 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Adversarial Patch for Evading Object Detection Models
Oct 25, 2020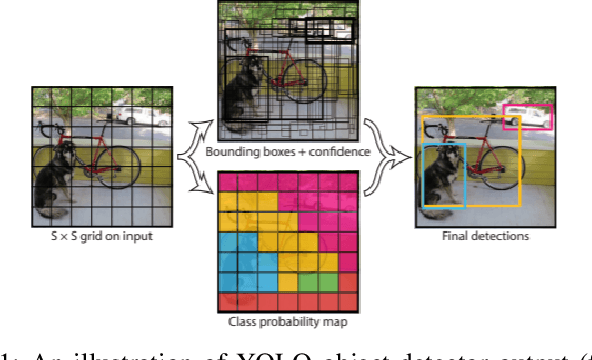
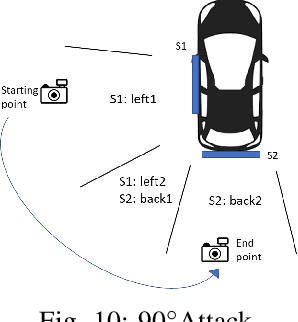
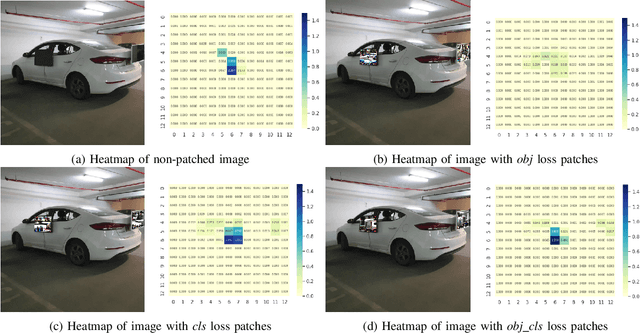

Recent research shows that neural networks models used for computer vision (e.g., YOLO and Fast R-CNN) are vulnerable to adversarial evasion attacks. Most of the existing real-world adversarial attacks against object detectors use an adversarial patch which is attached to the target object (e.g., a carefully crafted sticker placed on a stop sign). This method may not be robust to changes in the camera's location relative to the target object; in addition, it may not work well when applied to nonplanar objects such as cars. In this study, we present an innovative attack method against object detectors applied in a real-world setup that addresses some of the limitations of existing attacks. Our method uses dynamic adversarial patches which are placed at multiple predetermined locations on a target object. An adversarial learning algorithm is applied in order to generate the patches used. The dynamic attack is implemented by switching between optimized patches dynamically, according to the camera's position (i.e., the object detection system's position). In order to demonstrate our attack in a real-world setup, we implemented the patches by attaching flat screens to the target object; the screens are used to present the patches and switch between them, depending on the current camera location. Thus, the attack is dynamic and adjusts itself to the situation to achieve optimal results. We evaluated our dynamic patch approach by attacking the YOLOv2 object detector with a car as the target object and succeeded in misleading it in up to 90% of the video frames when filming the car from a wide viewing angle range. We improved the attack by generating patches that consider the semantic distance between the target object and its classification. We also examined the attack's transferability among different car models and were able to mislead the detector 71% of the time.
