 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOTEC: Off-Policy Learning for Large Action Spaces via Two-Stage Policy Decomposition
Feb 09, 2024



We study off-policy learning (OPL) of contextual bandit policies in large discrete action spaces where existing methods -- most of which rely crucially on reward-regression models or importance-weighted policy gradients -- fail due to excessive bias or variance. To overcome these issues in OPL, we propose a novel two-stage algorithm, called Policy Optimization via Two-Stage Policy Decomposition (POTEC). It leverages clustering in the action space and learns two different policies via policy- and regression-based approaches, respectively. In particular, we derive a novel low-variance gradient estimator that enables to learn a first-stage policy for cluster selection efficiently via a policy-based approach. To select a specific action within the cluster sampled by the first-stage policy, POTEC uses a second-stage policy derived from a regression-based approach within each cluster. We show that a local correctness condition, which only requires that the regression model preserves the relative expected reward differences of the actions within each cluster, ensures that our policy-gradient estimator is unbiased and the second-stage policy is optimal. We also show that POTEC provides a strict generalization of policy- and regression-based approaches and their associated assumptions. Comprehensive experiments demonstrate that POTEC provides substantial improvements in OPL effectiveness particularly in large and structured action spaces.
Off-Policy Evaluation of Slate Bandit Policies via Optimizing Abstraction
Feb 03, 2024



We study off-policy evaluation (OPE) in the problem of slate contextual bandits where a policy selects multi-dimensional actions known as slates. This problem is widespread in recommender systems, search engines, marketing, to medical applications, however, the typical Inverse Propensity Scoring (IPS) estimator suffers from substantial variance due to large action spaces, making effective OPE a significant challenge. The PseudoInverse (PI) estimator has been introduced to mitigate the variance issue by assuming linearity in the reward function, but this can result in significant bias as this assumption is hard-to-verify from observed data and is often substantially violated. To address the limitations of previous estimators, we develop a novel estimator for OPE of slate bandits, called Latent IPS (LIPS), which defines importance weights in a low-dimensional slate abstraction space where we optimize slate abstractions to minimize the bias and variance of LIPS in a data-driven way. By doing so, LIPS can substantially reduce the variance of IPS without imposing restrictive assumptions on the reward function structure like linearity. Through empirical evaluation, we demonstrate that LIPS substantially outperforms existing estimators, particularly in scenarios with non-linear rewards and large slate spaces.
Towards Assessing and Benchmarking Risk-Return Tradeoff of Off-Policy Evaluation
Dec 04, 2023



Off-Policy Evaluation (OPE) aims to assess the effectiveness of counterfactual policies using only offline logged data and is often used to identify the top-k promising policies for deployment in online A/B tests. Existing evaluation metrics for OPE estimators primarily focus on the "accuracy" of OPE or that of downstream policy selection, neglecting risk-return tradeoff in the subsequent online policy deployment. To address this issue, we draw inspiration from portfolio evaluation in finance and develop a new metric, called SharpeRatio@k, which measures the risk-return tradeoff of policy portfolios formed by an OPE estimator under varying online evaluation budgets (k). We validate our metric in two example scenarios, demonstrating its ability to effectively distinguish between low-risk and high-risk estimators and to accurately identify the most efficient estimator. This efficient estimator is characterized by its capability to form the most advantageous policy portfolios, maximizing returns while minimizing risks during online deployment, a nuance that existing metrics typically overlook. To facilitate a quick, accurate, and consistent evaluation of OPE via SharpeRatio@k, we have also integrated this metric into an open-source software, SCOPE-RL. Employing SharpeRatio@k and SCOPE-RL, we conduct comprehensive benchmarking experiments on various estimators and RL tasks, focusing on their risk-return tradeoff. These experiments offer several interesting directions and suggestions for future OPE research.
SCOPE-RL: A Python Library for Offline Reinforcement Learning and Off-Policy Evaluation
Dec 04, 2023



