 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Adaptation of Medical Vision-Language Models
Sep 05, 2024Integrating image and text data through multi-modal learning has emerged as a new approach in medical imaging research, following its successful deployment in computer vision. While considerable efforts have been dedicated to establishing medical foundation models and their zero-shot transfer to downstream tasks, the popular few-shot setting remains relatively unexplored. Following on from the currently strong emergence of this setting in computer vision, we introduce the first structured benchmark for adapting medical vision-language models (VLMs) in a strict few-shot regime and investigate various adaptation strategies commonly used in the context of natural images. Furthermore, we evaluate a simple generalization of the linear-probe adaptation baseline, which seeks an optimal blending of the visual prototypes and text embeddings via learnable class-wise multipliers. Surprisingly, such a text-informed linear probe yields competitive performances in comparison to convoluted prompt-learning and adapter-based strategies, while running considerably faster and accommodating the black-box setting. Our extensive experiments span three different medical modalities and specialized foundation models, nine downstream tasks, and several state-of-the-art few-shot adaptation methods. We made our benchmark and code publicly available to trigger further developments in this emergent subject: \url{https://github.com/FereshteShakeri/few-shot-MedVLMs}.
Boosting Vision-Language Models for Histopathology Classification: Predict all at once
Sep 03, 2024The development of vision-language models (VLMs) for histo-pathology has shown promising new usages and zero-shot performances. However, current approaches, which decompose large slides into smaller patches, focus solely on inductive classification, i.e., prediction for each patch is made independently of the other patches in the target test data. We extend the capability of these large models by introducing a transductive approach. By using text-based predictions and affinity relationships among patches, our approach leverages the strong zero-shot capabilities of these new VLMs without any additional labels. Our experiments cover four histopathology datasets and five different VLMs. Operating solely in the embedding space (i.e., in a black-box setting), our approach is highly efficient, processing $10^5$ patches in just a few seconds, and shows significant accuracy improvements over inductive zero-shot classification. Code available at https://github.com/FereshteShakeri/Histo-TransCLIP.
LP++: A Surprisingly Strong Linear Probe for Few-Shot CLIP
Apr 02, 2024



In a recent, strongly emergent literature on few-shot CLIP adaptation, Linear Probe (LP) has been often reported as a weak baseline. This has motivated intensive research building convoluted prompt learning or feature adaptation strategies. In this work, we propose and examine from convex-optimization perspectives a generalization of the standard LP baseline, in which the linear classifier weights are learnable functions of the text embedding, with class-wise multipliers blending image and text knowledge. As our objective function depends on two types of variables, i.e., the class visual prototypes and the learnable blending parameters, we propose a computationally efficient block coordinate Majorize-Minimize (MM) descent algorithm. In our full-batch MM optimizer, which we coin LP++, step sizes are implicit, unlike standard gradient descent practices where learning rates are intensively searched over validation sets. By examining the mathematical properties of our loss (e.g., Lipschitz gradient continuity), we build majorizing functions yielding data-driven learning rates and derive approximations of the loss's minima, which provide data-informed initialization of the variables. Our image-language objective function, along with these non-trivial optimization insights and ingredients, yields, surprisingly, highly competitive few-shot CLIP performances. Furthermore, LP++ operates in black-box, relaxes intensive validation searches for the optimization hyper-parameters, and runs orders-of-magnitudes faster than state-of-the-art few-shot CLIP adaptation methods. Our code is available at: \url{https://github.com/FereshteShakeri/FewShot-CLIP-Strong-Baseline.git}.
Efficient Bayes Inference in Neural Networks through Adaptive Importance Sampling
Oct 03, 2022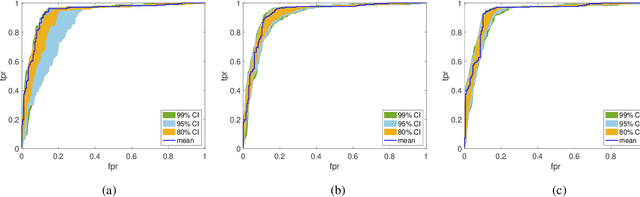

