 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized ReLU Activation for Uncertainty Estimation of Deep Neural Networks
Jul 15, 2021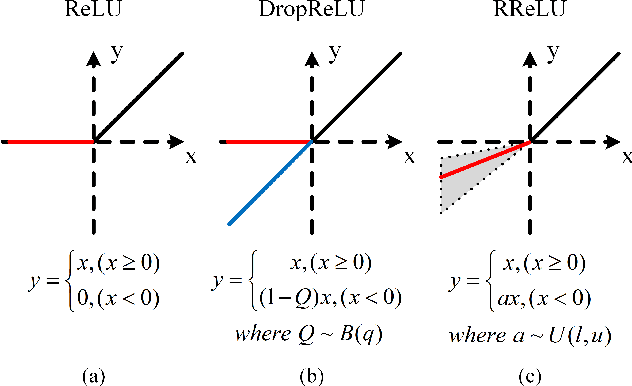
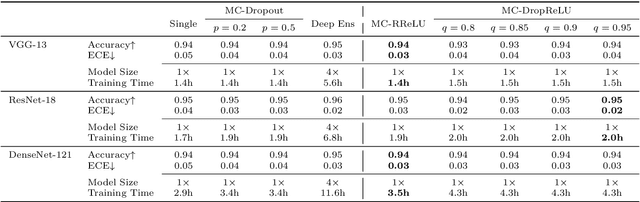
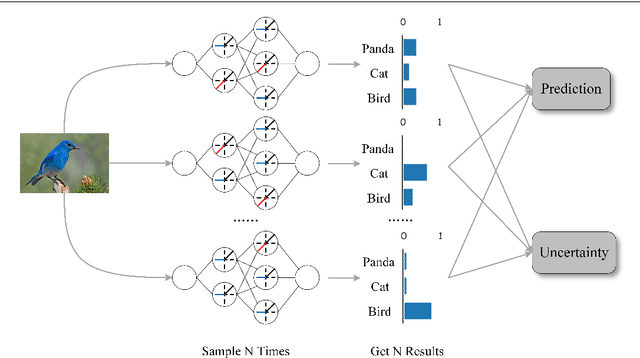
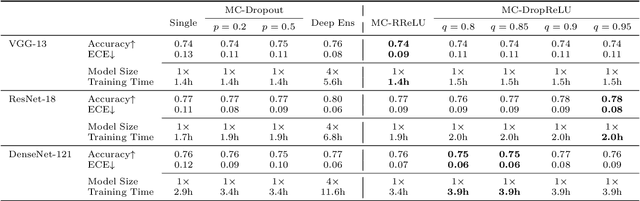
Deep neural networks (DNNs) have successfully learned useful data representations in various tasks, however, assessing the reliability of these representations remains a challenge. Deep Ensemble is widely considered the state-of-the-art method for uncertainty estimation, but it is very expensive to train and test. MC-Dropout is another alternative method, which is less expensive but lacks the diversity of predictions. To get more diverse predictions in less time, we introduce Randomized ReLU Activation (RRA) framework. Under the framework, we propose two strategies, MC-DropReLU and MC-RReLU, to estimate uncertainty. Instead of randomly dropping some neurons of the network as in MC-Dropout, the RRA framework adds randomness to the activation function module, making the outputs diverse. As far as we know, this is the first attempt to add randomness to the activation function module to generate predictive uncertainty. We analyze and compare the output diversity of MC-Dropout and our method from the variance perspective and obtain the relationship between the hyperparameters and output diversity in the two methods. Moreover, our method is simple to implement and does not need to modify the existing model. We experimentally validate the RRA framework on three widely used datasets, CIFAR10, CIFAR100, and TinyImageNet. The experiments demonstrate that our method has competitive performance but is more favorable in training time and memory requirements.