This paper introduces SCOPE-RL, a comprehensive open-source Python software designed for offline reinforcement learning (offline RL), off-policy evaluation (OPE), and selection (OPS). Unlike most existing libraries that focus solely on either policy learning or evaluation, SCOPE-RL seamlessly integrates these two key aspects, facilitating flexible and complete implementations of both offline RL and OPE processes. SCOPE-RL put particular emphasis on its OPE modules, offering a range of OPE estimators and robust evaluation-of-OPE protocols. This approach enables more in-depth and reliable OPE compared to other packages. For instance, SCOPE-RL enhances OPE by estimating the entire reward distribution under a policy rather than its mere point-wise expected value. Additionally, SCOPE-RL provides a more thorough evaluation-of-OPE by presenting the risk-return tradeoff in OPE results, extending beyond mere accuracy evaluations in existing OPE literature. SCOPE-RL is designed with user accessibility in mind. Its user-friendly APIs, comprehensive documentation, and a variety of easy-to-follow examples assist researchers and practitioners in efficiently implementing and experimenting with various offline RL methods and OPE estimators, tailored to their specific problem contexts. The documentation of SCOPE-RL is available at https://scope-rl.readthedocs.io/en/latest/.
Off-Policy Evaluation of Ranking Policies under Diverse User Behavior
Jun 26, 2023Ranking interfaces are everywhere in online platforms. There is thus an ever growing interest in their Off-Policy Evaluation (OPE), aiming towards an accurate performance evaluation of ranking policies using logged data. A de-facto approach for OPE is Inverse Propensity Scoring (IPS), which provides an unbiased and consistent value estimate. However, it becomes extremely inaccurate in the ranking setup due to its high variance under large action spaces. To deal with this problem, previous studies assume either independent or cascade user behavior, resulting in some ranking versions of IPS. While these estimators are somewhat effective in reducing the variance, all existing estimators apply a single universal assumption to every user, causing excessive bias and variance. Therefore, this work explores a far more general formulation where user behavior is diverse and can vary depending on the user context. We show that the resulting estimator, which we call Adaptive IPS (AIPS), can be unbiased under any complex user behavior. Moreover, AIPS achieves the minimum variance among all unbiased estimators based on IPS. We further develop a procedure to identify the appropriate user behavior model to minimize the mean squared error (MSE) of AIPS in a data-driven fashion. Extensive experiments demonstrate that the empirical accuracy improvement can be significant, enabling effective OPE of ranking systems even under diverse user behavior.
Off-Policy Evaluation for Large Action Spaces via Conjunct Effect Modeling
May 14, 2023



We study off-policy evaluation (OPE) of contextual bandit policies for large discrete action spaces where conventional importance-weighting approaches suffer from excessive variance. To circumvent this variance issue, we propose a new estimator, called OffCEM, that is based on the conjunct effect model (CEM), a novel decomposition of the causal effect into a cluster effect and a residual effect. OffCEM applies importance weighting only to action clusters and addresses the residual causal effect through model-based reward estimation. We show that the proposed estimator is unbiased under a new condition, called local correctness, which only requires that the residual-effect model preserves the relative expected reward differences of the actions within each cluster. To best leverage the CEM and local correctness, we also propose a new two-step procedure for performing model-based estimation that minimizes bias in the first step and variance in the second step. We find that the resulting OffCEM estimator substantially improves bias and variance compared to a range of conventional estimators. Experiments demonstrate that OffCEM provides substantial improvements in OPE especially in the presence of many actions.
Policy-Adaptive Estimator Selection for Off-Policy Evaluation
Nov 25, 2022