Stop Bugging Me! Evading Modern-Day Wiretapping Using Adversarial Perturbations
Oct 24, 2020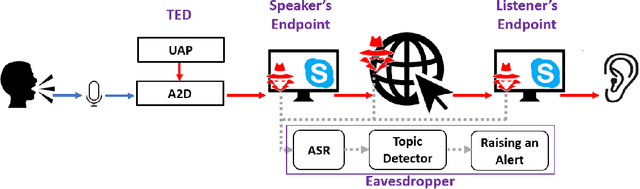
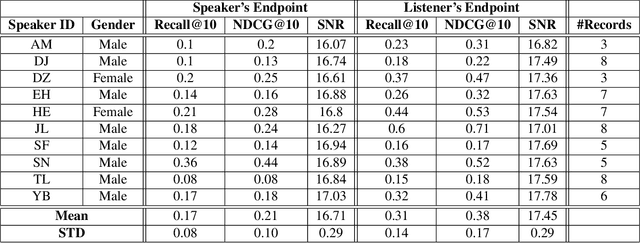
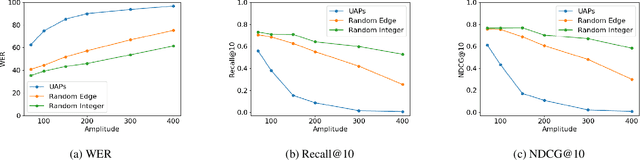
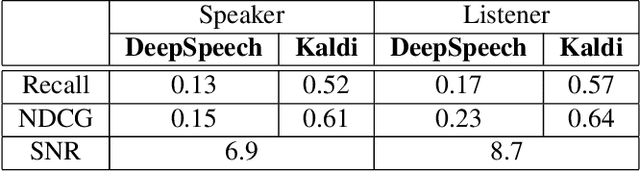
Mass surveillance systems for voice over IP (VoIP) conversations pose a huge risk to privacy. These automated systems use learning models to analyze conversations, and upon detecting calls that involve specific topics, route them to a human agent. In this study, we present an adversarial learning-based framework for privacy protection for VoIP conversations. We present a novel algorithm that finds a universal adversarial perturbation (UAP), which, when added to the audio stream, prevents an eavesdropper from automatically detecting the conversation's topic. As shown in our experiments, the UAP is agnostic to the speaker or audio length, and its volume can be changed in real-time, as needed. In a real-world demonstration, we use a Teensy microcontroller that acts as an external microphone and adds the UAP to the audio in real-time. We examine different speakers, VoIP applications (Skype, Zoom), audio lengths, and speech-to-text models (Deep Speech, Kaldi). Our results in the real world suggest that our approach is a feasible solution for privacy protection.
When Bots Take Over the Stock Market: Evasion Attacks Against Algorithmic Traders
Oct 19, 2020
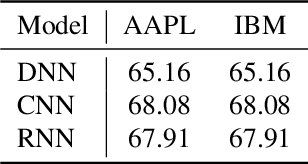
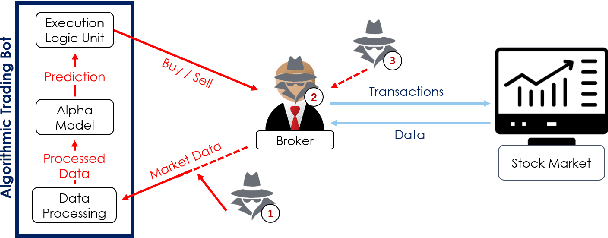
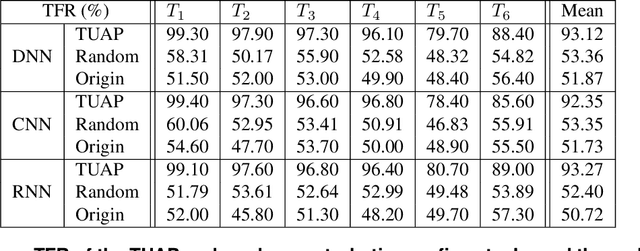
In recent years, machine learning has become prevalent in numerous tasks, including algorithmic trading. Stock market traders utilize learning models to predict the market's behavior and execute an investment strategy accordingly. However, learning models have been shown to be susceptible to input manipulations called adversarial examples. Yet, the trading domain remains largely unexplored in the context of adversarial learning. This is mainly because of the rapid changes in the market which impair the attacker's ability to create a real-time attack. In this study, we present a realistic scenario in which an attacker gains control of an algorithmic trading bots by manipulating the input data stream in real-time. The attacker creates an universal perturbation that is agnostic to the target model and time of use, while also remaining imperceptible. We evaluate our attack on a real-world market data stream and target three different trading architectures. We show that our perturbation can fool the model at future unseen data points, in both white-box and black-box settings. We believe these findings should serve as an alert to the finance community about the threats in this area and prompt further research on the risks associated with using automated learning models in the finance domain.
