 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy Regularized Optimal Transport Independence Criterion
Dec 31, 2021
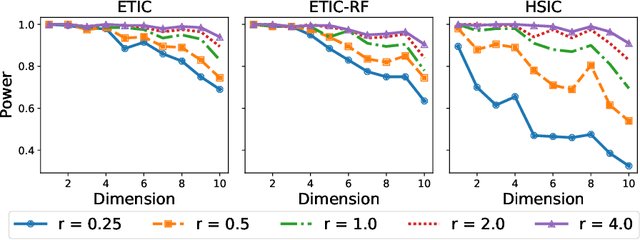
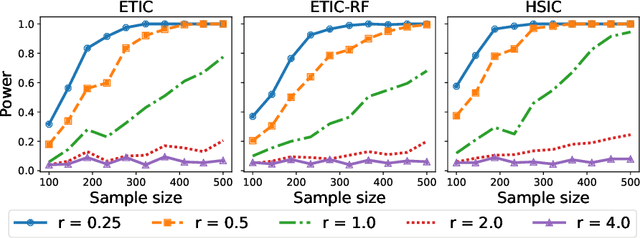
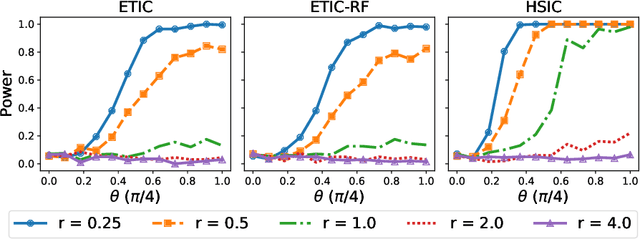
Optimal transport (OT) and its entropy regularized offspring have recently gained a lot of attention in both machine learning and AI domains. In particular, optimal transport has been used to develop probability metrics between probability distributions. We introduce in this paper an independence criterion based on entropy regularized optimal transport. Our criterion can be used to test for independence between two samples. We establish non-asymptotic bounds for our test statistic, and study its statistical behavior under both the null and alternative hypothesis. Our theoretical results involve tools from U-process theory and optimal transport theory. We present experimental results on existing benchmarks, illustrating the interest of the proposed criterion.
Federated Learning with Heterogeneous Data: A Superquantile Optimization Approach
Dec 17, 2021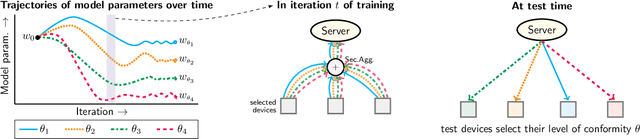

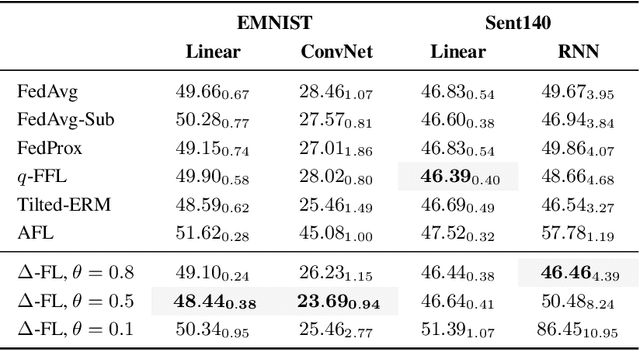
We present a federated learning framework that is designed to robustly deliver good predictive performance across individual clients with heterogeneous data. The proposed approach hinges upon a superquantile-based learning objective that captures the tail statistics of the error distribution over heterogeneous clients. We present a stochastic training algorithm which interleaves differentially private client reweighting steps with federated averaging steps. The proposed algorithm is supported with finite time convergence guarantees that cover both convex and non-convex settings. Experimental results on benchmark datasets for federated learning demonstrate that our approach is competitive with classical ones in terms of average error and outperforms them in terms of tail statistics of the error.