Off-policy evaluation (OPE) aims to accurately evaluate the performance of counterfactual policies using only offline logged data. Although many estimators have been developed, there is no single estimator that dominates the others, because the estimators' accuracy can vary greatly depending on a given OPE task such as the evaluation policy, number of actions, and noise level. Thus, the data-driven estimator selection problem is becoming increasingly important and can have a significant impact on the accuracy of OPE. However, identifying the most accurate estimator using only the logged data is quite challenging because the ground-truth estimation accuracy of estimators is generally unavailable. This paper studies this challenging problem of estimator selection for OPE for the first time. In particular, we enable an estimator selection that is adaptive to a given OPE task, by appropriately subsampling available logged data and constructing pseudo policies useful for the underlying estimator selection task. Comprehensive experiments on both synthetic and real-world company data demonstrate that the proposed procedure substantially improves the estimator selection compared to a non-adaptive heuristic.
Fair Ranking as Fair Division: Impact-Based Individual Fairness in Ranking
Jun 15, 2022
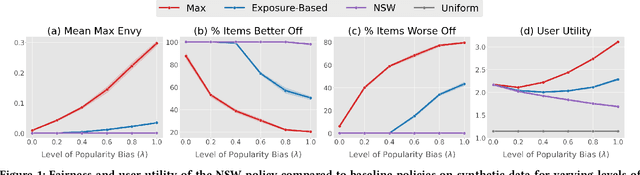
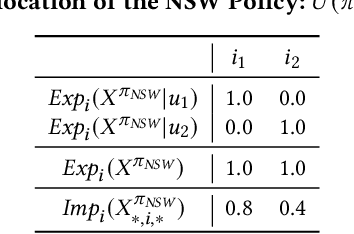
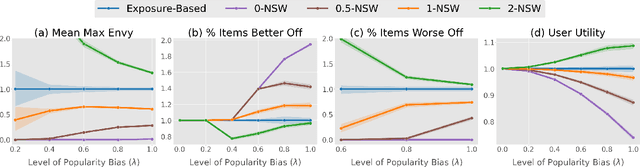
Rankings have become the primary interface in two-sided online markets. Many have noted that the rankings not only affect the satisfaction of the users (e.g., customers, listeners, employers, travelers), but that the position in the ranking allocates exposure -- and thus economic opportunity -- to the ranked items (e.g., articles, products, songs, job seekers, restaurants, hotels). This has raised questions of fairness to the items, and most existing works have addressed fairness by explicitly linking item exposure to item relevance. However, we argue that any particular choice of such a link function may be difficult to defend, and we show that the resulting rankings can still be unfair. To avoid these shortcomings, we develop a new axiomatic approach that is rooted in principles of fair division. This not only avoids the need to choose a link function, but also more meaningfully quantifies the impact on the items beyond exposure. Our axioms of envy-freeness and dominance over uniform ranking postulate that for a fair ranking policy every item should prefer their own rank allocation over that of any other item, and that no item should be actively disadvantaged by the rankings. To compute ranking policies that are fair according to these axioms, we propose a new ranking objective related to the Nash Social Welfare. We show that the solution has guarantees regarding its envy-freeness, its dominance over uniform rankings for every item, and its Pareto optimality. In contrast, we show that conventional exposure-based fairness can produce large amounts of envy and have a highly disparate impact on the items. Beyond these theoretical results, we illustrate empirically how our framework controls the trade-off between impact-based individual item fairness and user utility.
A Real-World Implementation of Unbiased Lift-based Bidding System
Feb 23, 2022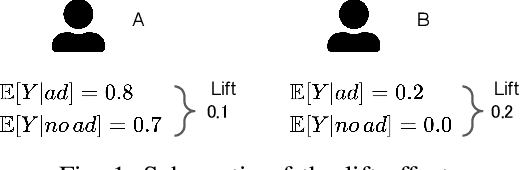
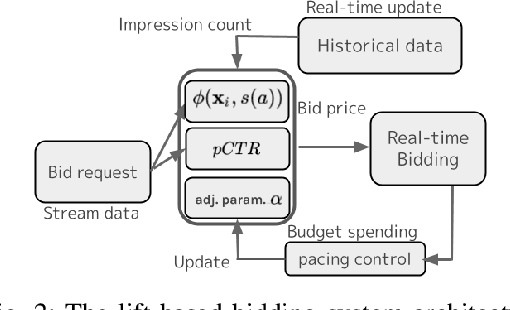
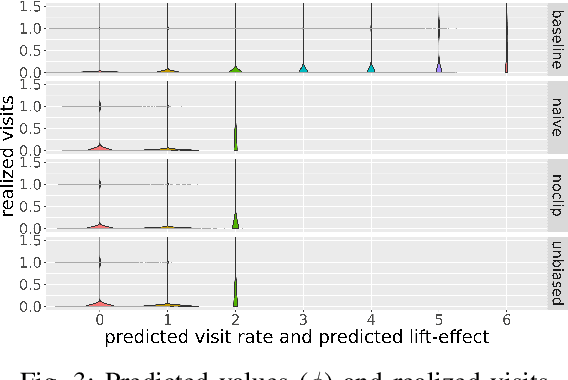
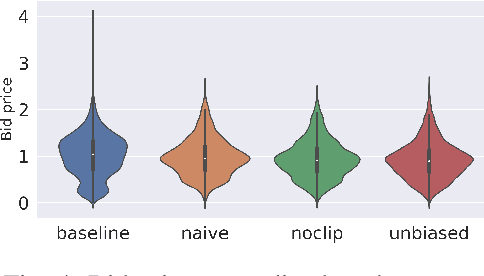
In display ad auctions of Real-Time Bid-ding (RTB), a typical Demand-Side Platform (DSP)bids based on the predicted probability of click and conversion right after an ad impression. Recent studies find such a strategy is suboptimal and propose a better bidding strategy named lift-based bidding.Lift-based bidding simply bids the price according to the lift effect of the ad impression and achieves maximization of target metrics such as sales. Despiteits superiority, lift-based bidding has not yet been widely accepted in the advertising industry. For one reason, lift-based bidding is less profitable for DSP providers under the current billing rule. Second, thepractical usefulness of lift-based bidding is not widely understood in the online advertising industry due to the lack of a comprehensive investigation of its impact.We here propose a practically-implementable lift-based bidding system that perfectly fits the current billing rules. We conduct extensive experiments usinga real-world advertising campaign and examine the performance under various settings. We find that lift-based bidding, especially unbiased lift-based bidding is most profitable for both DSP providers and advertisers. Our ablation study highlights that lift-based bidding has a good property for currently dominant first price auctions. The results will motivate the online
Off-Policy Evaluation for Large Action Spaces via Embeddings
Feb 13, 2022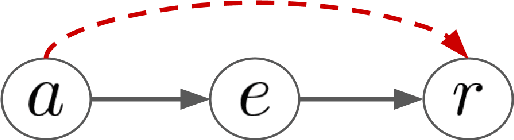

