 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign, Mask and Select: A Simple Method for Incorporating Commonsense Knowledge into Language Representation Models
Aug 19, 2019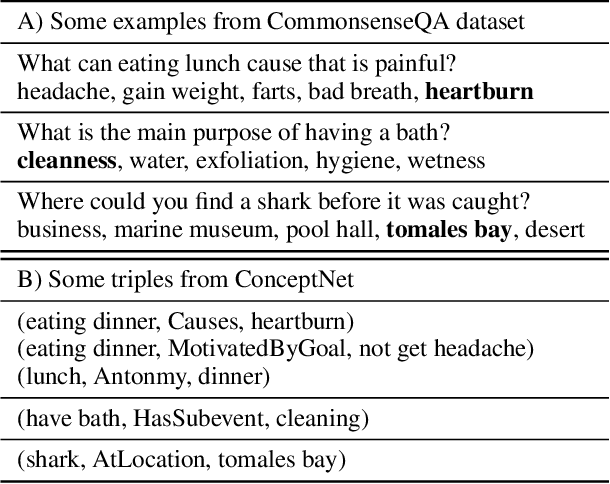
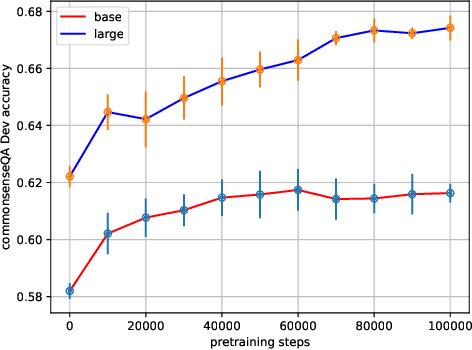
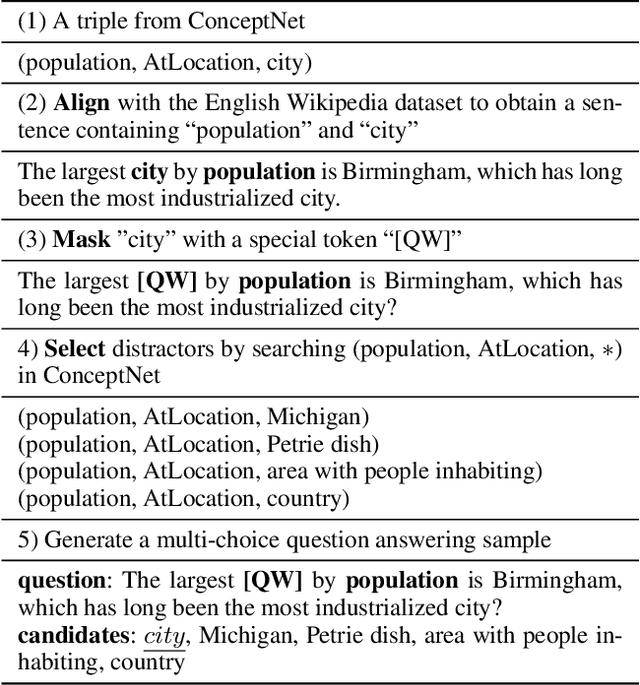

Neural language representation models such as Bidirectional Encoder Representations from Transformers (BERT) pre-trained on large-scale corpora can well capture rich semantics from plain text, and can be fine-tuned to consistently improve the performance on various natural language processing (NLP) tasks. However, the existing pre-trained language representation models rarely consider explicitly incorporating commonsense knowledge or other knowledge. In this paper, we develop a pre-training approach for incorporating commonsense knowledge into language representation models. We construct a commonsense-related multi-choice question answering dataset for pre-training a neural language representation model. The dataset is created automatically by our proposed "align, mask, and select" (AMS) method. We also investigate different pre-training tasks. Experimental results demonstrate that pre-training models using the proposed approach followed by fine-tuning achieves significant improvements on various commonsense-related tasks, such as CommonsenseQA and Winograd Schema Challenge, while maintaining comparable performance on other NLP tasks, such as sentence classification and natural language inference (NLI) tasks, compared to the original BERT models.
