 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGL-PGENet: A Parameterized Generation Framework for Robust Document Image Enhancement
May 28, 2025Document Image Enhancement (DIE) serves as a critical component in Document AI systems, where its performance substantially determines the effectiveness of downstream tasks. To address the limitations of existing methods confined to single-degradation restoration or grayscale image processing, we present Global with Local Parametric Generation Enhancement Network (GL-PGENet), a novel architecture designed for multi-degraded color document images, ensuring both efficiency and robustness in real-world scenarios. Our solution incorporates three key innovations: First, a hierarchical enhancement framework that integrates global appearance correction with local refinement, enabling coarse-to-fine quality improvement. Second, a Dual-Branch Local-Refine Network with parametric generation mechanisms that replaces conventional direct prediction, producing enhanced outputs through learned intermediate parametric representations rather than pixel-wise mapping. This approach enhances local consistency while improving model generalization. Finally, a modified NestUNet architecture incorporating dense block to effectively fuse low-level pixel features and high-level semantic features, specifically adapted for document image characteristics. In addition, to enhance generalization performance, we adopt a two-stage training strategy: large-scale pretraining on a synthetic dataset of 500,000+ samples followed by task-specific fine-tuning. Extensive experiments demonstrate the superiority of GL-PGENet, achieving state-of-the-art SSIM scores of 0.7721 on DocUNet and 0.9480 on RealDAE. The model also exhibits remarkable cross-domain adaptability and maintains computational efficiency for high-resolution images without performance degradation, confirming its practical utility in real-world scenarios.
Efficient Misalignment-Robust Multi-Focus Microscopical Images Fusion
Dec 21, 2018
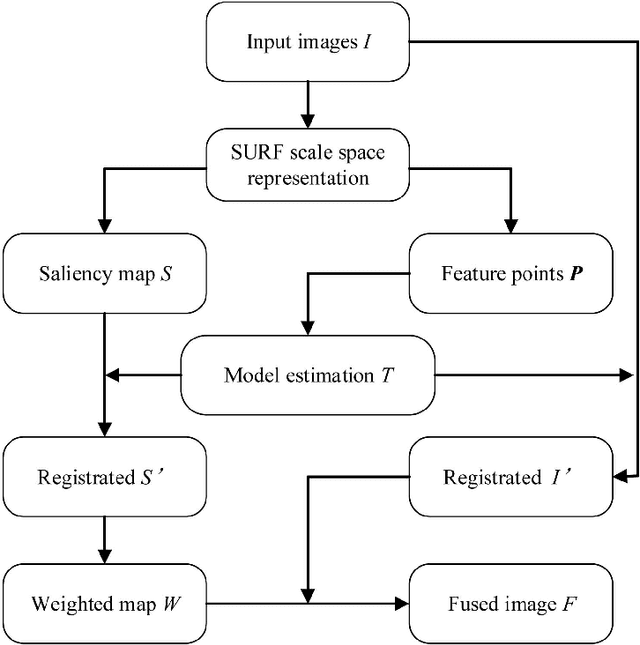

In this paper we propose a very efficient method to fuse the unregistered multi-focus microscopical images based on the speed-up robust features (SURF). Our method follows the pipeline of first registration and then fusion. However, instead of treating the registration and fusion as two completely independent stage, we propose to reuse the determinant of the approximate Hessian generated in SURF detection stage as the corresponding salient response for the final image fusion, thus it enables nearly cost-free saliency map generation. In addition, due to the adoption of SURF scale space representation, our method can generate scale-invariant saliency map which is desired for scale-invariant image fusion. We present an extensive evaluation on the dataset consisting of several groups of unregistered multi-focus 4K ultra HD microscopic images with size of 4112 x 3008. Compared with the state-of-the-art multi-focus image fusion methods, our method is much faster and achieve better results in the visual performance. Our method provides a flexible and efficient way to integrate complementary and redundant information from multiple multi-focus ultra HD unregistered images into a fused image that contains better description than any of the individual input images. Code is available at https://github.com/yiqingmy/JointRF.
Comparison Detector: A novel object detection method for small dataset
Oct 14, 2018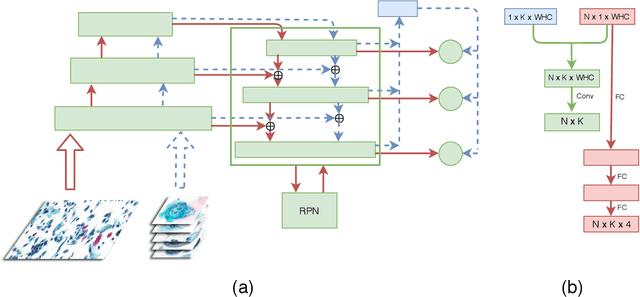
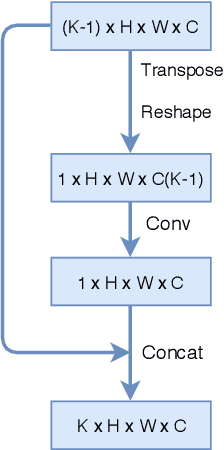
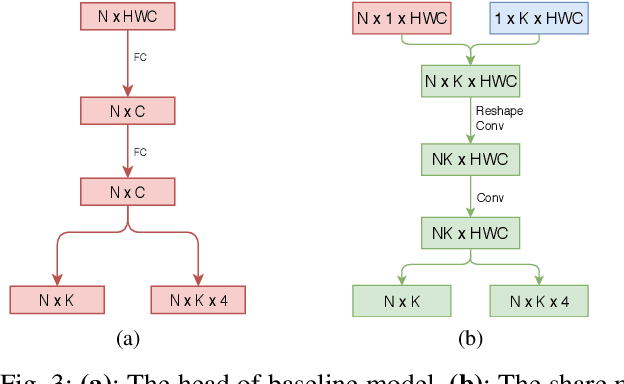
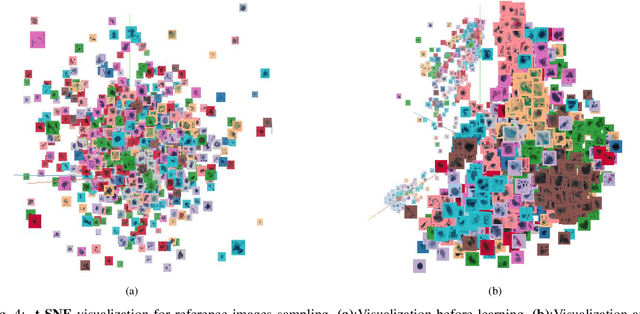
Though the object detection has shown great success when the training set is sufficient, there is a serious shortage of generalization in the small dataset scenario. However, we inevitably just get a small one in some application scenarios, especially medicine. In this paper, we propose Comparison detector which still maintains the end-to-end fashion in training and testing, surpassing the state-of-the-art two-stage object detection model on the small dataset. Inspired by one/few-shot learning, we replace the parameter classifier in feature pyramid network(FPN) with the comparison classifier in no-parameters or semi-parameters manner. In fact, a stronger inductive bias is added to the model to simplify the problem and reduce the dependence of data. The performance of our model is evaluated on the cervical cancer pathology test set. When training on the small dataset, it achieves a mAP 26.3% and an AR 35.7%, both improving about 20 points compared to baseline model. Moreover, Comparison detector achieves same mAP performance as the current state-of-the-art model when training on the medium dataset, and improves AR by 4 points. Our method is promising for the development of object detection in small dataset scenario.