 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Encoder-Decoder End-to-End Neural Diarization with Embedding Enhancer
Sep 13, 2023
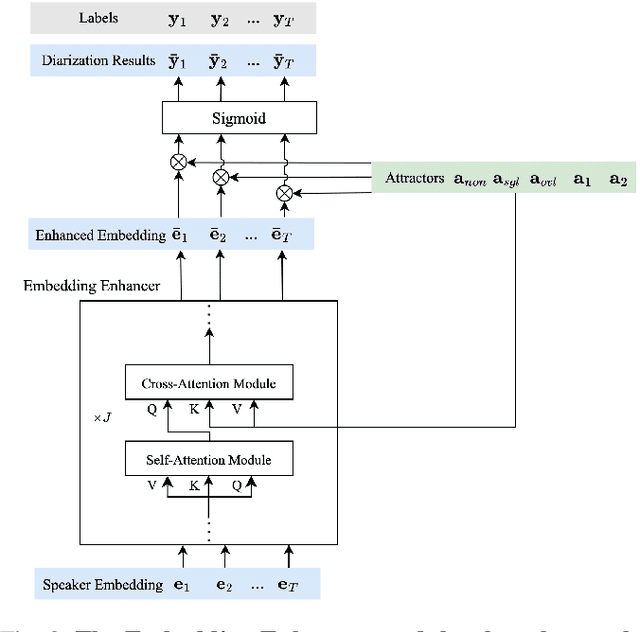


Deep neural network-based systems have significantly improved the performance of speaker diarization tasks. However, end-to-end neural diarization (EEND) systems often struggle to generalize to scenarios with an unseen number of speakers, while target speaker voice activity detection (TS-VAD) systems tend to be overly complex. In this paper, we propose a simple attention-based encoder-decoder network for end-to-end neural diarization (AED-EEND). In our training process, we introduce a teacher-forcing strategy to address the speaker permutation problem, leading to faster model convergence. For evaluation, we propose an iterative decoding method that outputs diarization results for each speaker sequentially. Additionally, we propose an Enhancer module to enhance the frame-level speaker embeddings, enabling the model to handle scenarios with an unseen number of speakers. We also explore replacing the transformer encoder with a Conformer architecture, which better models local information. Furthermore, we discovered that commonly used simulation datasets for speaker diarization have a much higher overlap ratio compared to real data. We found that using simulated training data that is more consistent with real data can achieve an improvement in consistency. Extensive experimental validation demonstrates the effectiveness of our proposed methodologies. Our best system achieved a new state-of-the-art diarization error rate (DER) performance on all the CALLHOME (10.08%), DIHARD II (24.64%), and AMI (13.00%) evaluation benchmarks, when no oracle voice activity detection (VAD) is used. Beyond speaker diarization, our AED-EEND system also shows remarkable competitiveness as a speech type detection model.
Exploring Binary Classification Loss For Speaker Verification
Jul 17, 2023The mismatch between close-set training and open-set testing usually leads to significant performance degradation for speaker verification task. For existing loss functions, metric learning-based objectives depend strongly on searching effective pairs which might hinder further improvements. And popular multi-classification methods are usually observed with degradation when evaluated on unseen speakers. In this work, we introduce SphereFace2 framework which uses several binary classifiers to train the speaker model in a pair-wise manner instead of performing multi-classification. Benefiting from this learning paradigm, it can efficiently alleviate the gap between training and evaluation. Experiments conducted on Voxceleb show that the SphereFace2 outperforms other existing loss functions, especially on hard trials. Besides, large margin fine-tuning strategy is proven to be compatible with it for further improvements. Finally, SphereFace2 also shows its strong robustness to class-wise noisy labels which has the potential to be applied in the semi-supervised training scenario with inaccurate estimated pseudo labels. Codes are available in https://github.com/Hunterhuan/sphereface2_speaker_verification
Wespeaker baselines for VoxSRC2023
Jun 28, 2023



