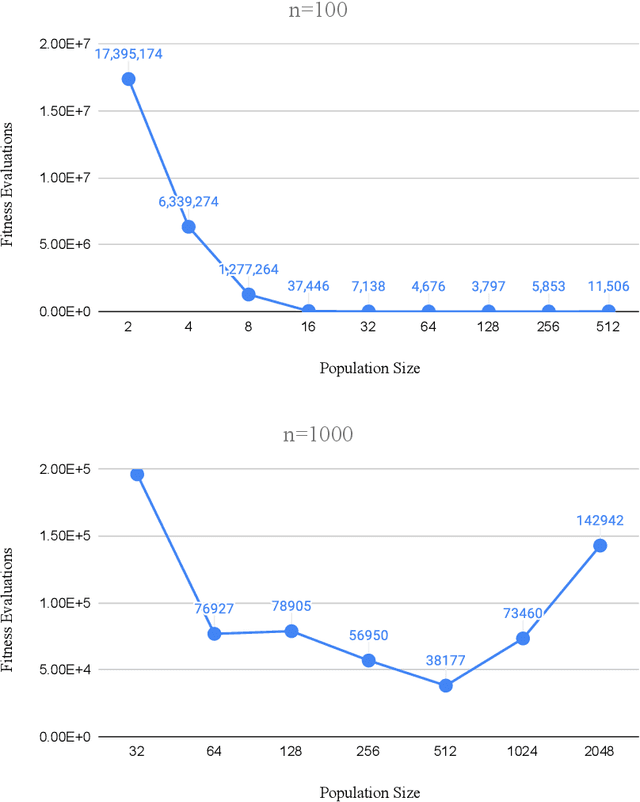
Due to the more complicated population dynamics of the NSGA-II, none of the existing runtime guarantees for this algorithm is accompanied by a non-trivial lower bound. Via a first mathematical understanding of the population dynamics of the NSGA-II, that is, by estimating the expected number of individuals having a certain objective value, we prove that the NSGA-II with suitable population size needs $\Omega(Nn\log n)$ function evaluations to find the Pareto front of the OneMinMax problem and $\Omega(Nn^k)$ evaluations on the OneJumpZeroJump problem with jump size $k$. These bounds are asymptotically tight (that is, they match previously shown upper bounds) and show that the NSGA-II here does not even in terms of the parallel runtime (number of iterations) profit from larger population sizes. For the OneJumpZeroJump problem and when the same sorting is used for the computation of the crowding distance contributions of the two objectives, we even obtain a runtime estimate that is tight including the leading constant.
The First Mathematical Proof That Crossover Gives Super-Constant Performance Gains For the NSGA-II
Aug 18, 2022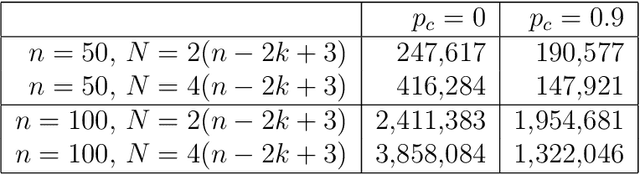
Very recently, the first mathematical runtime analyses for the NSGA-II, the most common multi-objective evolutionary algorithm, have been conducted (Zheng, Liu, Doerr (AAAI 2022)). Continuing this research direction, we prove that the NSGA-II optimizes the OneJumpZeroJump benchmark asymptotically faster when crossover is employed. This is the first time such an advantage of crossover is proven for the NSGA-II. Our arguments can be transferred to single-objective optimization. They then prove that crossover can speed-up the $(\mu+1)$ genetic algorithm in a different way and more pronounced than known before. Our experiments confirm the added value of crossover and show that the observed speed-ups are even larger than what our proofs can guarantee.
A First Runtime Analysis of the NSGA-II on a Multimodal Problem
Apr 28, 2022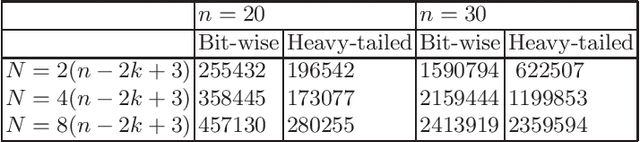
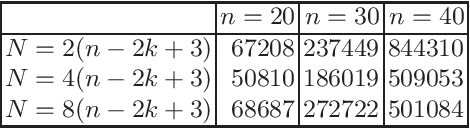
Very recently, the first mathematical runtime analyses of the multi-objective evolutionary optimizer NSGA-II have been conducted (AAAI 2022, GECCO 2022 (to appear), arxiv 2022). We continue this line of research with a first runtime analysis of this algorithm on a benchmark problem consisting of two multimodal objectives. We prove that if the population size $N$ is at least four times the size of the Pareto front, then the NSGA-II with four different ways to select parents and bit-wise mutation optimizes the OneJumpZeroJump benchmark with jump size~$2 \le k \le n/4$ in time $O(N n^k)$. When using fast mutation, a recently proposed heavy-tailed mutation operator, this guarantee improves by a factor of $k^{\Omega(k)}$. Overall, this work shows that the NSGA-II copes with the local optima of the OneJumpZeroJump problem at least as well as the global SEMO algorithm.