Not All Datasets Are Born Equal: On Heterogeneous Data and Adversarial Examples
Oct 07, 2020
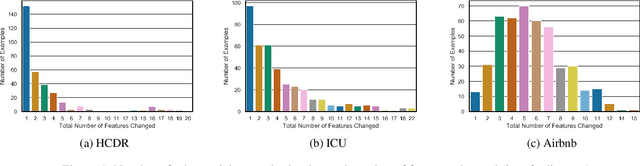

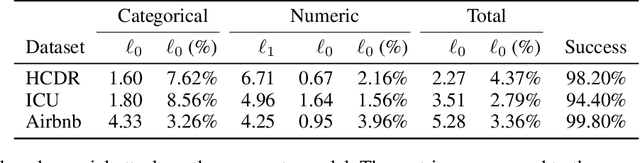
Recent work on adversarial learning has focused mainly on neural networks and domains where they excel, such as computer vision. The data in these domains is homogeneous, whereas heterogeneous tabular data domains remain underexplored despite their prevalence. Constructing an attack on models with heterogeneous input spaces is challenging, as they are governed by complex domain-specific validity rules and comprised of nominal, ordinal, and numerical features. We argue that machine learning models trained on heterogeneous tabular data are as susceptible to adversarial manipulations as those trained on continuous or homogeneous data such as images. In this paper, we introduce an optimization framework for identifying adversarial perturbations in heterogeneous input spaces. We define distribution-aware constraints for preserving the consistency of the adversarial examples and incorporate them by embedding the heterogeneous input into a continuous latent space. Our approach focuses on an adversary who aims to craft valid perturbations of minimal l_0-norms and apply them in real life. We propose a neural network-based implementation of our approach and demonstrate its effectiveness using three datasets from different content domains. Our results suggest that despite the several constraints heterogeneity imposes on the input space of a machine learning model, the susceptibility to adversarial examples remains unimpaired.
Fairness Matters -- A Data-Driven Framework Towards Fair and High Performing Facial Recognition Systems
Sep 16, 2020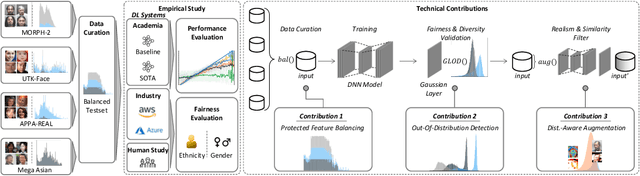


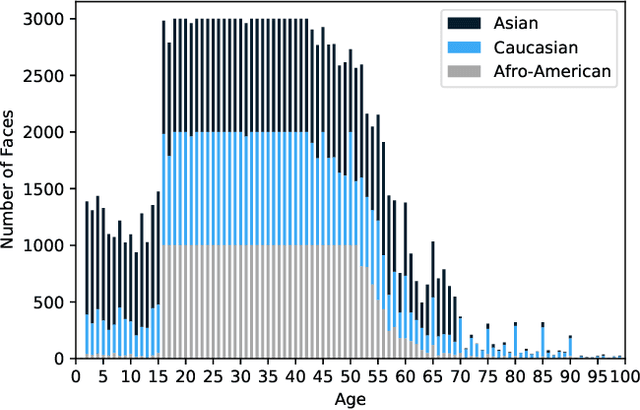
Facial recognition technologies are widely used in governmental and industrial applications. Together with the advancements in deep learning (DL), human-centric tasks such as accurate age prediction based on face images become feasible. However, the issue of fairness when predicting the age for different ethnicity and gender remains an open problem. Policing systems use age to estimate the likelihood of someone to commit a crime, where younger suspects tend to be more likely involved. Unfair age prediction may lead to unfair treatment of humans not only in crime prevention but also in marketing, identity acquisition and authentication. Therefore, this work follows two parts. First, an empirical study is conducted evaluating performance and fairness of state-of-the-art systems for age prediction including baseline and most recent works of academia and the main industrial service providers (Amazon AWS and Microsoft Azure). Building on the findings we present a novel approach to mitigate unfairness and enhance performance, using distribution-aware dataset curation and augmentation. Distribution-awareness is based on out-of-distribution detection which is utilized to validate equal and diverse DL system behavior towards e.g. ethnicity and gender. In total we train 24 DNN models and utilize one million data points to assess performance and fairness of the state-of-the-art for face recognition algorithms. We demonstrate an improvement in mean absolute age prediction error from 7.70 to 3.39 years and a 4-fold increase in fairness towards ethnicity when compared to related work. Utilizing the presented methodology we are able to outperform leading industry players such as Amazon AWS or Microsoft Azure in both fairness and age prediction accuracy and provide the necessary guidelines to assess quality and enhance face recognition systems based on DL techniques.
