 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinically Meaningful Comparisons Over Time: An Approach to Measuring Patient Similarity based on Subsequence Alignment
Mar 02, 2018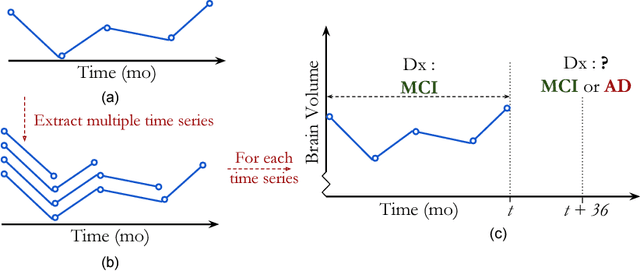

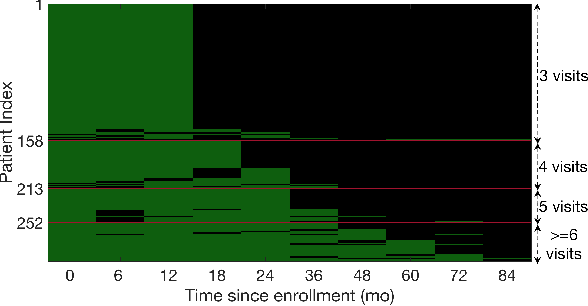
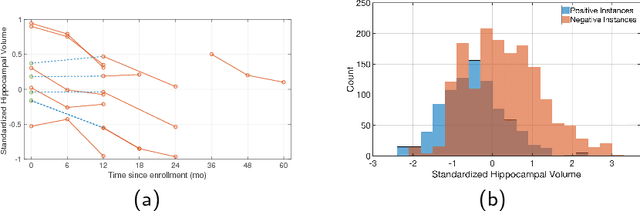
Longitudinal patient data has the potential to improve clinical risk stratification models for disease. However, chronic diseases that progress slowly over time are often heterogeneous in their clinical presentation. Patients may progress through disease stages at varying rates. This leads to pathophysiological misalignment over time, making it difficult to consistently compare patients in a clinically meaningful way. Furthermore, patients present clinically for the first time at different stages of disease. This eliminates the possibility of simply aligning patients based on their initial presentation. Finally, patient data may be sampled at different rates due to differences in schedules or missed visits. To address these challenges, we propose a robust measure of patient similarity based on subsequence alignment. Compared to global alignment techniques that do not account for pathophysiological misalignment, focusing on the most relevant subsequences allows for an accurate measure of similarity between patients. We demonstrate the utility of our approach in settings where longitudinal data, while useful, are limited and lack a clear temporal alignment for comparison. Applied to the task of stratifying patients for risk of progression to probable Alzheimer's Disease, our approach outperforms models that use only snapshot data (AUROC of 0.839 vs. 0.812) and models that use global alignment techniques (AUROC of 0.822). Our results support the hypothesis that patients' trajectories are useful for quantifying inter-patient similarities and that using subsequence matching and can help account for heterogeneity and misalignment in longitudinal data.
Uncovering Voice Misuse Using Symbolic Mismatch
Aug 08, 2016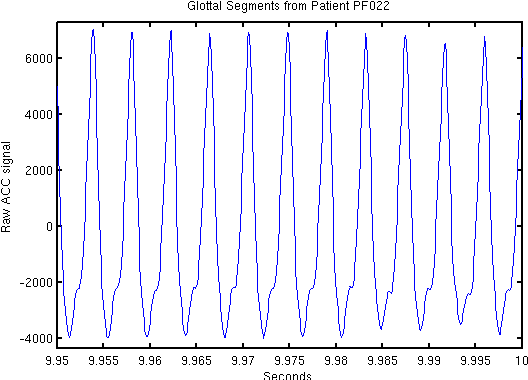
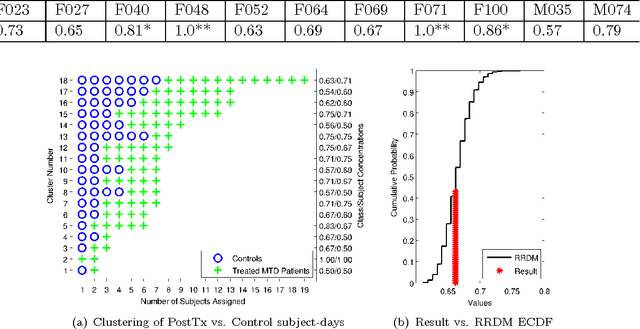
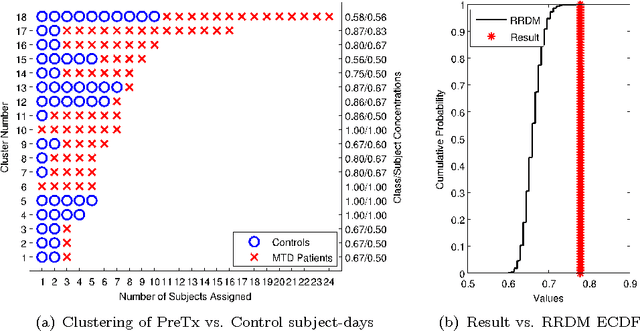
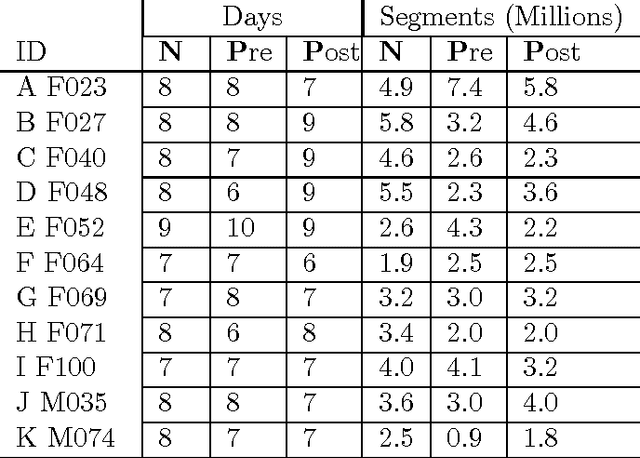
Voice disorders affect an estimated 14 million working-aged Americans, and many more worldwide. We present the first large scale study of vocal misuse based on long-term ambulatory data collected by an accelerometer placed on the neck. We investigate an unsupervised data mining approach to uncovering latent information about voice misuse. We segment signals from over 253 days of data from 22 subjects into over a hundred million single glottal pulses (closures of the vocal folds), cluster segments into symbols, and use symbolic mismatch to uncover differences between patients and matched controls, and between patients pre- and post-treatment. Our results show significant behavioral differences between patients and controls, as well as between some pre- and post-treatment patients. Our proposed approach provides an objective basis for helping diagnose behavioral voice disorders, and is a first step towards a more data-driven understanding of the impact of voice therapy.