 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Steering Vector: Flow-based Activation Steering for Inference-Time Intervention
May 07, 2026Activation steering has emerged as a promising alternative for controlling language-model behavior at inference time by modifying intermediate representations while keeping model parameters frozen. However, large-scale evaluations such as AxBench show that existing steering methods are often outperformed by simple in-context prompting and generalize poorly to unseen concepts. We hypothesize that these limitations arise from unvalidated simplifying assumptions shared across prior methods, which typically restrict steering interventions to fixed, single-step, position-invariant transforms. We propose FLAS (Flow-based Activation Steering), which learns a general, concept-conditioned velocity field $v_t(h,t,c)$ that transports unsteered activations to steered ones without relying on these assumptions. On AxBench, FLAS is the first learned method to consistently outperform prompting, reaching held-out harmonic means of $1.015$ on Gemma-2-2B-IT and $1.113$ on Gemma-2-9B-IT without per-concept tuning. Analysis of the learned flow shows curved, multi-step, token-varying trajectories, which suggests that previous hypotheses on activation space geometry might be incomplete.
Stochastic Attention: Connectome-Inspired Randomized Routing for Expressive Linear-Time Attention
Apr 01, 2026The whole-brain connectome of a fruit fly comprises over 130K neurons connected with a probability of merely 0.02%, yet achieves an average shortest path of only 4.4 hops. Despite being highly structured at the circuit level, the network's long-range connections are broadly distributed across brain regions, functioning as stochastic shortcuts that enable efficient global communication. Inspired by this observation, we propose Stochastic Attention (SA), a drop-in enhancement for sliding-window attention (SWA) that applies a random permutation to the token sequence before windowed attention and restores the original order afterward. This transforms the fixed local window into a stochastic global one within the same $O(nw)$ per-layer budget. Through depth, independently sampled permutations yield exponentially growing receptive fields, achieving full sequence coverage in $O(\log_w n)$ layers versus $O(n/w)$ for SWA. We validate SA in two settings: pre-training language models from scratch, where a gated SA + SWA combination achieves the best average zero-shot accuracy, and training-free inference on Qwen3-8B and Qwen3-30B-A3B, where SA consistently outperforms SWA and matches or exceeds Mixture of Block Attention at comparable compute budgets. These results suggest that connectome-inspired stochastic routing is a practical primitive for improving the expressivity of efficient attention, complementary to existing linear and sparse approaches.
Learning Principle of Least Action with Reinforcement Learning
Nov 26, 2020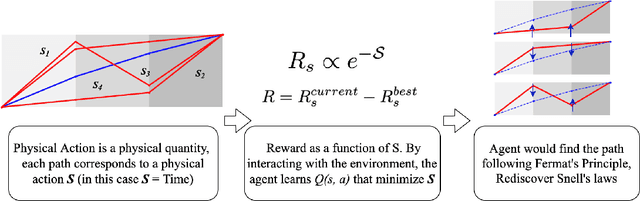
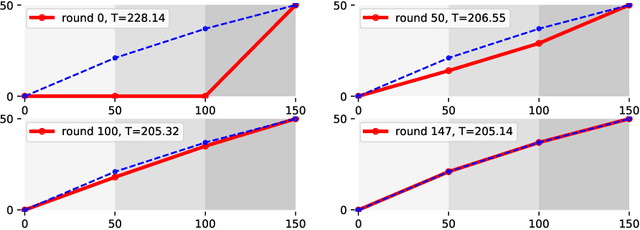
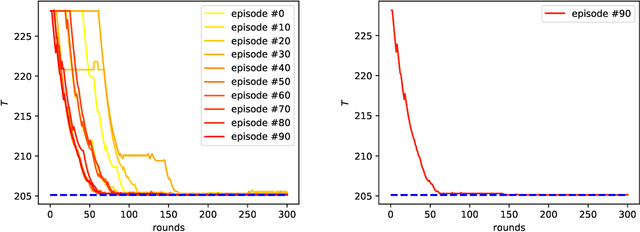
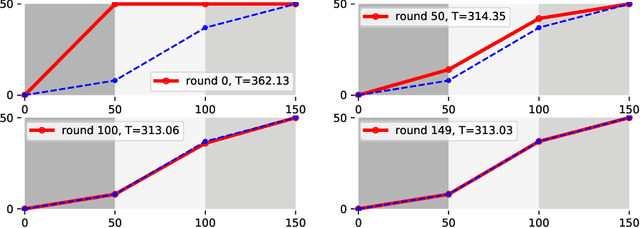
Nature provides a way to understand physics with reinforcement learning since nature favors the economical way for an object to propagate. In the case of classical mechanics, nature favors the object to move along the path according to the integral of the Lagrangian, called the action $\mathcal{S}$. We consider setting the reward/penalty as a function of $\mathcal{S}$, so the agent could learn the physical trajectory of particles in various kinds of environments with reinforcement learning. In this work, we verified the idea by using a Q-Learning based algorithm on learning how light propagates in materials with different refraction indices, and show that the agent could recover the minimal-time path equivalent to the solution obtained by Snell's law or Fermat's Principle. We also discuss the similarity of our reinforcement learning approach to the path integral formalism.