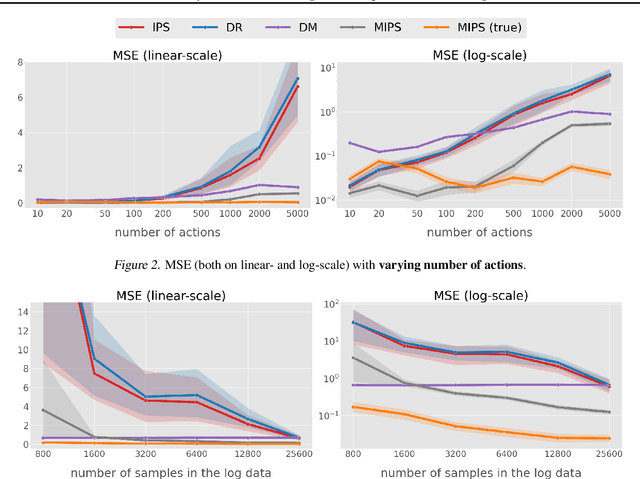
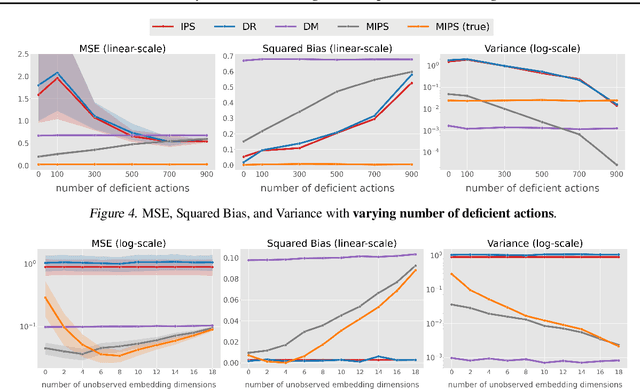
Off-policy evaluation (OPE) in contextual bandits has seen rapid adoption in real-world systems, since it enables offline evaluation of new policies using only historic log data. Unfortunately, when the number of actions is large, existing OPE estimators -- most of which are based on inverse propensity score weighting -- degrade severely and can suffer from extreme bias and variance. This foils the use of OPE in many applications from recommender systems to language models. To overcome this issue, we propose a new OPE estimator that leverages marginalized importance weights when action embeddings provide structure in the action space. We characterize the bias, variance, and mean squared error of the proposed estimator and analyze the conditions under which the action embedding provides statistical benefits over conventional estimators. In addition to the theoretical analysis, we find that the empirical performance improvement can be substantial, enabling reliable OPE even when existing estimators collapse due to a large number of actions.