 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDAR-Forest Dataset: LiDAR Point Cloud Simulation Dataset for Forestry Application
Feb 15, 2024


The popularity of LiDAR devices and sensor technology has gradually empowered users from autonomous driving to forest monitoring, and research on 3D LiDAR has made remarkable progress over the years. Unlike 2D images, whose focused area is visible and rich in texture information, understanding the point distribution can help companies and researchers find better ways to develop point-based 3D applications. In this work, we contribute an unreal-based LiDAR simulation tool and a 3D simulation dataset named LiDAR-Forest, which can be used by various studies to evaluate forest reconstruction, tree DBH estimation, and point cloud compression for easy visualization. The simulation is customizable in tree species, LiDAR types and scene generation, with low cost and high efficiency.
Reinforcement Learning for Linear Quadratic Control is Vulnerable Under Cost Manipulation
Apr 07, 2022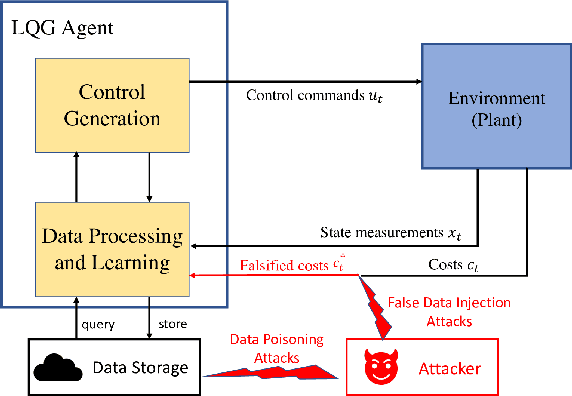
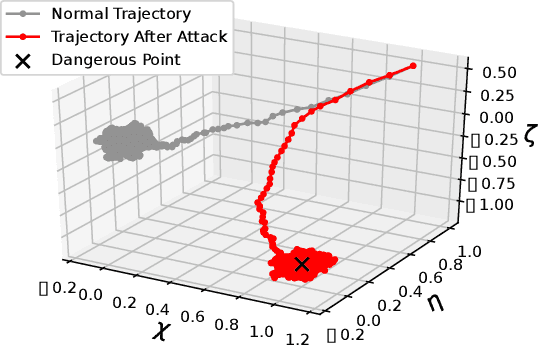
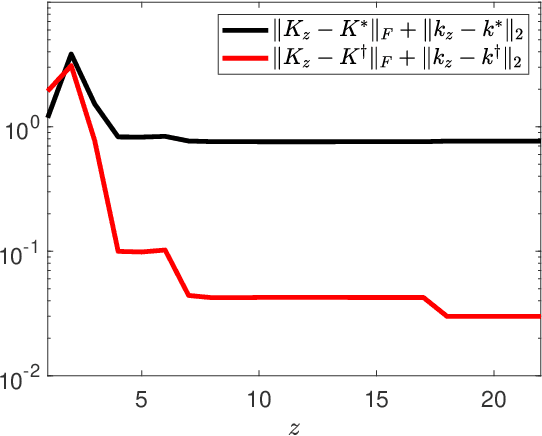
In this work, we study the deception of a Linear-Quadratic-Gaussian (LQG) agent by manipulating the cost signals. We show that a small falsification of the cost parameters will only lead to a bounded change in the optimal policy. The bound is linear on the amount of falsification the attacker can apply to the cost parameters. We propose an attack model where the attacker aims to mislead the agent into learning a `nefarious' policy by intentionally falsifying the cost parameters. We formulate the attack's problem as a convex optimization problem and develop necessary and sufficient conditions to check the achievability of the attacker's goal. We showcase the adversarial manipulation on two types of LQG learners: the batch RL learner and the other is the adaptive dynamic programming (ADP) learner. Our results demonstrate that with only 2.296% of falsification on the cost data, the attacker misleads the batch RL into learning the 'nefarious' policy that leads the vehicle to a dangerous position. The attacker can also gradually trick the ADP learner into learning the same `nefarious' policy by consistently feeding the learner a falsified cost signal that stays close to the actual cost signal. The paper aims to raise people's awareness of the security threats faced by RL-enabled control systems.