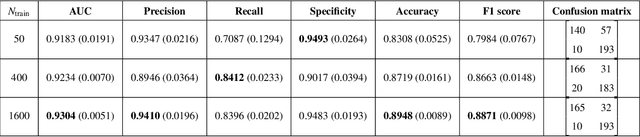
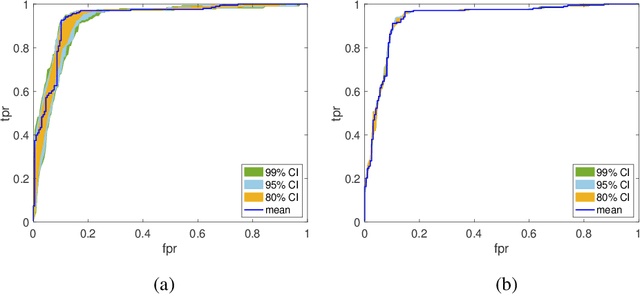
Bayesian neural networks (BNNs) have received an increased interest in the last years. In BNNs, a complete posterior distribution of the unknown weight and bias parameters of the network is produced during the training stage. This probabilistic estimation offers several advantages with respect to point-wise estimates, in particular, the ability to provide uncertainty quantification when predicting new data. This feature inherent to the Bayesian paradigm, is useful in countless machine learning applications. It is particularly appealing in areas where decision-making has a crucial impact, such as medical healthcare or autonomous driving. The main challenge of BNNs is the computational cost of the training procedure since Bayesian techniques often face a severe curse of dimensionality. Adaptive importance sampling (AIS) is one of the most prominent Monte Carlo methodologies benefiting from sounded convergence guarantees and ease for adaptation. This work aims to show that AIS constitutes a successful approach for designing BNNs. More precisely, we propose a novel algorithm PMCnet that includes an efficient adaptation mechanism, exploiting geometric information on the complex (often multimodal) posterior distribution. Numerical results illustrate the excellent performance and the improved exploration capabilities of the proposed method for both shallow and deep neural networks.
Unrolled Variational Bayesian Algorithm for Image Blind Deconvolution
Oct 14, 2021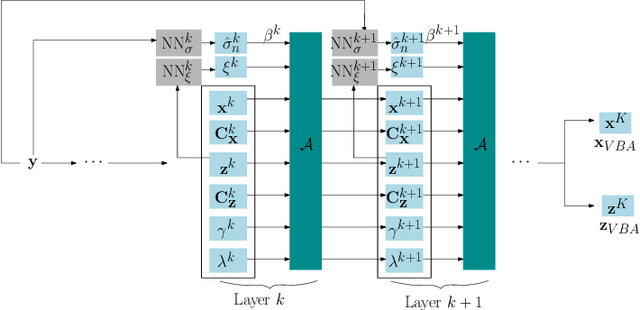
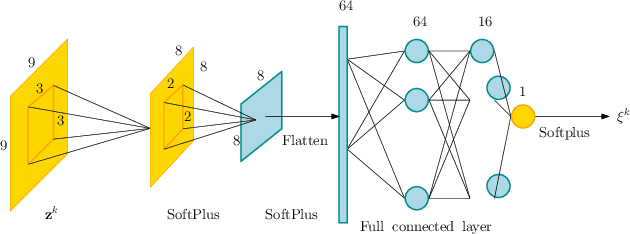
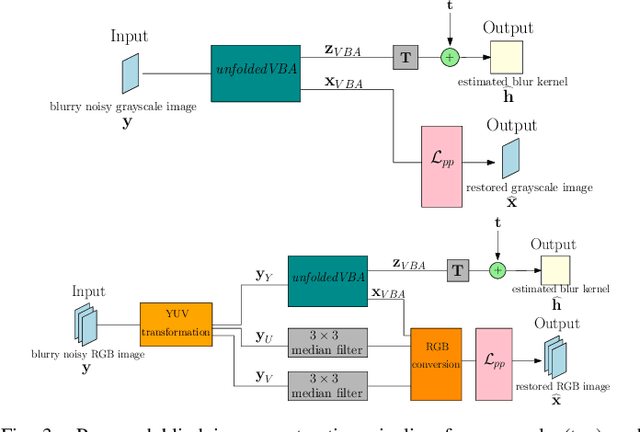

In this paper, we introduce a variational Bayesian algorithm (VBA) for image blind deconvolution. Our generic framework incorporates smoothness priors on the unknown blur/image and possible affine constraints (e.g., sum to one) on the blur kernel. One of our main contributions is the integration of VBA within a neural network paradigm, following an unrolling methodology. The proposed architecture is trained in a supervised fashion, which allows us to optimally set two key hyperparameters of the VBA model and lead to further improvements in terms of resulting visual quality. Various experiments involving grayscale/color images and diverse kernel shapes, are performed. The numerical examples illustrate the high performance of our approach when compared to state-of-the-art techniques based on optimization, Bayesian estimation, or deep learning.