Target Propagation via Regularized Inversion
Dec 02, 2021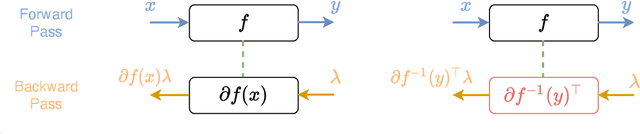

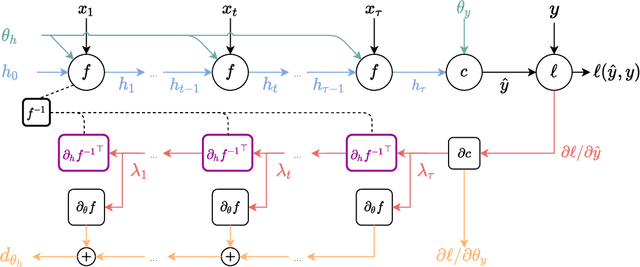
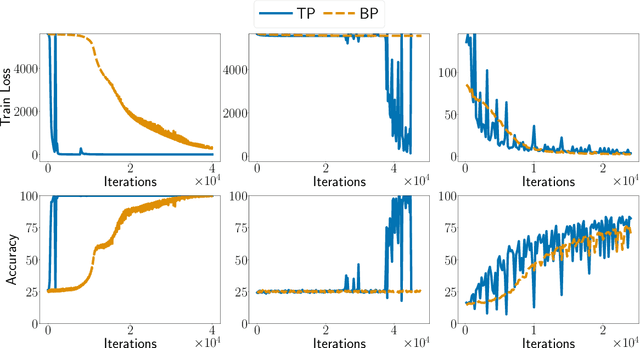
Target Propagation (TP) algorithms compute targets instead of gradients along neural networks and propagate them backward in a way that is similar yet different than gradient back-propagation (BP). The idea was first presented as a perturbative alternative to back-propagation that may achieve greater accuracy in gradient evaluation when training multi-layer neural networks (LeCun et al., 1989). However, TP has remained more of a template algorithm with many variations than a well-identified algorithm. Revisiting insights of LeCun et al., (1989) and more recently of Lee et al. (2015), we present a simple version of target propagation based on regularized inversion of network layers, easily implementable in a differentiable programming framework. We compare its computational complexity to the one of BP and delineate the regimes in which TP can be attractive compared to BP. We show how our TP can be used to train recurrent neural networks with long sequences on various sequence modeling problems. The experimental results underscore the importance of regularization in TP in practice.
Stochastic optimization under time drift: iterate averaging, step decay, and high probability guarantees
Aug 16, 2021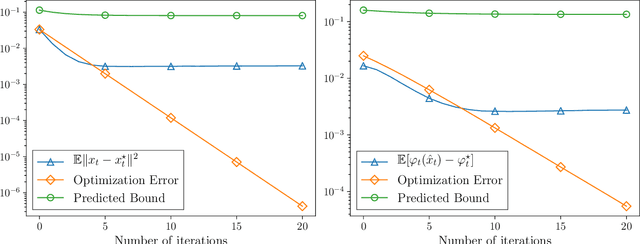
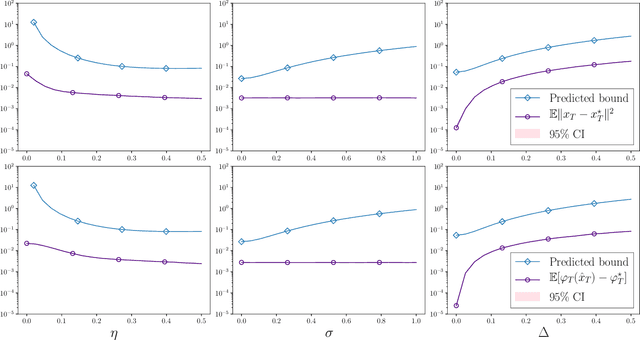
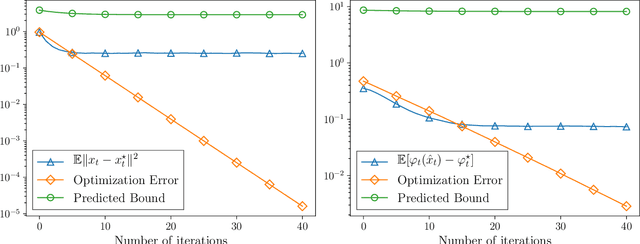
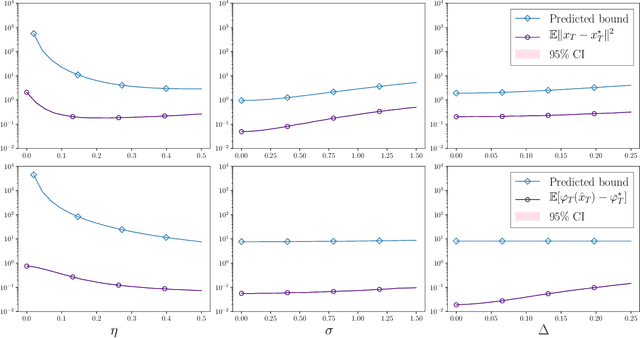
We consider the problem of minimizing a convex function that is evolving in time according to unknown and possibly stochastic dynamics. Such problems abound in the machine learning and signal processing literature, under the names of concept drift and stochastic tracking. We provide novel non-asymptotic convergence guarantees for stochastic algorithms with iterate averaging, focusing on bounds valid both in expectation and with high probability. Notably, we show that the tracking efficiency of the proximal stochastic gradient method depends only logarithmically on the initialization quality, when equipped with a step-decay schedule. The results moreover naturally extend to settings where the dynamics depend jointly on time and on the decision variable itself, as in the performative prediction framework.