Reinforcement Learning for Feedback-Enabled Cyber Resilience
Jul 02, 2021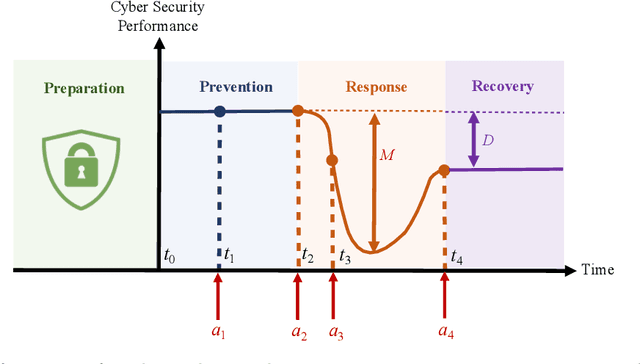
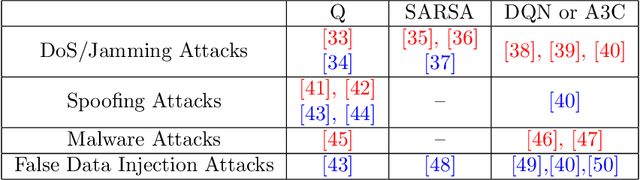
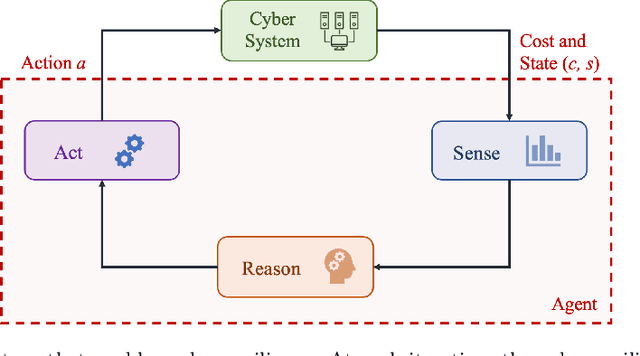

The rapid growth in the number of devices and their connectivity has enlarged the attack surface and weakened cyber systems. As attackers become increasingly sophisticated and resourceful, mere reliance on traditional cyber protection, such as intrusion detection, firewalls, and encryption, is insufficient to secure cyber systems. Cyber resilience provides a new security paradigm that complements inadequate protection with resilience mechanisms. A Cyber-Resilient Mechanism (CRM) adapts to the known or zero-day threats and uncertainties in real-time and strategically responds to them to maintain the critical functions of the cyber systems. Feedback architectures play a pivotal role in enabling the online sensing, reasoning, and actuation of the CRM. Reinforcement Learning (RL) is an important class of algorithms that epitomize the feedback architectures for cyber resiliency, allowing the CRM to provide dynamic and sequential responses to attacks with limited prior knowledge of the attacker. In this work, we review the literature on RL for cyber resiliency and discuss the cyber-resilient defenses against three major types of vulnerabilities, i.e., posture-related, information-related, and human-related vulnerabilities. We introduce moving target defense, defensive cyber deception, and assistive human security technologies as three application domains of CRMs to elaborate on their designs. The RL technique also has vulnerabilities itself. We explain the major vulnerabilities of RL and present several attack models in which the attacks target the rewards, the measurements, and the actuators. We show that the attacker can trick the RL agent into learning a nefarious policy with minimum attacking effort, which shows serious security concerns for RL-enabled systems. Finally, we discuss the future challenges of RL for cyber security and resiliency and emerging applications of RL-based CRMs.
