 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Regularized Opponent Model with Maximum Entropy Objective
May 17, 2019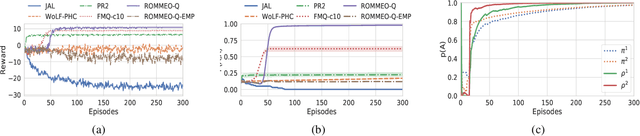
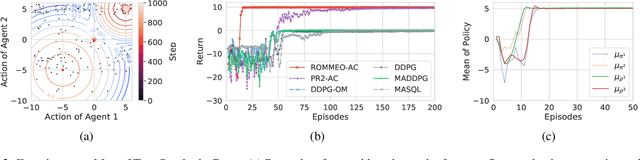
In a single-agent setting, reinforcement learning (RL) tasks can be cast into an inference problem by introducing a binary random variable o, which stands for the "optimality". In this paper, we redefine the binary random variable o in multi-agent setting and formalize multi-agent reinforcement learning (MARL) as probabilistic inference. We derive a variational lower bound of the likelihood of achieving the optimality and name it as Regularized Opponent Model with Maximum Entropy Objective (ROMMEO). From ROMMEO, we present a novel perspective on opponent modeling and show how it can improve the performance of training agents theoretically and empirically in cooperative games. To optimize ROMMEO, we first introduce a tabular Q-iteration method ROMMEO-Q with proof of convergence. We extend the exact algorithm to complex environments by proposing an approximate version, ROMMEO-AC. We evaluate these two algorithms on the challenging iterated matrix game and differential game respectively and show that they can outperform strong MARL baselines.
Dynamic State Warping
Mar 03, 2017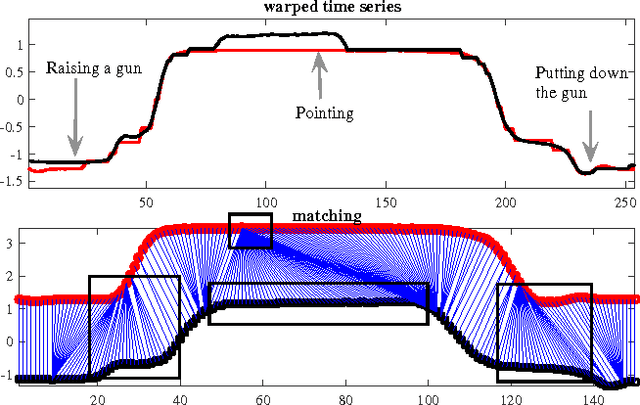

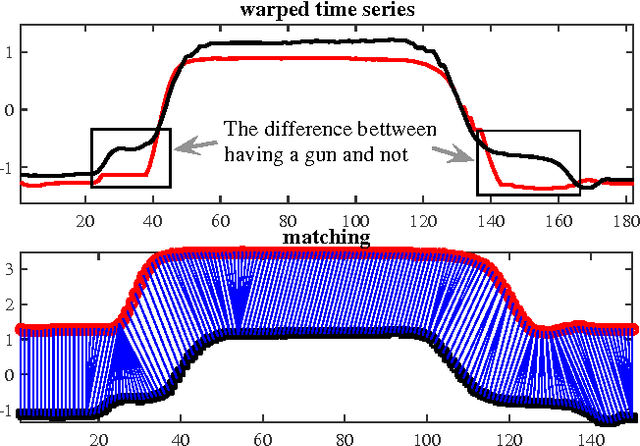
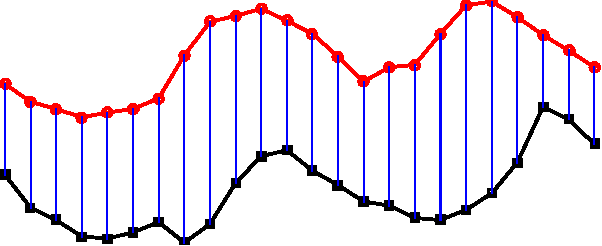
The ubiquity of sequences in many domains enhances significant recent interest in sequence learning, for which a basic problem is how to measure the distance between sequences. Dynamic time warping (DTW) aligns two sequences by nonlinear local warping and returns a distance value. DTW shows superior ability in many applications, e.g. video, image, etc. However, in DTW, two points are paired essentially based on point-to-point Euclidean distance (ED) without considering the autocorrelation of sequences. Thus, points with different semantic meanings, e.g. peaks and valleys, may be matched providing their coordinate values are similar. As a result, DTW is sensitive to noise and poorly interpretable. This paper proposes an efficient and flexible sequence alignment algorithm, dynamic state warping (DSW). DSW converts each time point into a latent state, which endows point-wise autocorrelation information. Alignment is performed by using the state sequences. Thus DSW is able to yield alignment that is semantically more interpretable than that of DTW. Using one nearest neighbor classifier, DSW shows significant improvement on classification accuracy in comparison to ED (70/85 wins) and DTW (74/85 wins). We also empirically demonstrate that DSW is more robust and scales better to long sequences than ED and DTW.