Physics-Informed Deep Reversible Regression Model for Temperature Field Reconstruction of Heat-Source Systems
Jul 05, 2021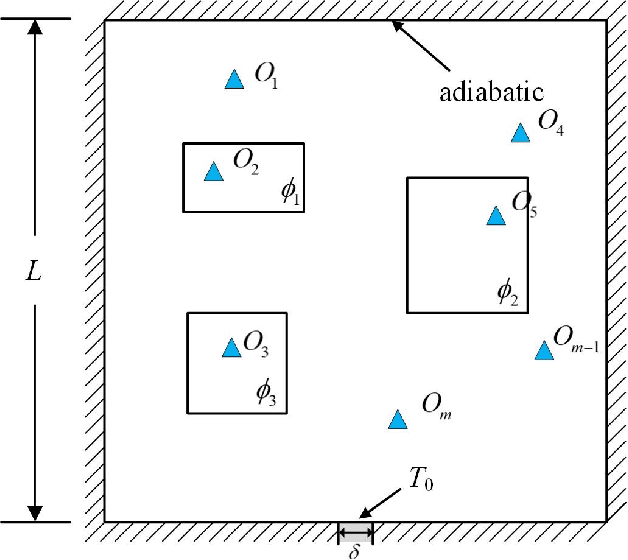
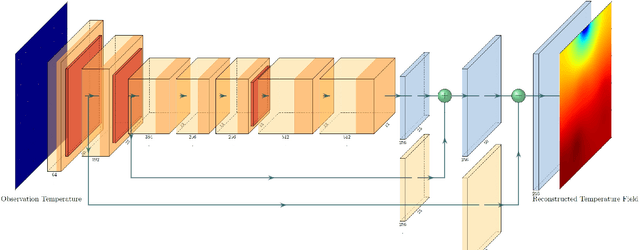
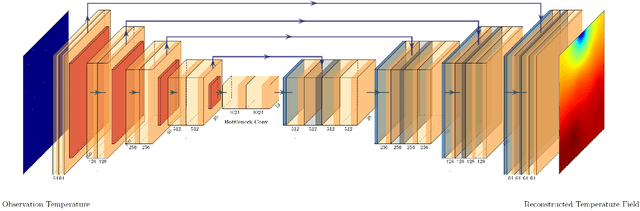
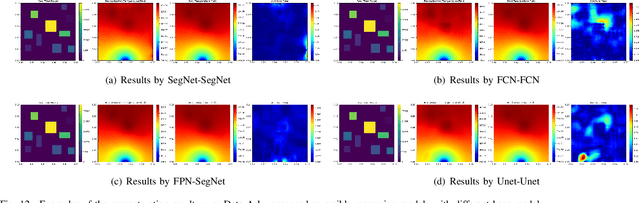
Temperature monitoring during the life time of heat source components in engineering systems becomes essential to guarantee the normal work and the working life of these components. However, prior methods, which mainly use the interpolate estimation to reconstruct the temperature field from limited monitoring points, require large amounts of temperature tensors for an accurate estimation. This may decrease the availability and reliability of the system and sharply increase the monitoring cost. To solve this problem, this work develops a novel physics-informed deep reversible regression models for temperature field reconstruction of heat-source systems (TFR-HSS), which can better reconstruct the temperature field with limited monitoring points unsupervisedly. First, we define the TFR-HSS task mathematically, and numerically model the task, and hence transform the task as an image-to-image regression problem. Then this work develops the deep reversible regression model which can better learn the physical information, especially over the boundary. Finally, considering the physical characteristics of heat conduction as well as the boundary conditions, this work proposes the physics-informed reconstruction loss including four training losses and jointly learns the deep surrogate model with these losses unsupervisedly. Experimental studies have conducted over typical two-dimensional heat-source systems to demonstrate the effectiveness of the proposed method.