Self-Triggered Markov Decision Processes
Feb 17, 2021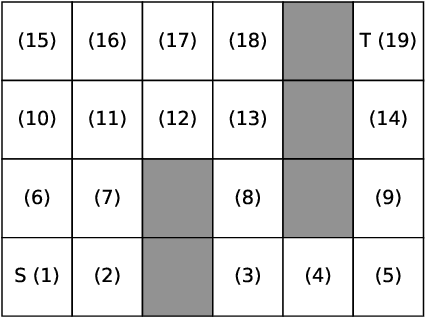
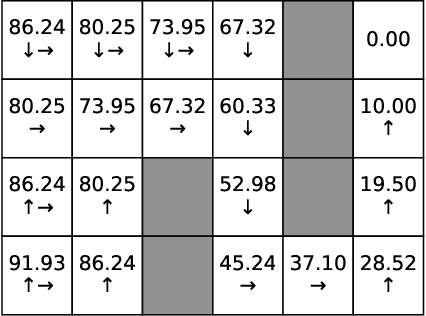
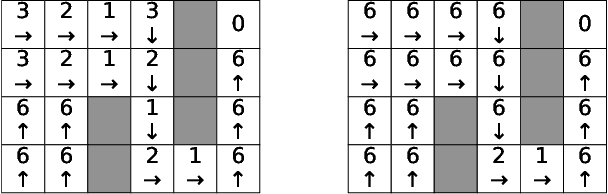
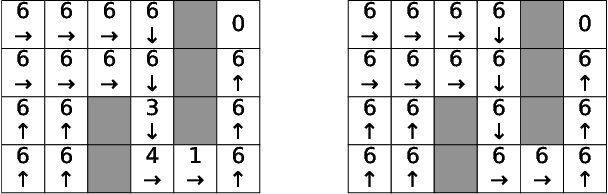
In this paper, we study Markov Decision Processes (MDPs) with self-triggered strategies, where the idea of self-triggered control is extended to more generic MDP models. This extension broadens the application of self-triggering policies to a broader range of systems. We study the co-design problems of the control policy and the triggering policy to optimize two pre-specified cost criteria. The first cost criterion is introduced by incorporating a pre-specified update penalty into the traditional MDP cost criteria to reduce the use of communication resources. Under this criteria, a novel dynamic programming (DP) equation called DP equation with optimized lookahead to proposed to solve for the self-triggering policy under this criteria. The second self-triggering policy is to maximize the triggering time while still guaranteeing a pre-specified level of sub-optimality. Theoretical underpinnings are established for the computation and implementation of both policies. Through a gridworld numerical example, we illustrate the two policies' effectiveness in reducing sources consumption and demonstrate the trade-offs between resource consumption and system performance.
Manipulating Reinforcement Learning: Poisoning Attacks on Cost Signals
Feb 07, 2020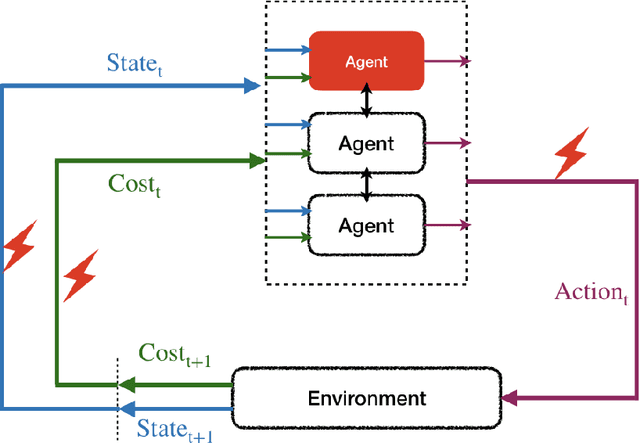

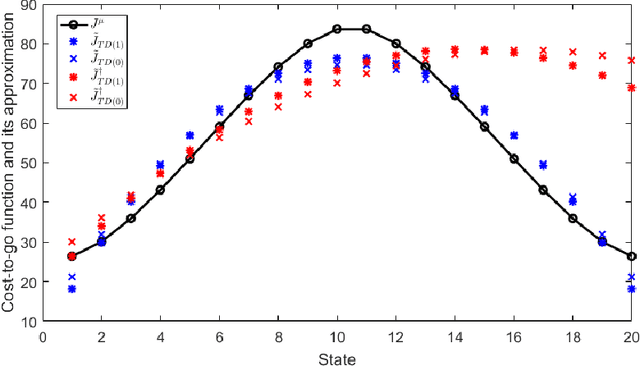
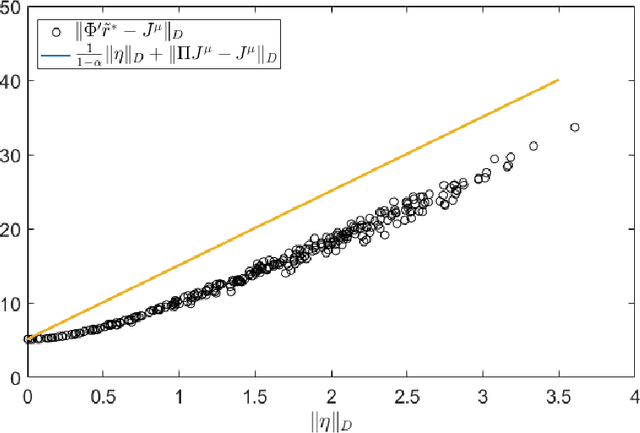
This chapter studies emerging cyber-attacks on reinforcement learning (RL) and introduces a quantitative approach to analyze the vulnerabilities of RL. Focusing on adversarial manipulation on the cost signals, we analyze the performance degradation of TD($\lambda$) and $Q$-learning algorithms under the manipulation. For TD($\lambda$), the approximation learned from the manipulated costs has an approximation error bound proportional to the magnitude of the attack. The effect of the adversarial attacks on the bound does not depend on the choice of $\lambda$. In $Q$-learning, we show that $Q$-learning algorithms converge under stealthy attacks and bounded falsifications on cost signals. We characterize the relation between the falsified cost and the $Q$-factors as well as the policy learned by the learning agent which provides fundamental limits for feasible offensive and defensive moves. We propose a robust region in terms of the cost within which the adversary can never achieve the targeted policy. We provide conditions on the falsified cost which can mislead the agent to learn an adversary's favored policy. A case study of TD($\lambda$) learning is provided to corroborate the results.
