 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCathAI: Fully Automated Interpretation of Coronary Angiograms Using Neural Networks
Jun 14, 2021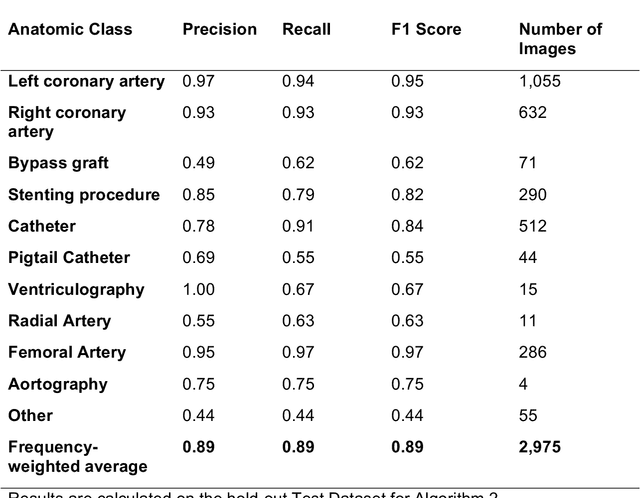
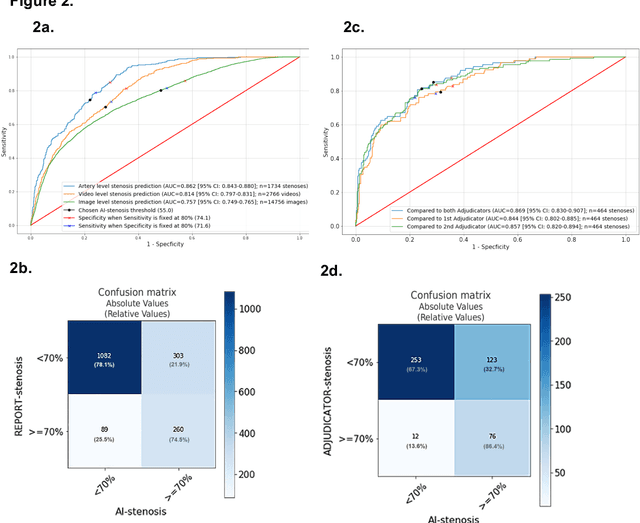
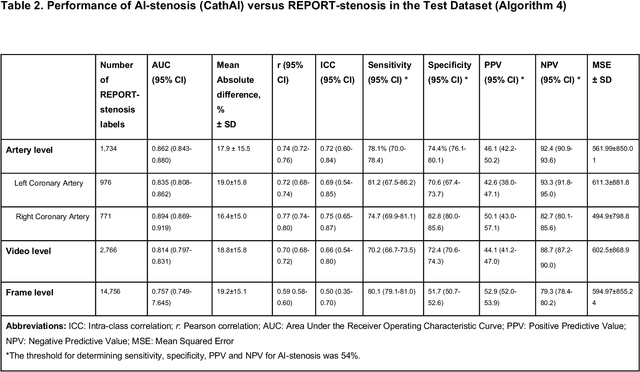
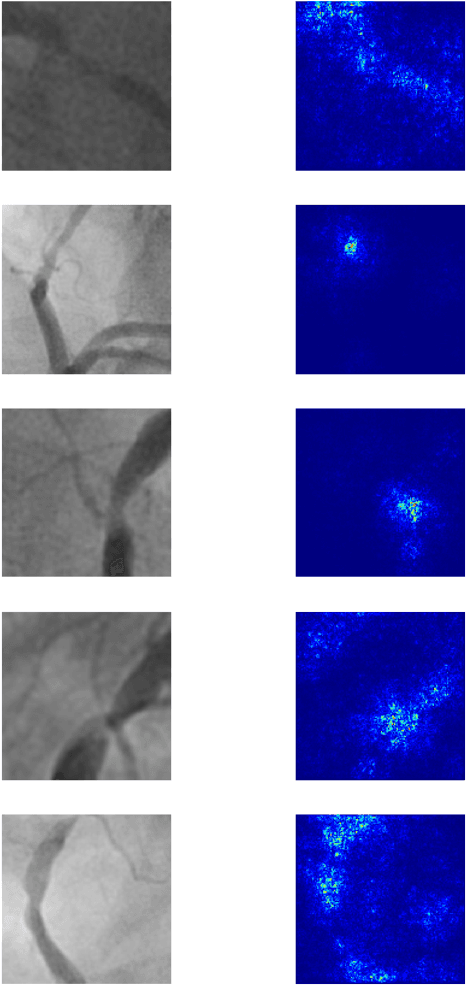
Coronary heart disease (CHD) is the leading cause of adult death in the United States and worldwide, and for which the coronary angiography procedure is the primary gateway for diagnosis and clinical management decisions. The standard-of-care for interpretation of coronary angiograms depends upon ad-hoc visual assessment by the physician operator. However, ad-hoc visual interpretation of angiograms is poorly reproducible, highly variable and bias prone. Here we show for the first time that fully-automated angiogram interpretation to estimate coronary artery stenosis is possible using a sequence of deep neural network algorithms. The algorithmic pipeline we developed--called CathAI--achieves state-of-the art performance across the sequence of tasks required to accomplish automated interpretation of unselected, real-world angiograms. CathAI (Algorithms 1-2) demonstrated positive predictive value, sensitivity and F1 score of >=90% to identify the projection angle overall and >=93% for left or right coronary artery angiogram detection, the primary anatomic structures of interest. To predict obstructive coronary artery stenosis (>=70% stenosis), CathAI (Algorithm 4) exhibited an area under the receiver operating characteristic curve (AUC) of 0.862 (95% CI: 0.843-0.880). When externally validated in a healthcare system in another