Translate & Fill: Improving Zero-Shot Multilingual Semantic Parsing with Synthetic Data
Sep 09, 2021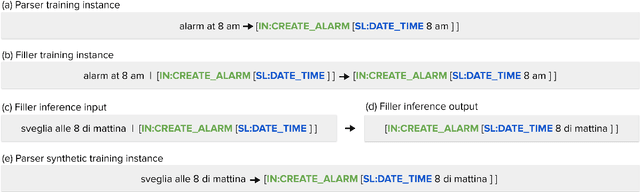

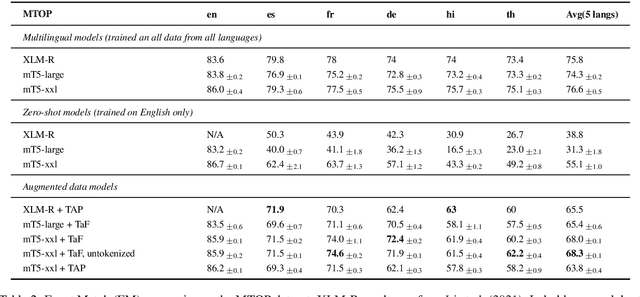
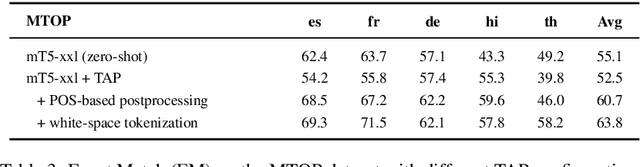
While multilingual pretrained language models (LMs) fine-tuned on a single language have shown substantial cross-lingual task transfer capabilities, there is still a wide performance gap in semantic parsing tasks when target language supervision is available. In this paper, we propose a novel Translate-and-Fill (TaF) method to produce silver training data for a multilingual semantic parser. This method simplifies the popular Translate-Align-Project (TAP) pipeline and consists of a sequence-to-sequence filler model that constructs a full parse conditioned on an utterance and a view of the same parse. Our filler is trained on English data only but can accurately complete instances in other languages (i.e., translations of the English training utterances), in a zero-shot fashion. Experimental results on three multilingual semantic parsing datasets show that data augmentation with TaF reaches accuracies competitive with similar systems which rely on traditional alignment techniques.
From Audio to Semantics: Approaches to end-to-end spoken language understanding
Sep 24, 2018
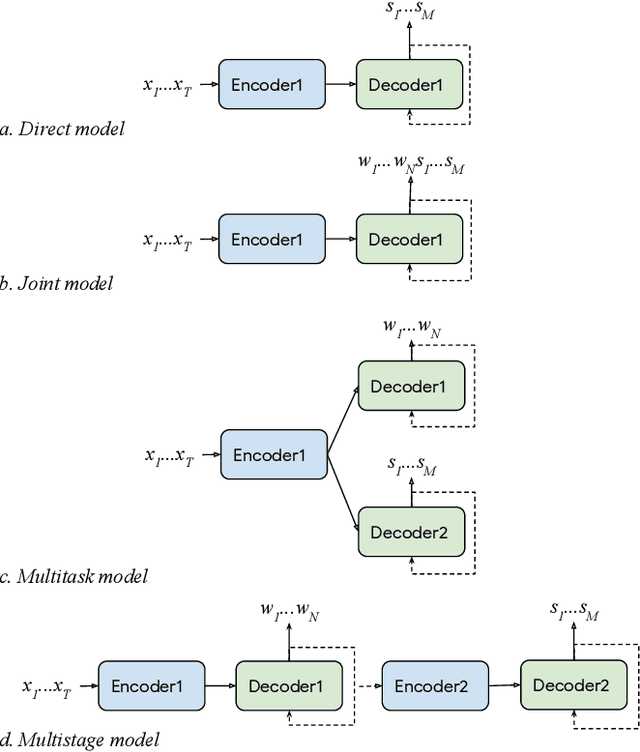
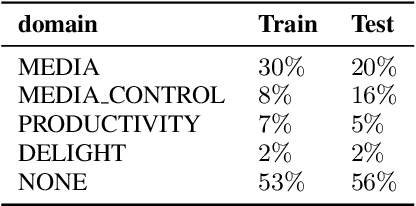
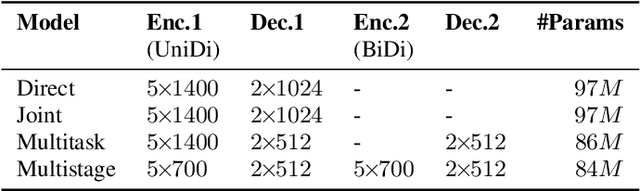
Conventional spoken language understanding systems consist of two main components: an automatic speech recognition module that converts audio to a transcript, and a natural language understanding module that transforms the resulting text (or top N hypotheses) into a set of domains, intents, and arguments. These modules are typically optimized independently. In this paper, we formulate audio to semantic understanding as a sequence-to-sequence problem [1]. We propose and compare various encoder-decoder based approaches that optimize both modules jointly, in an end-to-end manner. Evaluations on a real-world task show that 1) having an intermediate text representation is crucial for the quality of the predicted semantics, especially the intent arguments and 2) jointly optimizing the full system improves overall accuracy of prediction. Compared to independently trained models, our best jointly trained model achieves similar domain and intent prediction F1 scores, but improves argument word error rate by 18% relative.