A Deep Neural Network Surrogate Modeling Benchmark for Temperature Field Prediction of Heat Source Layout
Mar 20, 2021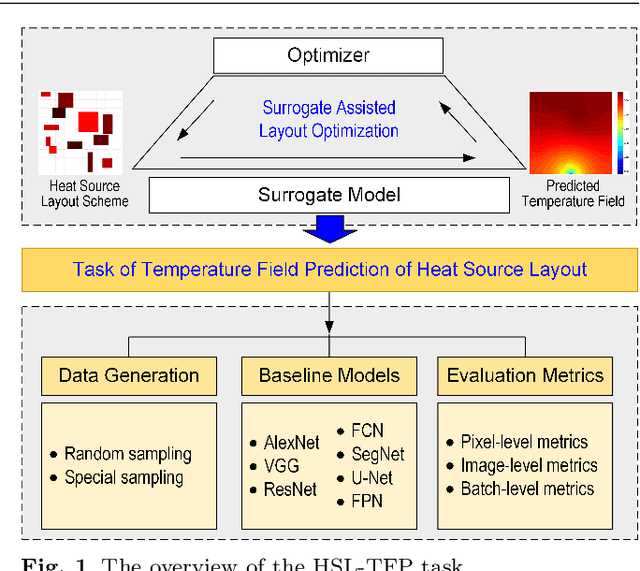
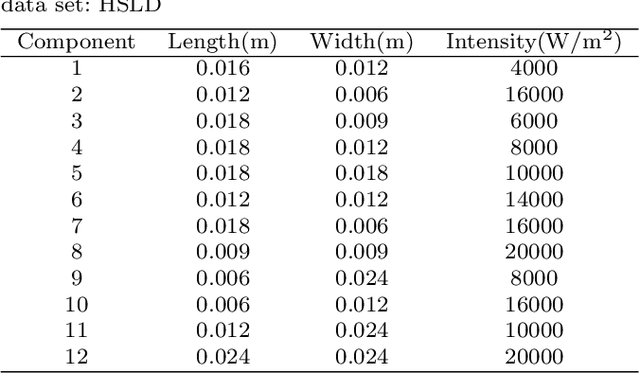
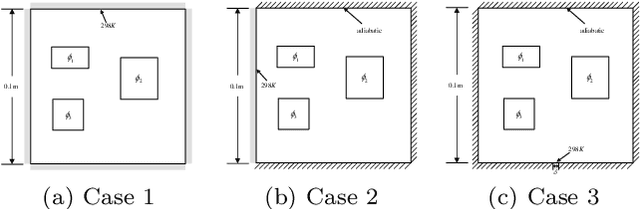

Thermal issue is of great importance during layout design of heat source components in systems engineering, especially for high functional-density products. Thermal analysis generally needs complex simulation, which leads to an unaffordable computational burden to layout optimization as it iteratively evaluates different schemes. Surrogate modeling is an effective way to alleviate computation complexity. However, temperature field prediction (TFP) with complex heat source layout (HSL) input is an ultra-high dimensional nonlinear regression problem, which brings great difficulty to traditional regression models. The Deep neural network (DNN) regression method is a feasible way for its good approximation performance. However, it faces great challenges in both data preparation for sample diversity and uniformity in the layout space with physical constraints, and proper DNN model selection and training for good generality, which necessitates efforts of both layout designer and DNN experts. To advance this cross-domain research, this paper proposes a DNN based HSL-TFP surrogate modeling task benchmark. With consideration for engineering applicability, sample generation, dataset evaluation, DNN model, and surrogate performance metrics, are thoroughly studied. Experiments are conducted with ten representative state-of-the-art DNN models. Detailed discussion on baseline results is provided and future prospects are analyzed for DNN based HSL-TFP tasks.
Statistical Loss and Analysis for Deep Learning in Hyperspectral Image Classification
Dec 28, 2019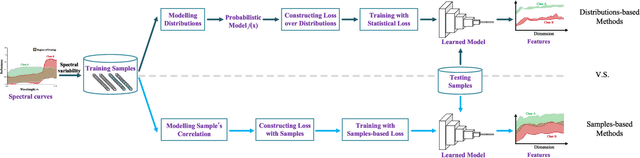
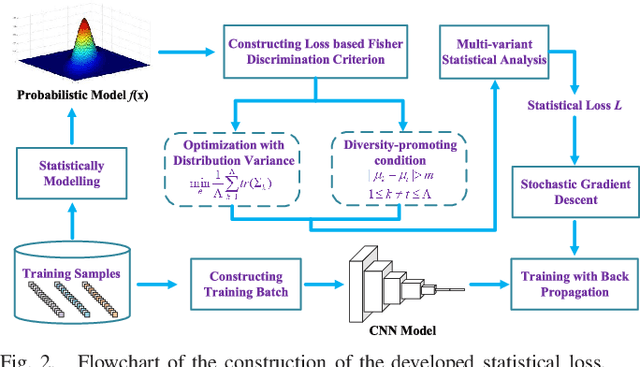

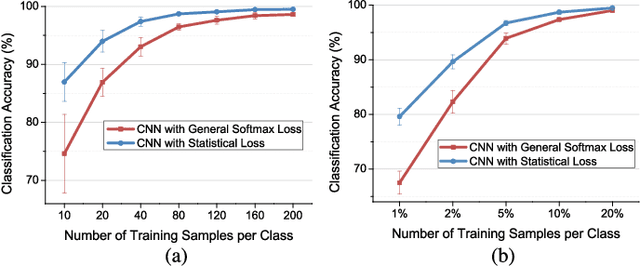
Nowadays, deep learning methods, especially the convolutional neural networks (CNNs), have shown impressive performance on extracting abstract and high-level features from the hyperspectral image. However, general training process of CNNs mainly considers the pixel-wise information or the samples' correlation to formulate the penalization while ignores the statistical properties especially the spectral variability of each class in the hyperspectral image. These samples-based penalizations would lead to the uncertainty of the training process due to the imbalanced and limited number of training samples. To overcome this problem, this work characterizes each class from the hyperspectral image as a statistical distribution and further develops a novel statistical loss with the distributions, not directly with samples for deep learning. Based on the Fisher discrimination criterion, the loss penalizes the sample variance of each class distribution to decrease the intra-class variance of the training samples. Moreover, an additional diversity-promoting condition is added to enlarge the inter-class variance between different class distributions and this could better discriminate samples from different classes in hyperspectral image. Finally, the statistical estimation form of the statistical loss is developed with the training samples through multi-variant statistical analysis. Experiments over the real-world hyperspectral images show the effectiveness of the developed statistical loss for deep learning.
