 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Priors for Implicit Preferences: Decoupling Skill Selection as a Local Harness in Personal Agents
Jun 04, 2026As Large Language Model (LLM) capabilities advance, locally deployed personal agents relying on API-based remote models and external skills have emerged as a novel paradigm. With the rapid expansion of available skills, enabling personal agents to learn and adapt to implicit user preferences becomes a critical challenge. However, local deployment constraints preclude complex centralized selection algorithms, creating an urgent need for a lightweight local preference harness. This paper explores the implementation of such a harness through a novel architecture that strictly decouples statistical preference learning from semantic intent parsing. Specifically, we leverage localized statistical results to influence and modulate the selection decisions of the remote LLM. Extensive evaluations demonstrate that our decoupled approach achieves the lowest cumulative regret and highest test accuracy, significantly outperforming traditional memory-augmented agents.
Beyond the Black Box: Theory and Mechanism of Large Language Models
Jan 06, 2026The rapid emergence of Large Language Models (LLMs) has precipitated a profound paradigm shift in Artificial Intelligence, delivering monumental engineering successes that increasingly impact modern society. However, a critical paradox persists within the current field: despite the empirical efficacy, our theoretical understanding of LLMs remains disproportionately nascent, forcing these systems to be treated largely as ``black boxes''. To address this theoretical fragmentation, this survey proposes a unified lifecycle-based taxonomy that organizes the research landscape into six distinct stages: Data Preparation, Model Preparation, Training, Alignment, Inference, and Evaluation. Within this framework, we provide a systematic review of the foundational theories and internal mechanisms driving LLM performance. Specifically, we analyze core theoretical issues such as the mathematical justification for data mixtures, the representational limits of various architectures, and the optimization dynamics of alignment algorithms. Moving beyond current best practices, we identify critical frontier challenges, including the theoretical limits of synthetic data self-improvement, the mathematical bounds of safety guarantees, and the mechanistic origins of emergent intelligence. By connecting empirical observations with rigorous scientific inquiry, this work provides a structured roadmap for transitioning LLM development from engineering heuristics toward a principled scientific discipline.
Information Gain-based Policy Optimization: A Simple and Effective Approach for Multi-Turn LLM Agents
Oct 16, 2025Large language model (LLM)-based agents are increasingly trained with reinforcement learning (RL) to enhance their ability to interact with external environments through tool use, particularly in search-based settings that require multi-turn reasoning and knowledge acquisition. However, existing approaches typically rely on outcome-based rewards that are only provided at the final answer. This reward sparsity becomes particularly problematic in multi-turn settings, where long trajectories exacerbate two critical issues: (i) advantage collapse, where all rollouts receive identical rewards and provide no useful learning signals, and (ii) lack of fine-grained credit assignment, where dependencies between turns are obscured, especially in long-horizon tasks. In this paper, we propose Information Gain-based Policy Optimization (IGPO), a simple yet effective RL framework that provides dense and intrinsic supervision for multi-turn agent training. IGPO models each interaction turn as an incremental process of acquiring information about the ground truth, and defines turn-level rewards as the marginal increase in the policy's probability of producing the correct answer. Unlike prior process-level reward approaches that depend on external reward models or costly Monte Carlo estimation, IGPO derives intrinsic rewards directly from the model's own belief updates. These intrinsic turn-level rewards are combined with outcome-level supervision to form dense reward trajectories. Extensive experiments on both in-domain and out-of-domain benchmarks demonstrate that IGPO consistently outperforms strong baselines in multi-turn scenarios, achieving higher accuracy and improved sample efficiency.
CoT-Space: A Theoretical Framework for Internal Slow-Thinking via Reinforcement Learning
Sep 04, 2025Reinforcement Learning (RL) has become a pivotal approach for enhancing the reasoning capabilities of Large Language Models (LLMs). However, a significant theoretical gap persists, as traditional token-level RL frameworks fail to align with the reasoning-level nature of complex, multi-step thought processes like Chain-of-Thought (CoT). To address this challenge, we introduce CoT-Space, a novel theoretical framework that recasts LLM reasoning from a discrete token-prediction task to an optimization process within a continuous, reasoning-level semantic space. By analyzing this process from both a noise perspective and a risk perspective, we demonstrate that the convergence to an optimal CoT length is a natural consequence of the fundamental trade-off between underfitting and overfitting. Furthermore, extensive experiments provide strong empirical validation for our theoretical findings. Our framework not only provides a coherent explanation for empirical phenomena such as overthinking but also offers a solid theoretical foundation to guide the future development of more effective and generalizable reasoning agents.
Rethinking External Slow-Thinking: From Snowball Errors to Probability of Correct Reasoning
Jan 26, 2025
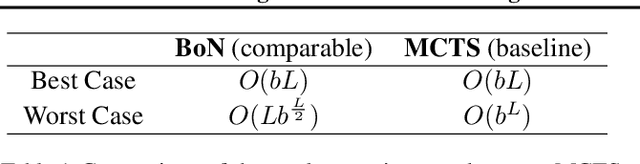


Test-time scaling, which is also often referred to as \textit{slow-thinking}, has been demonstrated to enhance multi-step reasoning in large language models (LLMs). However, despite its widespread utilization, the mechanisms underlying slow-thinking methods remain poorly understood. This paper explores the mechanisms of external slow-thinking from a theoretical standpoint. We begin by examining the snowball error effect within the LLM reasoning process and connect it to the likelihood of correct reasoning using information theory. Building on this, we show that external slow-thinking methods can be interpreted as strategies to mitigate the error probability. We further provide a comparative analysis of popular external slow-thinking approaches, ranging from simple to complex, highlighting their differences and interrelationships. Our findings suggest that the efficacy of these methods is not primarily determined by the specific framework employed, and that expanding the search scope or the model's internal reasoning capacity may yield more sustained improvements in the long term. We open-source our code at \url{https://github.com/ZyGan1999/Snowball-Errors-and-Probability}.