Multi-Level Matching and Aggregation Network for Few-Shot Relation Classification
Jun 16, 2019
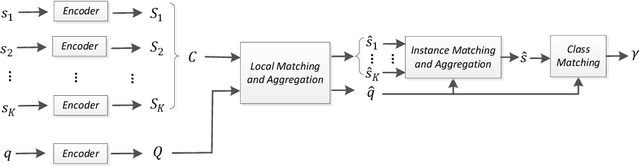
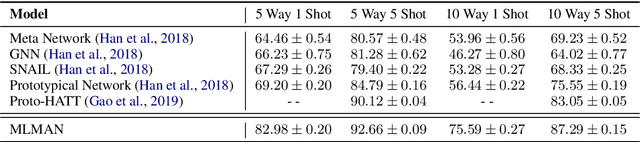
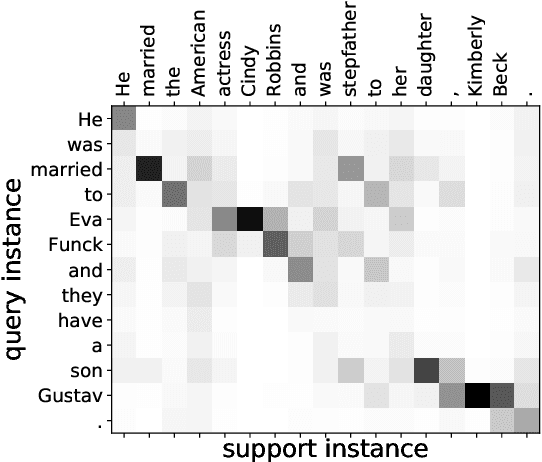
This paper presents a multi-level matching and aggregation network (MLMAN) for few-shot relation classification. Previous studies on this topic adopt prototypical networks, which calculate the embedding vector of a query instance and the prototype vector of each support set independently. In contrast, our proposed MLMAN model encodes the query instance and each support set in an interactive way by considering their matching information at both local and instance levels. The final class prototype for each support set is obtained by attentive aggregation over the representations of its support instances, where the weights are calculated using the query instance. Experimental results demonstrate the effectiveness of our proposed methods, which achieve a new state-of-the-art performance on the FewRel dataset.
Distant Supervision Relation Extraction with Intra-Bag and Inter-Bag Attentions
Mar 30, 2019
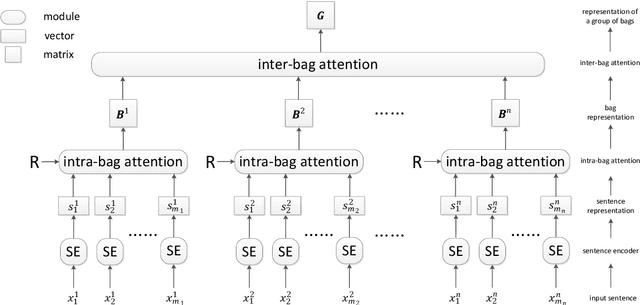
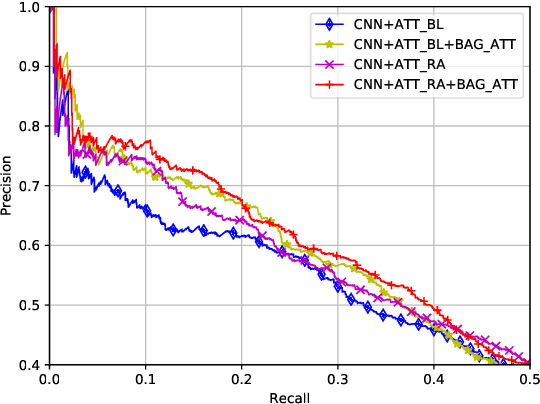
This paper presents a neural relation extraction method to deal with the noisy training data generated by distant supervision. Previous studies mainly focus on sentence-level de-noising by designing neural networks with intra-bag attentions. In this paper, both intra-bag and inter-bag attentions are considered in order to deal with the noise at sentence-level and bag-level respectively. First, relation-aware bag representations are calculated by weighting sentence embeddings using intra-bag attentions. Here, each possible relation is utilized as the query for attention calculation instead of only using the target relation in conventional methods. Furthermore, the representation of a group of bags in the training set which share the same relation label is calculated by weighting bag representations using a similarity-based inter-bag attention module. Finally, a bag group is utilized as a training sample when building our relation extractor. Experimental results on the New York Times dataset demonstrate the effectiveness of our proposed intra-bag and inter-bag attention modules. Our method also achieves better relation extraction accuracy than state-of-the-art methods on this dataset.