Deep Manifold Embedding for Hyperspectral Image Classification
Dec 24, 2019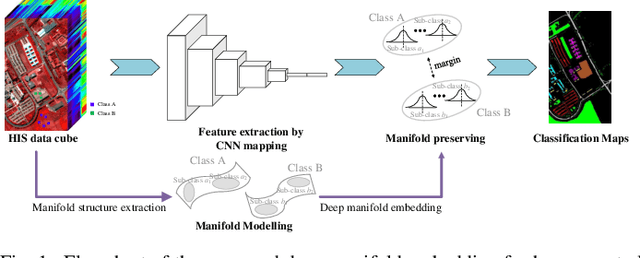

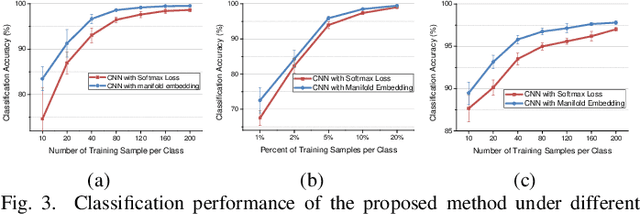
Deep learning methods have played a more and more important role in hyperspectral image classification. However, the general deep learning methods mainly take advantage of the information of sample itself or the pairwise information between samples while ignore the intrinsic data structure within the whole data. To tackle this problem, this work develops a novel deep manifold embedding method(DMEM) for hyperspectral image classification. First, each class in the image is modelled as a specific nonlinear manifold and the geodesic distance is used to measure the correlation between the samples. Then, based on the hierarchical clustering, the manifold structure of the data can be captured and each nonlinear data manifold can be divided into several sub-classes. Finally, considering the distribution of each sub-class and the correlation between different subclasses, the DMEM is constructed to preserve the estimated geodesic distances on the data manifold between the learned low dimensional features of different samples. Experiments over three real-world hyperspectral image datasets have demonstrated the effectiveness of the proposed method.