GLOD: Gaussian Likelihood Out of Distribution Detector
Aug 21, 2020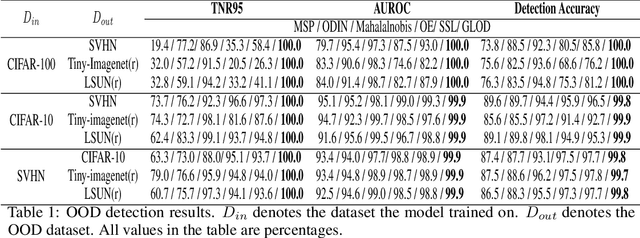
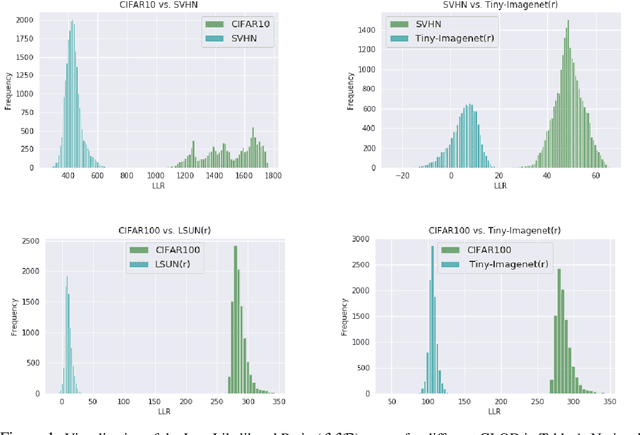
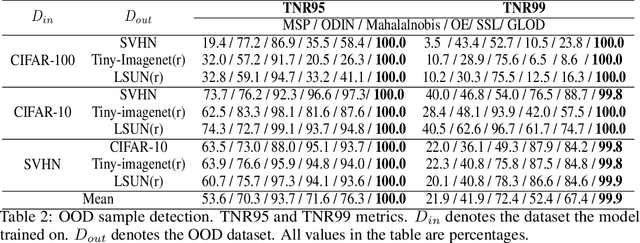
Discriminative deep neural networks (DNNs) do well at classifying input associated with the classes they have been trained on. However, out-of-distribution (OOD) input poses a great challenge to such models and consequently represents a major risk when these models are used in safety-critical systems. In the last two years, extensive research has been performed in the domain of OOD detection. This research has relied mainly on training the model with OOD data or using an auxiliary (external) model for OOD detection. Such methods have limited capability in detecting OOD samples and may not be applicable in many real world use cases. In this paper, we propose GLOD - Gaussian likelihood out of distribution detector - an extended DNN classifier capable of efficiently detecting OOD samples without relying on OOD training data or an external detection model. GLOD uses a layer that models the Gaussian density function of the trained classes. The layer outputs are used to estimate a Log-Likelihood Ratio which is employed to detect OOD samples. We evaluate GLOD's detection performance on three datasets: SVHN, CIFAR-10, and CIFAR-100. Our results show that GLOD surpasses state-of-the-art OOD detection techniques in detection performance by a large margin.