country, CathAI AUC was 0.869 (95% CI: 0.830-0.907) to predict obstructive coronary artery stenosis. Our results demonstrate that multiple purpose-built neural networks can function in sequence to accomplish the complex series of tasks required for automated analysis of real-world angiograms. Deployment of CathAI may serve to increase standardization and reproducibility in coronary stenosis assessment, while providing a robust foundation to accomplish future tasks for algorithmic angiographic interpretation.
Machine Learning at Microsoft with ML .NET
May 15, 2019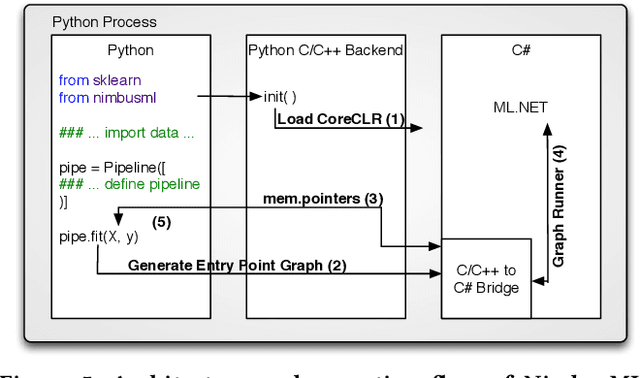
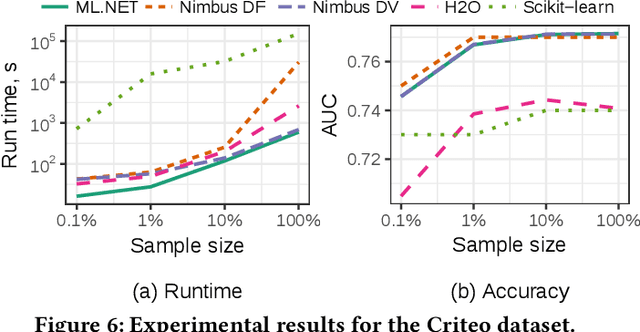
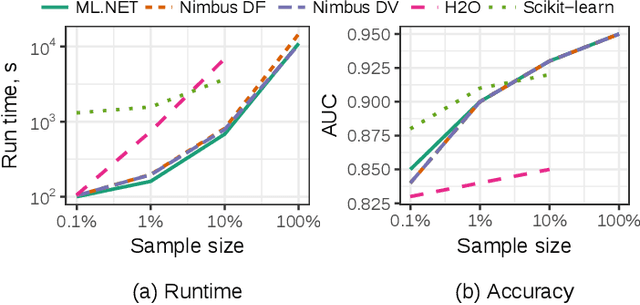
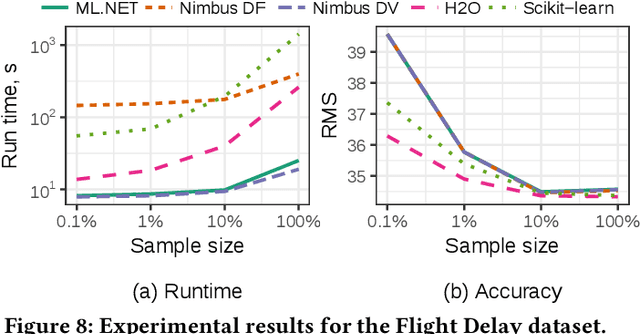
Machine Learning is transitioning from an art and science into a technology available to every developer. In the near future, every application on every platform will incorporate trained models to encode data-based decisions that would be impossible for developers to author. This presents a significant engineering challenge, since currently data science and modeling are largely decoupled from standard software development processes. This separation makes incorporating machine learning capabilities inside applications unnecessarily costly and difficult, and furthermore discourage developers from embracing ML in first place. In this paper we present ML .NET, a framework developed at Microsoft over the last decade in response to the challenge of making it easy to ship machine learning models in large software applications. We present its architecture, and illuminate the application demands that shaped it. Specifically, we