A novel statistical metric learning for hyperspectral image classification
May 13, 2019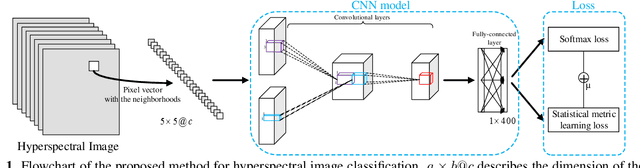
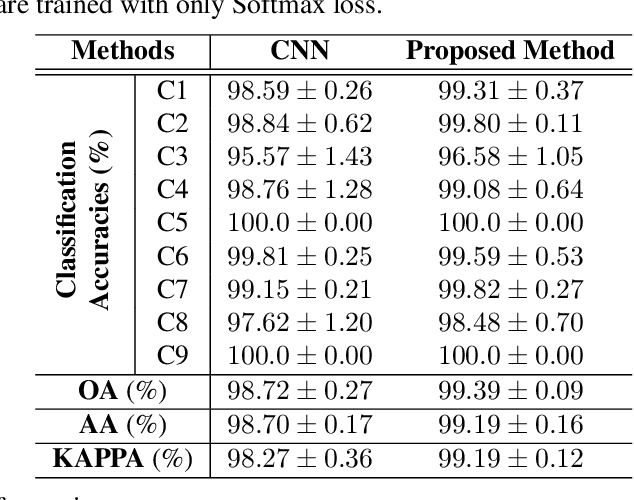

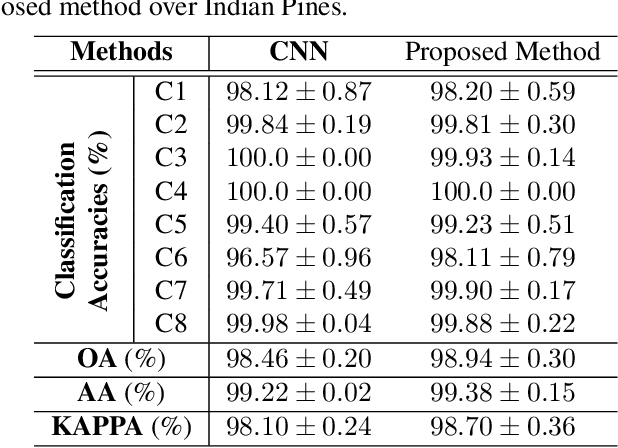
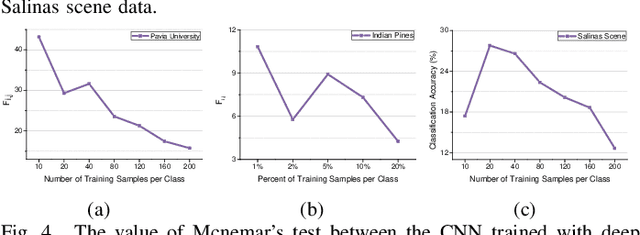
In this paper, a novel statistical metric learning is developed for spectral-spatial classification of the hyperspectral image. First, the standard variance of the samples of each class in each batch is used to decrease the intra-class variance within each class. Then, the distances between the means of different classes are used to penalize the inter-class variance of the training samples. Finally, the standard variance between the means of different classes is added as an additional diversity term to repulse different classes from each other. Experiments have conducted over two real-world hyperspectral image datasets and the experimental results have shown the effectiveness of the proposed statistical metric learning.
An End-to-End Joint Unsupervised Learning of Deep Model and Pseudo-Classes for Remote Sensing Scene Representation
Mar 18, 2019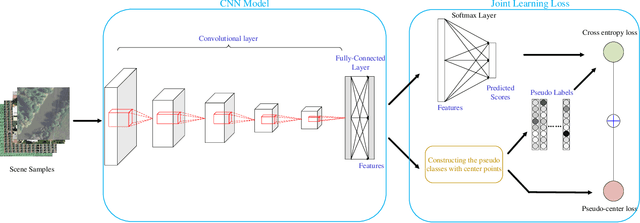
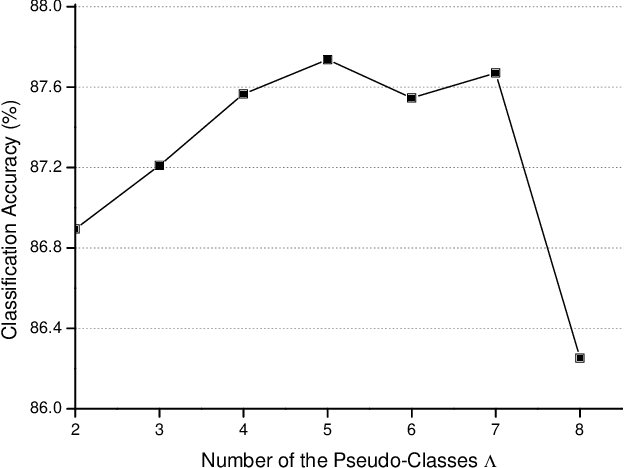
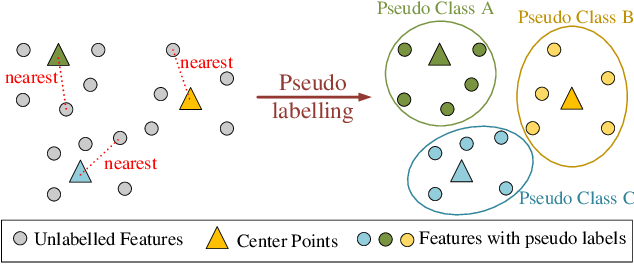

This work develops a novel end-to-end deep unsupervised learning method based on convolutional neural network (CNN) with pseudo-classes for remote sensing scene representation. First, we introduce center points as the centers of the pseudo classes and the training samples can be allocated with pseudo labels based on the center points. Therefore, the CNN model, which is used to extract features from the scenes, can be trained supervised with the pseudo labels. Moreover, a pseudo-center loss is developed to decrease the variance between the samples and the corresponding pseudo center point. The pseudo-center loss is important since it can update both the center points with the training samples and the CNN model with the center points in the training process simultaneously. Finally, joint learning of the pseudo-center loss and the pseudo softmax loss which is formulated with the samples and the pseudo labels is developed for unsupervised remote sensing scene representation to obtain discriminative representations from the scenes. Experiments are conducted over two commonly used remote sensing scene datasets to validate the effectiveness of the proposed method and the experimental results show the superiority of the proposed method when compared with other state-of-the-art methods.