An Automated, End-to-End Framework for Modeling Attacks From Vulnerability Descriptions
Aug 10, 2020
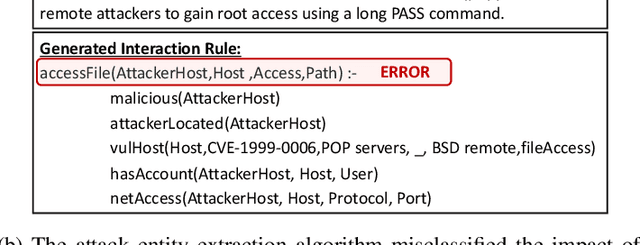
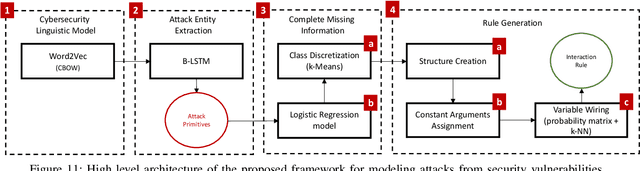
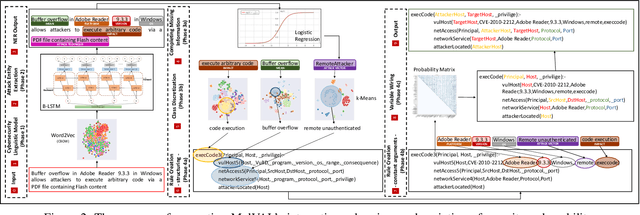
Attack graphs are one of the main techniques used to automate the risk assessment process. In order to derive a relevant attack graph, up-to-date information on known attack techniques should be represented as interaction rules. Designing and creating new interaction rules is not a trivial task and currently performed manually by security experts. However, since the number of new security vulnerabilities and attack techniques continuously and rapidly grows, there is a need to frequently update the rule set of attack graph tools with new attack techniques to ensure that the set of interaction rules is always up-to-date. We present a novel, end-to-end, automated framework for modeling new attack techniques from textual description of a security vulnerability. Given a description of a security vulnerability, the proposed framework first extracts the relevant attack entities required to model the attack, completes missing information on the vulnerability, and derives a new interaction rule that models the attack; this new rule is integrated within MulVAL attack graph tool. The proposed framework implements a novel pipeline that includes a dedicated cybersecurity linguistic model trained on the the NVD repository, a recurrent neural network model used for attack entity extraction, a logistic regression model used for completing the missing information, and a novel machine learning-based approach for automatically modeling the attacks as MulVAL's interaction rule. We evaluated the performance of each of the individual algorithms, as well as the complete framework and demonstrated its effectiveness.
Adversarial Learning in the Cyber Security Domain
Jul 05, 2020
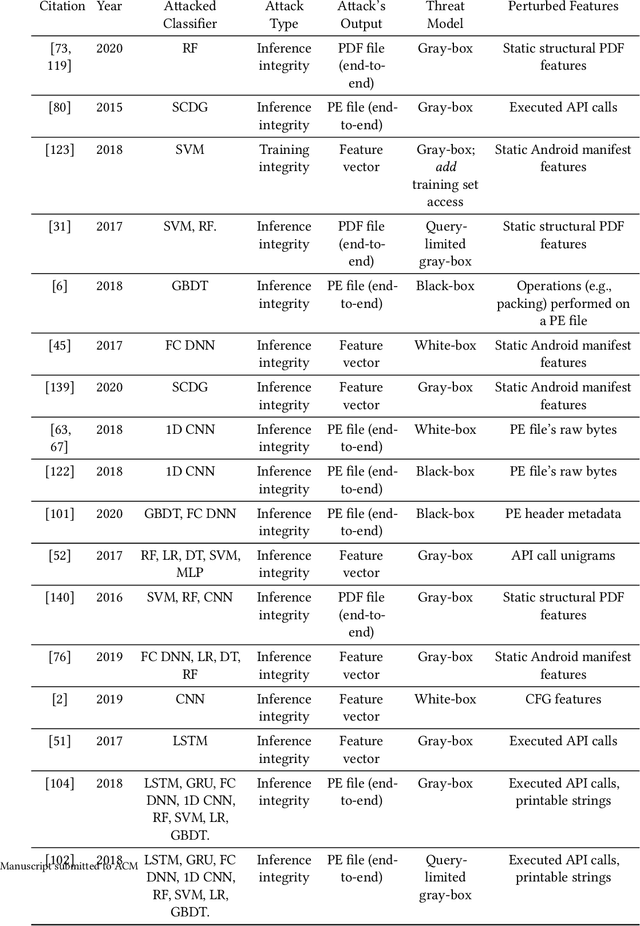
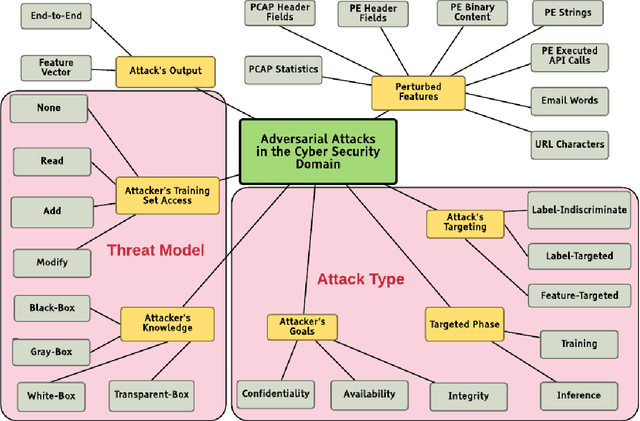
In recent years, machine learning algorithms, and more specially, deep learning algorithms, have been widely used in many fields, including cyber security. However, machine learning systems are vulnerable to adversarial attacks, and this limits the application of machine learning, especially in non-stationary, adversarial environments, such as the cyber security domain, where actual adversaries (e.g., malware developers) exist. This paper comprehensively summarizes the latest research on adversarial attacks against security solutions that are based on machine learning techniques and presents the risks they pose to cyber security solutions. First, we discuss the unique challenges of implementing end-to-end adversarial attacks in the cyber security domain. Following that, we define a unified taxonomy, where the adversarial attack methods are characterized based on their stage of occurrence, and the attacker's goals and capabilities. Then, we categorize the applications of adversarial attack techniques in the cyber security domain. Finally, we use our taxonomy to shed light on gaps in the cyber security domain that have already been addressed in other adversarial learning domains and discuss their impact on future adversarial learning trends in the cyber security domain.