introduce DataView, the core data abstraction of ML .NET which allows it to capture full predictive pipelines efficiently and consistently across training and inference lifecycles. We close the paper with a surprisingly favorable performance study of ML .NET compared to more recent entrants, and a discussion of some lessons learned.
Image-based Face Detection and Recognition: "State of the Art"
Feb 26, 2013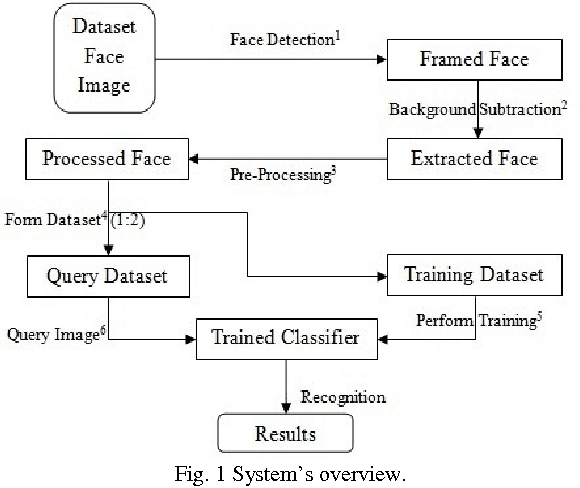
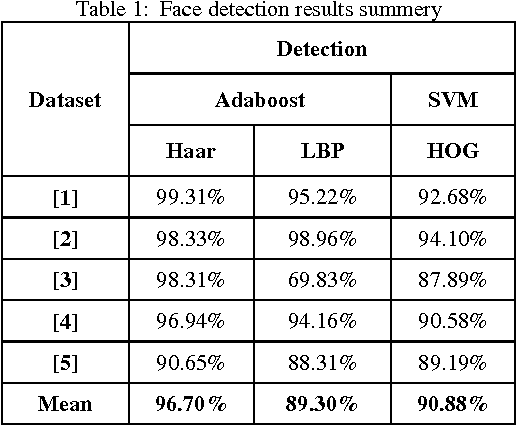
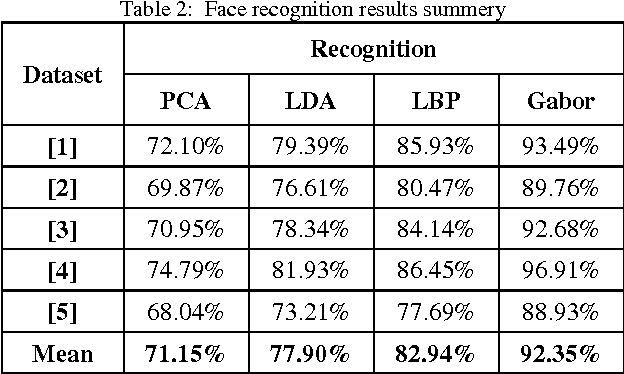

Face recognition from image or video is a popular topic in biometrics research. Many public places usually have surveillance cameras for video capture and these cameras have their significant value for security purpose. It is widely acknowledged that the face recognition have played an important role in surveillance system as it doesn't need the object's cooperation. The actual advantages of face based identification over other biometrics are uniqueness and acceptance. As human face is a dynamic object having high degree of variability in its appearance, that makes face detection a difficult problem in computer vision. In this field, accuracy and speed of identification is a main issue. The goal of this paper is to evaluate various face detection and recognition methods, provide complete solution for image based face detection and recognition with higher accuracy, better response rate as an initial step for video surveillance. Solution is proposed based on performed tests on various face rich databases in terms of subjects, pose, emotions, race and light.
* 4 pages, 3 table, 4 figure