Score-Based Change Detection for Gradient-Based Learning Machines
Jun 27, 2021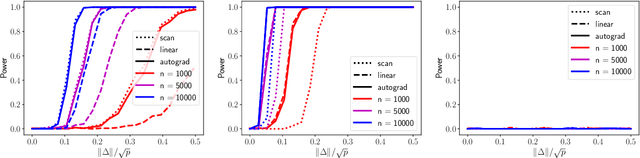

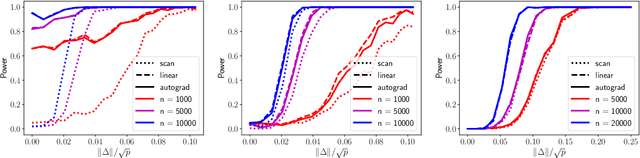

The widespread use of machine learning algorithms calls for automatic change detection algorithms to monitor their behavior over time. As a machine learning algorithm learns from a continuous, possibly evolving, stream of data, it is desirable and often critical to supplement it with a companion change detection algorithm to facilitate its monitoring and control. We present a generic score-based change detection method that can detect a change in any number of components of a machine learning model trained via empirical risk minimization. This proposed statistical hypothesis test can be readily implemented for such models designed within a differentiable programming framework. We establish the consistency of the hypothesis test and show how to calibrate it to achieve a prescribed false alarm rate. We illustrate the versatility of the approach on synthetic and real data.
Divergence Frontiers for Generative Models: Sample Complexity, Quantization Level, and Frontier Integral
Jun 15, 2021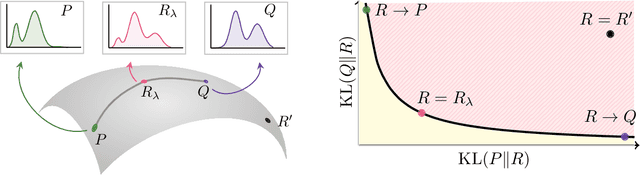
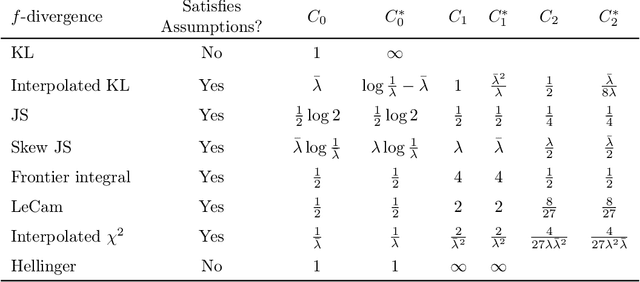
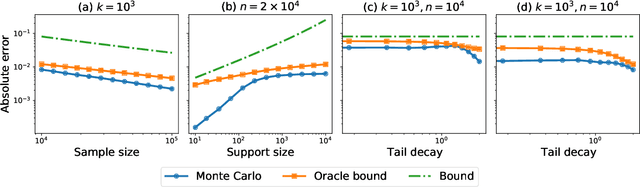
The spectacular success of deep generative models calls for quantitative tools to measure their statistical performance. Divergence frontiers have recently been proposed as an evaluation framework for generative models, due to their ability to measure the quality-diversity trade-off inherent to deep generative modeling. However, the statistical behavior of divergence frontiers estimated from data remains unknown to this day. In this paper, we establish non-asymptotic bounds on the sample complexity of the plug-in estimator of divergence frontiers. Along the way, we introduce a novel integral summary of divergence frontiers. We derive the corresponding non-asymptotic bounds and discuss the choice of the quantization level by balancing the two types of approximation errors arisen from its computation. We also augment the divergence frontier framework by investigating the statistical performance of smoothed distribution estimators such as the Good-Turing estimator. We illustrate the theoretical results with numerical examples from natural language processing and computer vision.