Hybrid semi-Markov CRF for Neural Sequence Labeling
May 10, 2018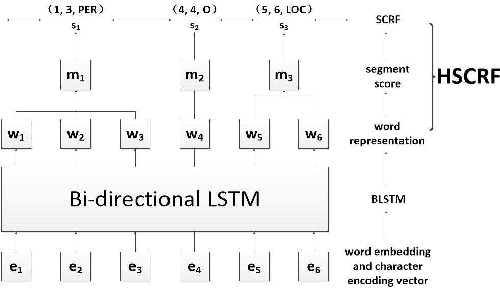
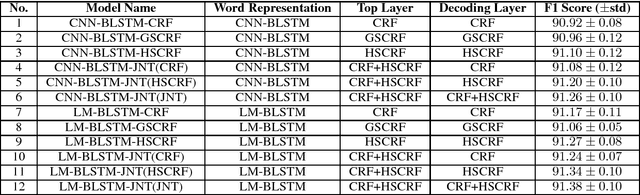
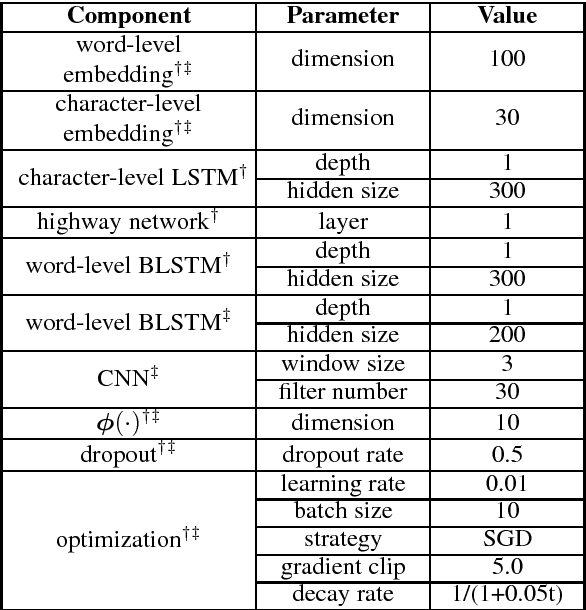
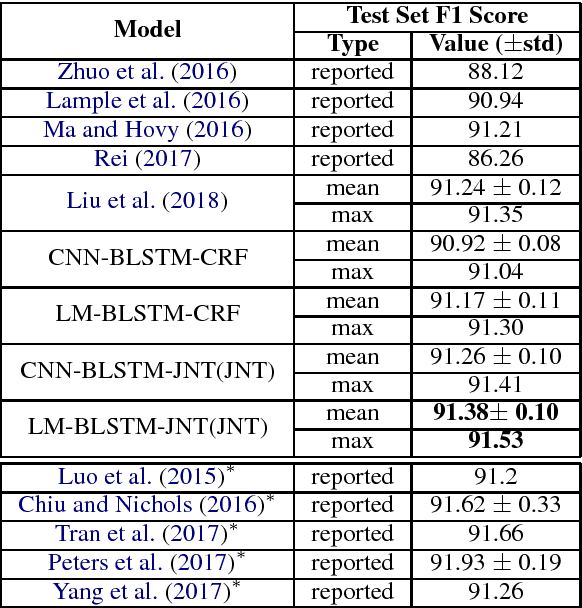
This paper proposes hybrid semi-Markov conditional random fields (SCRFs) for neural sequence labeling in natural language processing. Based on conventional conditional random fields (CRFs), SCRFs have been designed for the tasks of assigning labels to segments by extracting features from and describing transitions between segments instead of words. In this paper, we improve the existing SCRF methods by employing word-level and segment-level information simultaneously. First, word-level labels are utilized to derive the segment scores in SCRFs. Second, a CRF output layer and an SCRF output layer are integrated into an unified neural network and trained jointly. Experimental results on CoNLL 2003 named entity recognition (NER) shared task show that our model achieves state-of-the-art performance when no external knowledge is used.