 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Grounded Graph Convolutional Network
May 10, 2023



Graph Convolutional Networks (GCNs) have shown strong performance in learning text representations for various tasks such as text classification, due to its expressive power in modeling graph structure data (e.g., a literature citation network). Most existing GCNs are limited to deal with documents included in a pre-defined graph, i.e., it cannot be generalized to out-of-graph documents. To address this issue, we propose to transform the document graph into a word graph, to decouple data samples (i.e., documents in training and test sets) and a GCN model by using a document-independent graph. Such word-level GCN could therefore naturally inference out-of-graph documents in an inductive way. The proposed Word-level Graph (WGraph) can not only implicitly learning word presentation with commonly-used word co-occurrences in corpora, but also incorporate extra global semantic dependency derived from inter-document relationships (e.g., literature citations). An inductive Word-grounded Graph Convolutional Network (WGCN) is proposed to learn word and document representations based on WGraph in a supervised manner. Experiments on text classification with and without citation networks evidence that the proposed WGCN model outperforms existing methods in terms of effectiveness and efficiency.
VGCN-BERT: Augmenting BERT with Graph Embedding for Text Classification
Apr 12, 2020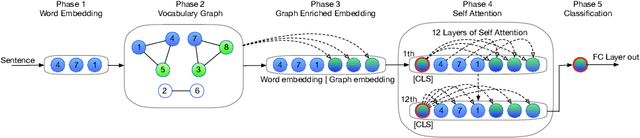
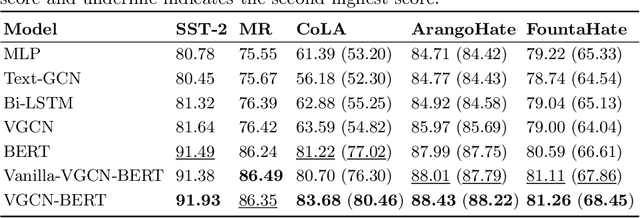
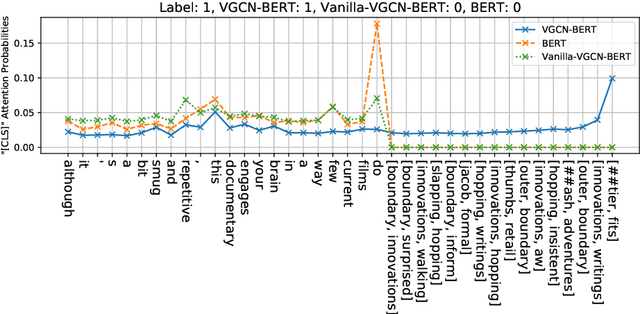
Much progress has been made recently on text classification with methods based on neural networks. In particular, models using attention mechanism such as BERT have shown to have the capability of capturing the contextual information within a sentence or document. However, their ability of capturing the global information about the vocabulary of a language is more limited. This latter is the strength of Graph Convolutional Networks (GCN). In this paper, we propose VGCN-BERT model which combines the capability of BERT with a Vocabulary Graph Convolutional Network (VGCN). Local information and global information interact through different layers of BERT, allowing them to influence mutually and to build together a final representation for classification. In our experiments on several text classification datasets, our approach outperforms BERT and GCN alone, and achieve higher effectiveness than that reported in previous studies.
* 12 pages, 2 figures