MAUVE: Human-Machine Divergence Curves for Evaluating Open-Ended Text Generation
Feb 02, 2021
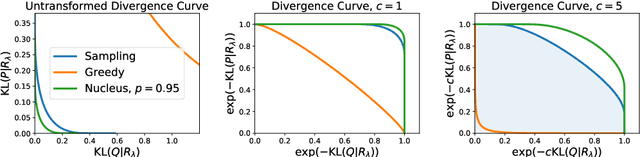
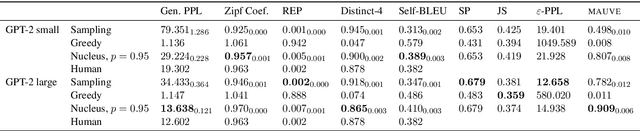
Despite major advances in open-ended text generation, there has been limited progress in designing evaluation metrics for this task. We propose MAUVE -- a metric for open-ended text generation, which directly compares the distribution of machine-generated text to that of human language. MAUVE measures the mean area under the divergence curve for the two distributions, exploring the trade-off between two types of errors: those arising from parts of the human distribution that the model distribution approximates well, and those it does not. We present experiments across two open-ended generation tasks in the web text domain and the story domain, and a variety of decoding algorithms and model sizes. Our results show that evaluation under MAUVE indeed reflects the more natural behavior with respect to model size, compared to prior metrics. MAUVE's ordering of the decoding algorithms also agrees with that of generation perplexity, the most widely used metric in open-ended text generation; however, MAUVE presents a more principled evaluation metric for the task as it considers both model and human text.
Differentiable Programming à la Moreau
Dec 31, 2020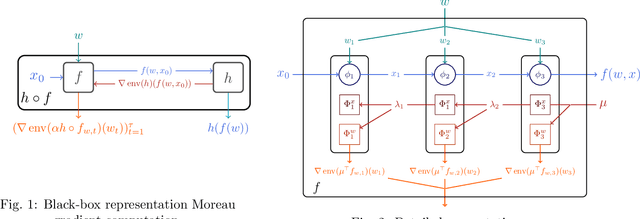
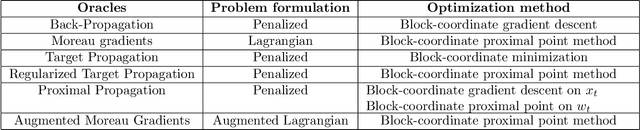
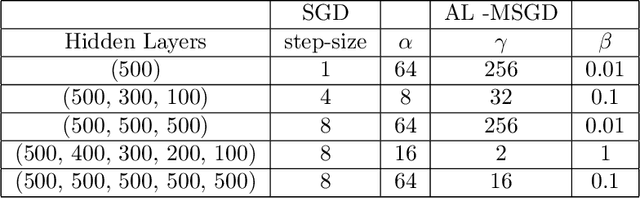
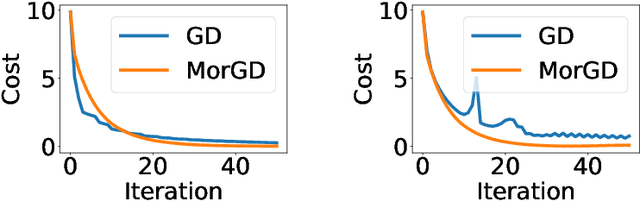
The notion of a Moreau envelope is central to the analysis of first-order optimization algorithms for machine learning. Yet, it has not been developed and extended to be applied to a deep network and, more broadly, to a machine learning system with a differentiable programming implementation. We define a compositional calculus adapted to Moreau envelopes and show how to integrate it within differentiable programming. The proposed framework casts in a mathematical optimization framework several variants of gradient back-propagation related to the idea of the propagation of virtual targets.