This report showcases the results achieved using the wespeaker toolkit for the VoxSRC2023 Challenge. Our aim is to provide participants, especially those with limited experience, with clear and straightforward guidelines to develop their initial systems. Via well-structured recipes and strong results, we hope to offer an accessible and good enough start point for all interested individuals. In this report, we describe the results achieved on the VoxSRC2023 dev set using the pretrained models, you can check the CodaLab evaluation server for the results on the evaluation set.
Attention-based Encoder-Decoder Network for End-to-End Neural Speaker Diarization with Target Speaker Attractor
May 18, 2023This paper proposes a novel Attention-based Encoder-Decoder network for End-to-End Neural speaker Diarization (AED-EEND). In AED-EEND system, we incorporate the target speaker enrollment information used in target speaker voice activity detection (TS-VAD) to calculate the attractor, which can mitigate the speaker permutation problem and facilitate easier model convergence. In the training process, we propose a teacher-forcing strategy to obtain the enrollment information using the ground-truth label. Furthermore, we propose three heuristic decoding methods to identify the enrollment area for each speaker during the evaluation process. Additionally, we enhance the attractor calculation network LSTM used in the end-to-end encoder-decoder based attractor calculation (EEND-EDA) system by incorporating an attention-based model. By utilizing such an attention-based attractor decoder, our proposed AED-EEND system outperforms both the EEND-EDA and TS-VAD systems with only 0.5s of enrollment data.
Self-Supervised Learning with Cluster-Aware-DINO for High-Performance Robust Speaker Verification
Apr 12, 2023Automatic speaker verification task has made great achievements using deep learning approaches with the large-scale manually annotated dataset. However, it's very difficult and expensive to collect a large amount of well-labeled data for system building. In this paper, we propose a novel and advanced self-supervised learning framework which can construct a high performance speaker verification system without using any labeled data. To avoid the impact of false negative pairs, we adopt the self-distillation with no labels (DINO) framework as the initial model, which can be trained without exploiting negative pairs. Then, we introduce a cluster-aware training strategy for DINO to improve the diversity of data. In the iteration learning stage, due to a mass of unreliable labels from clustering, the quality of pseudo labels is important for the system training. This motivates us to propose dynamic loss-gate and label correction (DLG-LC) methods to alleviate the performance degradation caused by unreliable labels. More specifically, we model the loss distribution with GMM and obtain the loss-gate threshold dynamically to distinguish the reliable and unreliable labels. Besides, we adopt the model predictions to correct the unreliable label, for better utilizing the unreliable data rather than dropping them directly. Moreover, we extend the DLG-LC to multi-modality to further improve the performance. The experiments are performed on the commonly used Voxceleb dataset. Compared to the best-known self-supervised speaker verification system, our proposed method obtain 22.17%, 27.94% and 25.56% relative EER improvement on Vox-O, Vox-E and Vox-H test sets, even with fewer iterations, smaller models, and simpler clustering methods. More importantly, the newly proposed system even achieves comparable results with the fully supervised system, but without using any human labeled data.
Build a SRE Challenge System: Lessons from VoxSRC 2022 and CNSRC 2022
Nov 02, 2022



Different speaker recognition challenges have been held to assess the speaker verification system in the wild and probe the performance limit. Voxceleb Speaker Recognition Challenge (VoxSRC), based on the voxceleb, is the most popular. Besides, another challenge called CN-Celeb Speaker Recognition Challenge (CNSRC) is also held this year, which is based on the Chinese celebrity multi-genre dataset CN-Celeb. This year, our team participated in both speaker verification closed tracks in CNSRC 2022 and VoxSRC 2022, and achieved the 1st place and 3rd place respectively. In most system reports, the authors usually only provide a description of their systems but lack an effective analysis of their methods. In this paper, we will outline how to build a strong speaker verification challenge system and give a detailed analysis of each method compared with some other popular technical means.
Wespeaker: A Research and Production oriented Speaker Embedding Learning Toolkit
Nov 01, 2022



Speaker modeling is essential for many related tasks, such as speaker recognition and speaker diarization. The dominant modeling approach is fixed-dimensional vector representation, i.e., speaker embedding. This paper introduces a research and production oriented speaker embedding learning toolkit, Wespeaker. Wespeaker contains the implementation of scalable data management, state-of-the-art speaker embedding models, loss functions, and scoring back-ends, with highly competitive results achieved by structured recipes which were adopted in the winning systems in several speaker verification challenges. The application to other downstream tasks such as speaker diarization is also exhibited in the related recipe. Moreover, CPU- and GPU-compatible deployment codes are integrated for production-oriented development. The toolkit is publicly available at https://github.com/wenet-e2e/wespeaker.
A comprehensive study on self-supervised distillation for speaker representation learning
Oct 28, 2022