Proposing LT based Search in PDM Systems for Better Information Retrieval
Feb 09, 2011
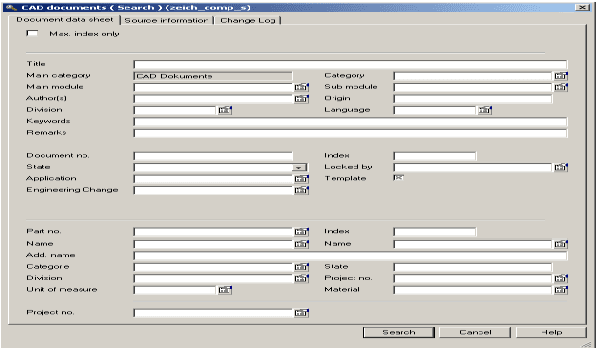

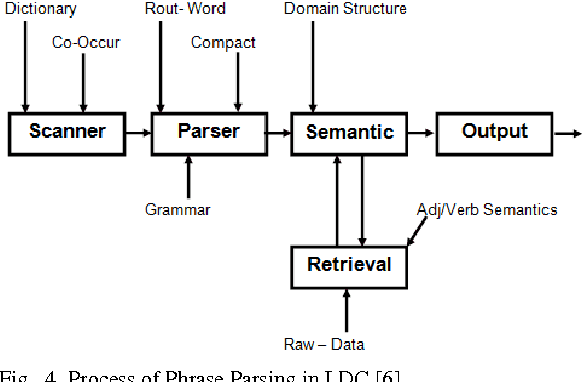
PDM Systems contain and manage heavy amount of data but the search mechanism of most of the systems is not intelligent which can process user"s natural language based queries to extract desired information. Currently available search mechanisms in almost all of the PDM systems are not very efficient and based on old ways of searching information by entering the relevant information to the respective fields of search forms to find out some specific information from attached repositories. Targeting this issue, a thorough research was conducted in fields of PDM Systems and Language Technology. Concerning the PDM System, conducted research provides the information about PDM and PDM Systems in detail. Concerning the field of Language Technology, helps in implementing a search mechanism for PDM Systems to search user"s needed information by analyzing user"s natural language based requests. The accomplished goal of this research was to support the field of PDM with a new proposition of a conceptual model for the implementation of natural language based search. The proposed conceptual model is successfully designed and partially implementation in the form of a prototype. Describing the proposition in detail the main concept, implementation designs and developed prototype of proposed approach is discussed in this paper. Implemented prototype is compared with respective functions of existing PDM systems .i.e., Windchill and CIM to evaluate its effectiveness against targeted challenges.