Faster Policy Learning with Continuous-Time Gradients
Dec 12, 2020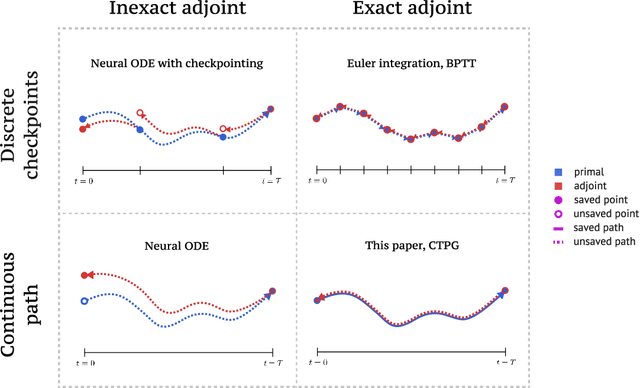
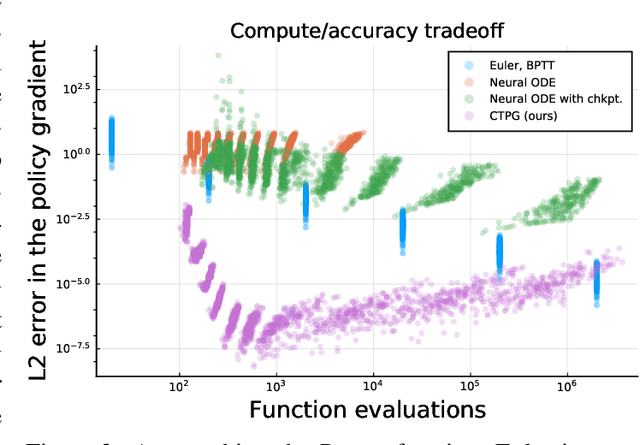
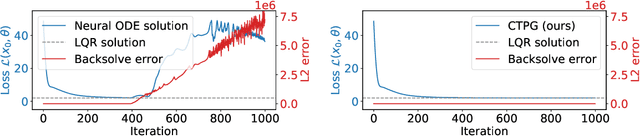
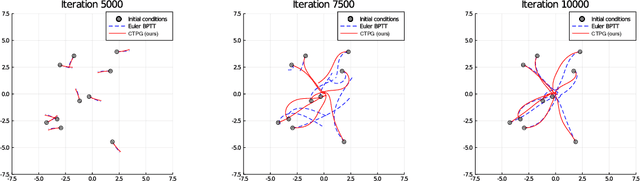
We study the estimation of policy gradients for continuous-time systems with known dynamics. By reframing policy learning in continuous-time, we show that it is possible construct a more efficient and accurate gradient estimator. The standard back-propagation through time estimator (BPTT) computes exact gradients for a crude discretization of the continuous-time system. In contrast, we approximate continuous-time gradients in the original system. With the explicit goal of estimating continuous-time gradients, we are able to discretize adaptively and construct a more efficient policy gradient estimator which we call the Continuous-Time Policy Gradient (CTPG). We show that replacing BPTT policy gradients with more efficient CTPG estimates results in faster and more robust learning in a variety of control tasks and simulators.
Asymptotics of Entropy-Regularized Optimal Transport via Chaos Decomposition
Nov 17, 2020
Consider the problem of estimating the optimal coupling (i.e., matching) between $N$ i.i.d. data points sampled from two densities $\rho_0$ and $\rho_1$ in $\mathbb{R}^d$. The cost of transport is an arbitrary continuous function that satisfies suitable growth and integrability assumptions. For both computational efficiency and smoothness, often a regularization term using entropy is added to this discrete problem. We introduce a modification of the commonly used discrete entropic regularization (Cuturi '13) such that the optimal coupling for the regularized problem can be thought of as the static Schr\"odinger bridge with $N$ particles. This paper is on the asymptotic properties of this discrete Schr\"odinger bridge as $N$ tends to infinity. We show that it converges to the continuum Schr\"odinger bridge and derive the first two error terms of orders $N^{-1/2}$ and $N^{-1}$, respectively. This gives us functional CLT, including for the cost of transport, and second order Gaussian chaos limits when the limiting Gaussian variance is zero, extending similar recent results derived for finite state spaces and the quadratic cost. The proofs are based on a novel chaos decomposition of the discrete Schr\"odinger bridge by polynomial functions of the pair of empirical distributions as a first and second order Taylor approximations in the space of measures. This is achieved by extending the Hoeffding decomposition from the classical theory of U-statistics. The kernels corresponding to the first and second order chaoses are given by Markov operators which have natural interpretations in the Sinkhorn algorithm.