Diversity in Machine Learning
Jul 04, 2018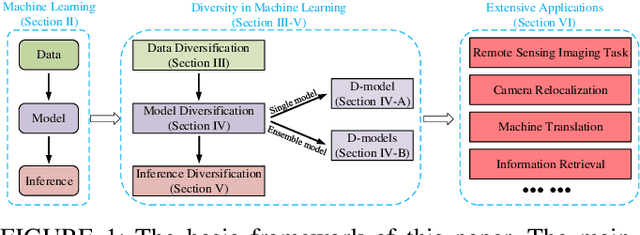
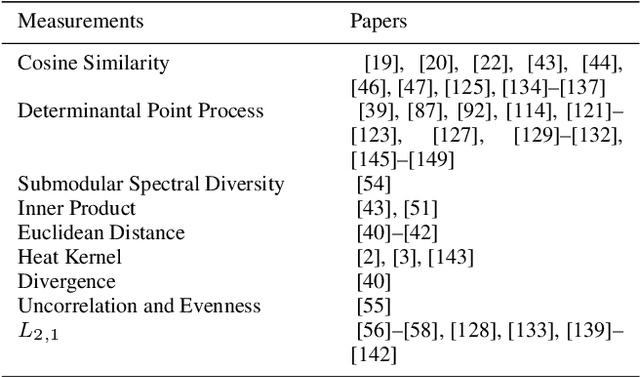
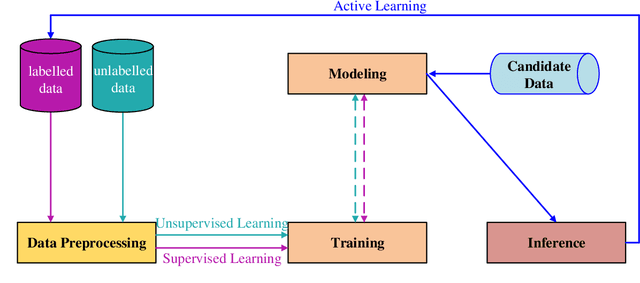

Machine learning methods have achieved good performance and been widely applied in various real-world applications. It can learn the model adaptively and be better fit for special requirements of different tasks. Many factors can affect the performance of the machine learning process, among which diversity of the machine learning is an important one. Generally, a good machine learning system is composed of plentiful training data, a good model training process, and an accurate inference. The diversity could help each procedure to guarantee a total good machine learning: diversity of the training data ensures the data contain enough discriminative information, diversity of the learned model (diversity in parameters of each model or diversity in models) makes each parameter/model capture unique or complement information and the diversity in inference can provide multiple choices each of which corresponds to a plausible result. However, there is no systematical analysis of the diversification in machine learning system. In this paper, we systematically summarize the methods to make data diversification, model diversification, and inference diversification in machine learning process, respectively. In addition, the typical applications where the diversity technology improved the machine learning performances have been surveyed, including the remote sensing imaging tasks, machine translation, camera relocalization, image segmentation, object detection, topic modeling, and others. Finally, we discuss some challenges of diversity technology in machine learning and point out some directions in future work. Our analysis provides a deeper understanding of the diversity technology in machine learning tasks, and hence can help design and learn more effective models for specific tasks.