* 15 pages, 31 figures
Integration of Agile Ontology Mapping towards NLP Search in I-SOAS
Nov 14, 2010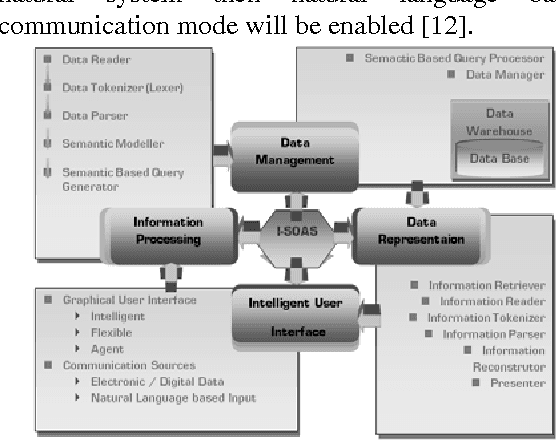
In this research paper we address the importance of Product Data Management (PDM) with respect to its contributions in industry. Moreover we also present some currently available major challenges to PDM communities and targeting some of these challenges we present an approach i.e. I-SOAS, and briefly discuss how this approach can be helpful in solving the PDM community's faced problems. Furthermore, limiting the scope of this research to one challenge, we focus on the implementation of a semantic based search mechanism in PDM Systems. Going into the details, at first we describe the respective field i.e. Language Technology (LT), contributing towards natural language processing, to take advantage in implementing a search engine capable of understanding the semantic out of natural language based search queries. Then we discuss how can we practically take advantage of LT by implementing its concepts in the form of software application with the use of semantic web technology i.e. Ontology. Later, in the end of this research paper, we briefly present a prototype application developed with the use of concepts of LT towards semantic based search.
Integration of Flexible Web Based GUI in I-SOAS
Nov 14, 2010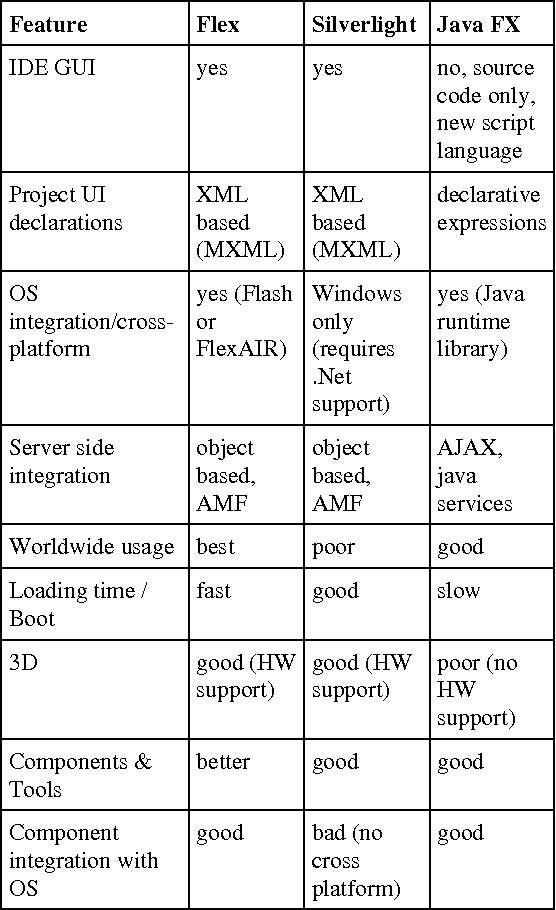
It is necessary to improve the concepts of the present web based graphical user interface for the development of more flexible and intelligent interface to provide ease and increase the level of comfort at user end like most of the desktop based applications. This research is conducted targeting the goal of implementing flexible GUI consisting of a visual component manager with different components by functionality, design and purpose. In this research paper we present a Rich Internet Application (RIA) based graphical user interface for web based product development, and going into the details we present a comparison between existing RIA Technologies, adopted methodology in the GUI development and developed prototype.