In real application scenarios, it is often challenging to obtain a large amount of labeled data for speaker representation learning due to speaker privacy concerns. Self-supervised learning with no labels has become a more and more promising way to solve it. Compared with contrastive learning, self-distilled approaches use only positive samples in the loss function and thus are more attractive. In this paper, we present a comprehensive study on self-distilled self-supervised speaker representation learning, especially on critical data augmentation. Our proposed strategy of audio perturbation augmentation has pushed the performance of the speaker representation to a new limit. The experimental results show that our model can achieve a new SoTA on Voxceleb1 speaker verification evaluation benchmark ( i.e., equal error rate (EER) 2.505%, 2.473%, and 4.791% for trial Vox1-O, Vox1-E and Vox1-H , respectively), discarding any speaker labels in the training phase.
SJTU-AISPEECH System for VoxCeleb Speaker Recognition Challenge 2022
Sep 20, 2022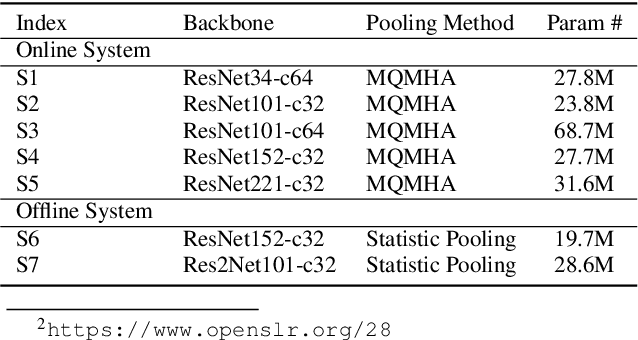
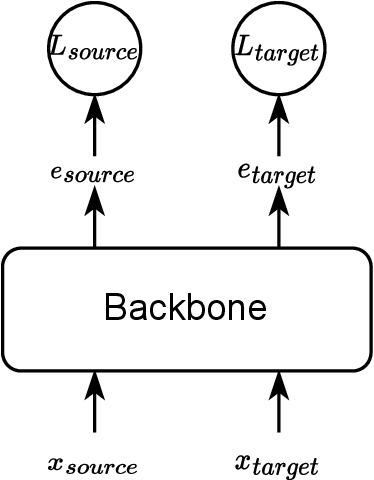
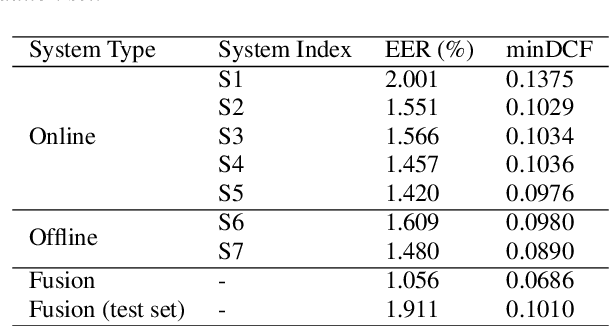

This report describes the SJTU-AISPEECH system for the Voxceleb Speaker Recognition Challenge 2022. For track1, we implemented two kinds of systems, the online system and the offline system. Different ResNet-based backbones and loss functions are explored. Our final fusion system achieved 3rd place in track1. For track3, we implemented statistic adaptation and jointly training based domain adaptation. In the jointly training based domain adaptation, we jointly trained the source and target domain dataset with different training objectives to do the domain adaptation. We explored two different training objectives for target domain data, self-supervised learning based angular proto-typical loss and semi-supervised learning based classification loss with estimated pseudo labels. Besides, we used the dynamic loss-gate and label correction (DLG-LC) strategy to improve the quality of pseudo labels when the target domain objective is a classification loss. Our final fusion system achieved 4th place (very close to 3rd place, relatively less than 1%) in track3.
The SJTU System for Short-duration Speaker Verification Challenge 2021
Aug 03, 2022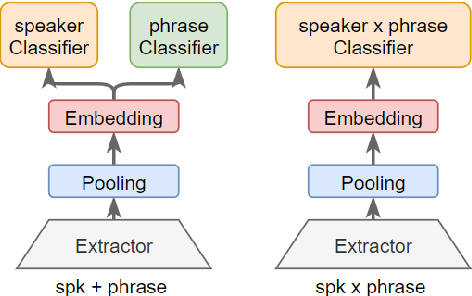
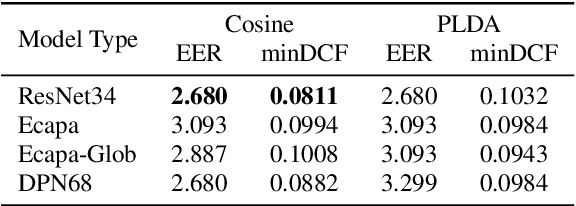
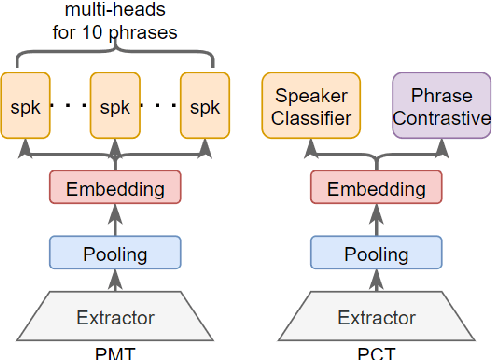
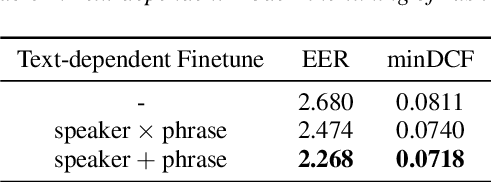
This paper presents the SJTU system for both text-dependent and text-independent tasks in short-duration speaker verification (SdSV) challenge 2021. In this challenge, we explored different strong embedding extractors to extract robust speaker embedding. For text-independent task, language-dependent adaptive snorm is explored to improve the system performance under the cross-lingual verification condition. For text-dependent task, we mainly focus on the in-domain fine-tuning strategies based on the model pre-trained on large-scale out-of-domain data. In order to improve the distinction between different speakers uttering the same phrase, we proposed several novel phrase-aware fine-tuning strategies and phrase-aware neural PLDA. With such strategies, the system performance is further improved. Finally, we fused the scores of different systems, and our fusion systems achieved 0.0473 in Task1 (rank 3) and 0.0581 in Task2 (rank 8) on the primary evaluation metric.