Autosploit: A Fully Automated Framework for Evaluating the Exploitability of Security Vulnerabilities
Jun 30, 2020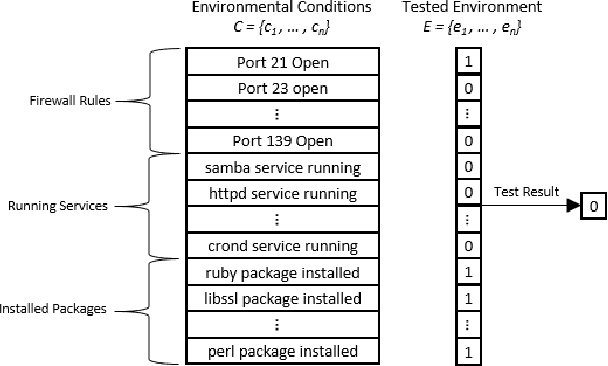
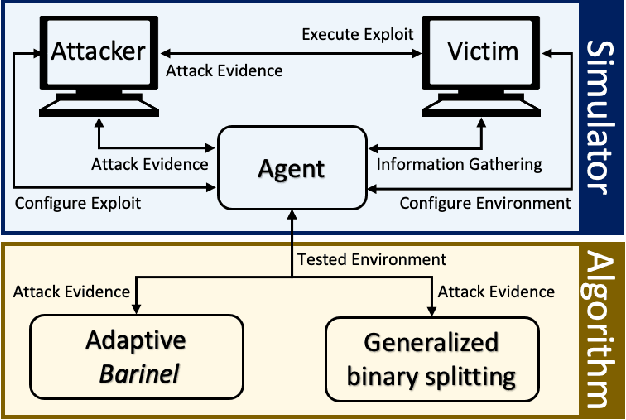
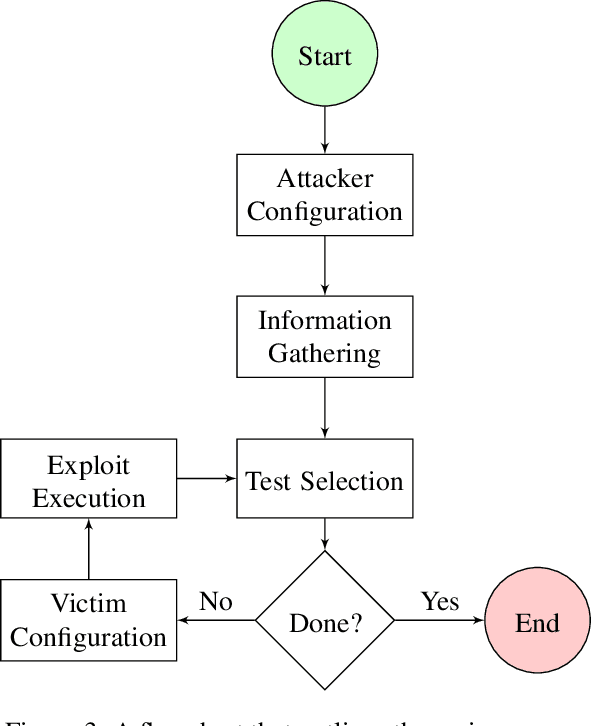
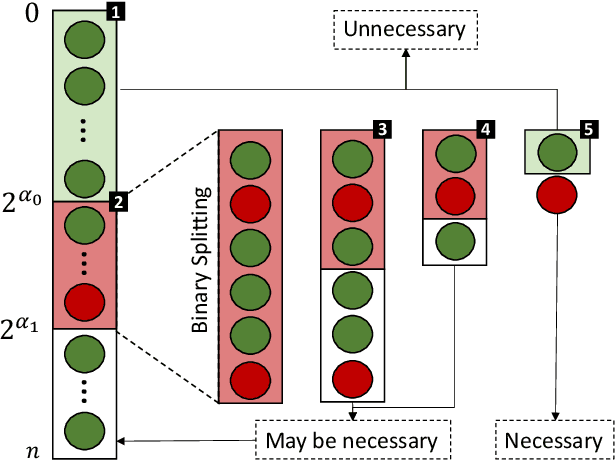
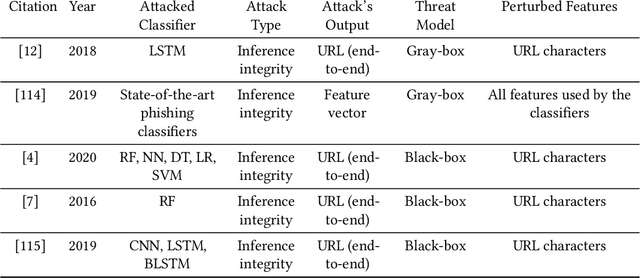
The existence of a security vulnerability in a system does not necessarily mean that it can be exploited. In this research, we introduce Autosploit -- an automated framework for evaluating the exploitability of vulnerabilities. Given a vulnerable environment and relevant exploits, Autosploit will automatically test the exploits on different configurations of the environment in order to identify the specific properties necessary for successful exploitation of the existing vulnerabilities. Since testing all possible system configurations is infeasible, we introduce an efficient approach for testing and searching through all possible configurations of the environment. The efficient testing process implemented by Autosploit is based on two algorithms: generalized binary splitting and Barinel, which are used for noiseless and noisy environments respectively. We implemented the proposed framework and evaluated it using real vulnerabilities. The results show that Autosploit is able to automatically identify the system properties that affect the ability to exploit a vulnerability in both noiseless and noisy environments. These important results can be utilized for more accurate and effective risk assessment.