Deceptive Reinforcement Learning Under Adversarial Manipulations on Cost Signals
Aug 16, 2019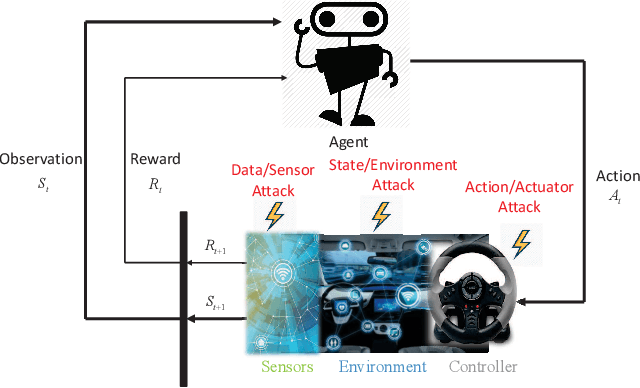
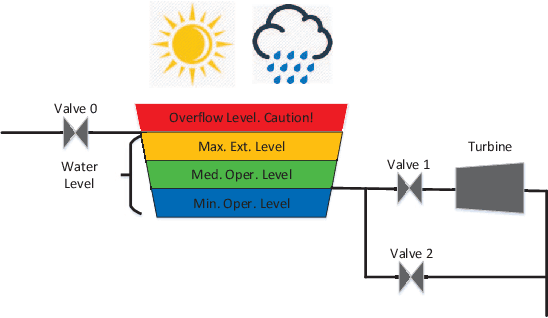
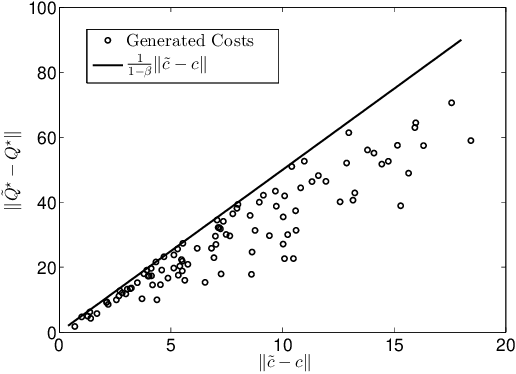
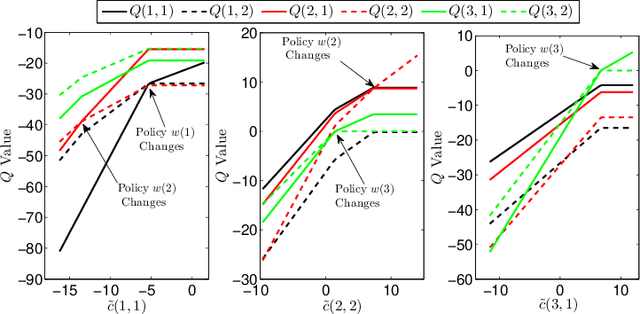
This paper studies reinforcement learning (RL) under malicious falsification on cost signals and introduces a quantitative framework of attack models to understand the vulnerabilities of RL. Focusing on $Q$-learning, we show that $Q$-learning algorithms converge under stealthy attacks and bounded falsifications on cost signals. We characterize the relation between the falsified cost and the $Q$-factors as well as the policy learned by the learning agent which provides fundamental limits for feasible offensive and defensive moves. We propose a robust region in terms of the cost within which the adversary can never achieve the targeted policy. We provide conditions on the falsified cost which can mislead the agent to learn an adversary's favored policy. A numerical case study of water reservoir control is provided to show the potential hazards of RL in learning-based control systems and corroborate the results.