AI 3D Cybug Gaming
Sep 10, 2010In this short paper I briefly discuss 3D war Game based on artificial intelligence concepts called AI WAR. Going in to the details, I present the importance of CAICL language and how this language is used in AI WAR. Moreover I also present a designed and implemented 3D War Cybug for AI WAR using CAICL and discus the implemented strategy to defeat its enemies during the game life.
Towards Design and Implementation of a Language Technology based Information Processor for PDM Systems
Aug 08, 2010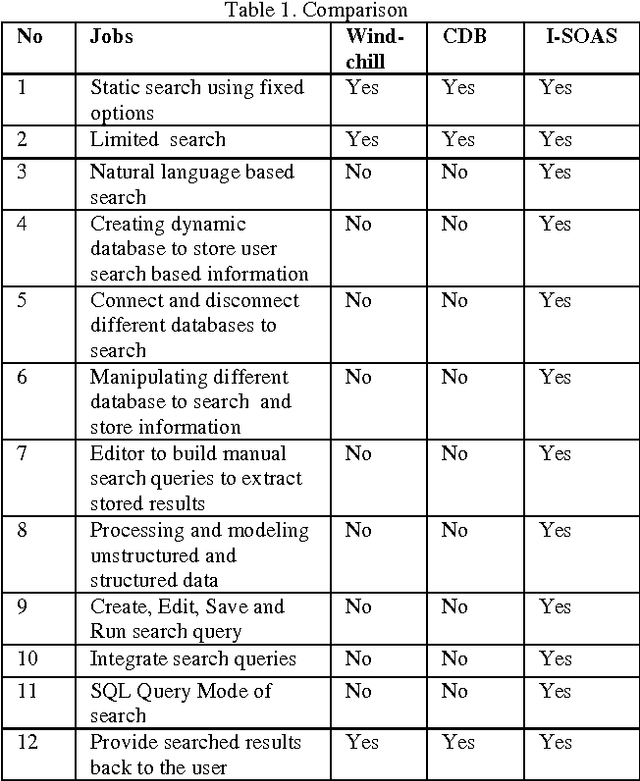
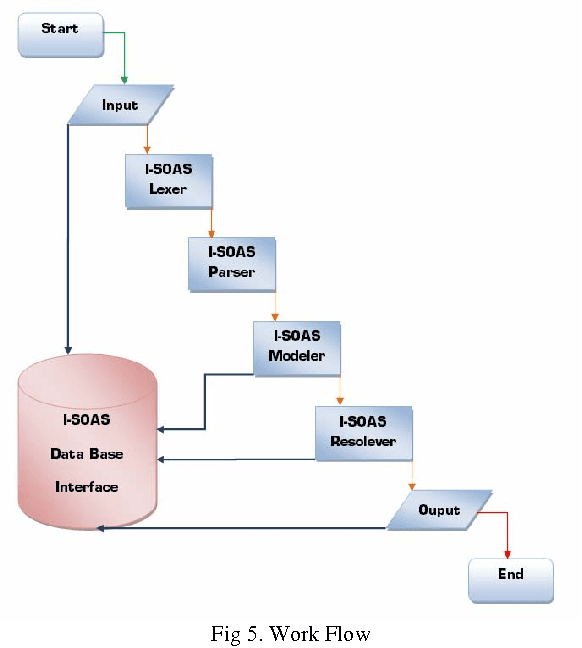
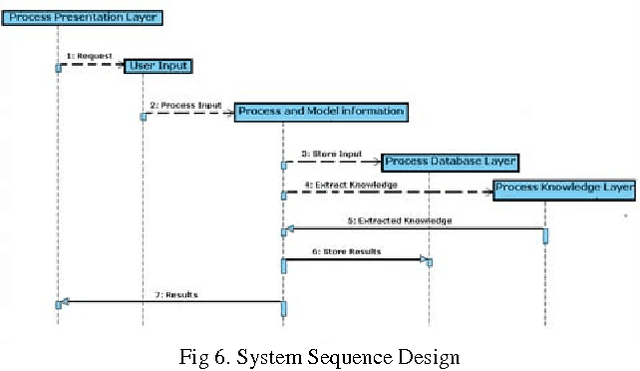
Product Data Management (PDM) aims to provide 'Systems' contributing in industries by electronically maintaining organizational data, improving data repository system, facilitating with easy access to CAD and providing additional information engineering and management modules to access, store, integrate, secure, recover and manage information. Targeting one of the unresolved issues i.e., provision of natural language based processor for the implementation of an intelligent record search mechanism, an approach is proposed and discussed in detail in this manuscript. Designing an intelligent application capable of reading and analyzing user's structured and unstructured natural language based text requests and then extracting desired concrete and optimized results from knowledge base is still a challenging task for the designers because it is still very difficult to completely extract Meta data out of raw data. Residing within the limited scope of current research and development; we