Lightweight Collaborative Anomaly Detection for the IoT using Blockchain
Jun 18, 2020
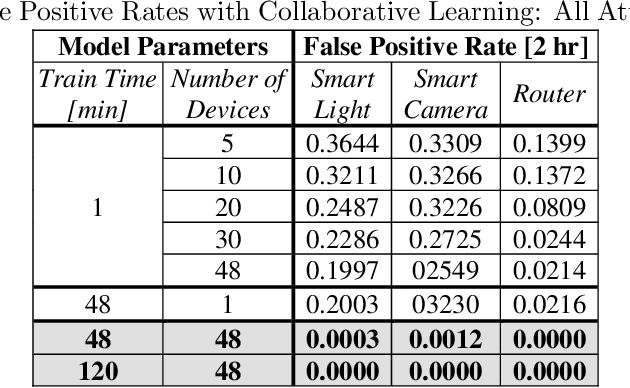
Due to their rapid growth and deployment, the Internet of things (IoT) have become a central aspect of our daily lives. Unfortunately, IoT devices tend to have many vulnerabilities which can be exploited by an attacker. Unsupervised techniques, such as anomaly detection, can be used to secure these devices in a plug-and-protect manner. However, anomaly detection models must be trained for a long time in order to capture all benign behaviors. Furthermore, the anomaly detection model is vulnerable to adversarial attacks since, during the training phase, all observations are assumed to be benign. In this paper, we propose (1) a novel approach for anomaly detection and (2) a lightweight framework that utilizes the blockchain to ensemble an anomaly detection model in a distributed environment. Blockchain framework incrementally updates a trusted anomaly detection model via self-attestation and consensus among the IoT devices. We evaluate our method on a distributed IoT simulation platform, which consists of 48 Raspberry Pis. The simulation demonstrates how the approach can enhance the security of each device and the security of the network as a whole.