present an approach capable of reading user's natural language based input text, understanding the semantic and extracting results from repositories. To evaluate the effectiveness of implemented prototyped version of proposed approach, it is compared with some existing PDM Systems, in the end the discussion is concluded with an abstract presentation of resultant comparison amongst implemented prototype and some existing PDM Systems.
Role of Ontology in Semantic Web Development
Aug 07, 2010World Wide Web (WWW) is the most popular global information sharing and communication system consisting of three standards .i.e., Uniform Resource Identifier (URL), Hypertext Transfer Protocol (HTTP) and Hypertext Mark-up Language (HTML). Information is provided in text, image, audio and video formats over the web by using HTML which is considered to be unconventional in defining and formalizing the meaning of the context...
An Agent based Approach towards Metadata Extraction, Modelling and Information Retrieval over the Web
Aug 07, 2010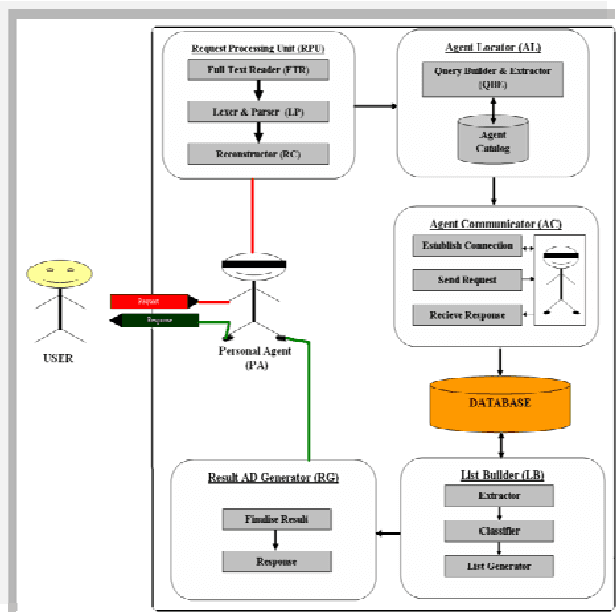
Web development is a challenging research area for its creativity and complexity. The existing raised key challenge in web technology technologic development is the presentation of data in machine read and process able format to take advantage in knowledge based information extraction and maintenance. Currently it is not possible to search and extract optimized results using full text queries because there is no such mechanism exists which can fully extract the semantic from full text queries and then look for particular knowledge based information.