 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Latent Reasoning via Looped Language Models
Oct 29, 2025



Modern LLMs are trained to "think" primarily via explicit text generation, such as chain-of-thought (CoT), which defers reasoning to post-training and under-leverages pre-training data. We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens. Ouro 1.4B and 2.6B models enjoy superior performance that match the results of up to 12B SOTA LLMs across a wide range of benchmarks. Through controlled experiments, we show this advantage stems not from increased knowledge capacity, but from superior knowledge manipulation capabilities. We also show that LoopLM yields reasoning traces more aligned with final outputs than explicit CoT. We hope our results show the potential of LoopLM as a novel scaling direction in the reasoning era. Our model could be found in: http://ouro-llm.github.io.
TurtleBench: Evaluating Top Language Models via Real-World Yes/No Puzzles
Oct 07, 2024


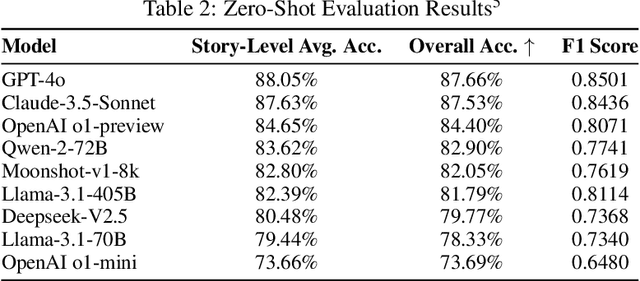
As the application of Large Language Models (LLMs) expands, the demand for reliable evaluations increases. Existing LLM evaluation benchmarks primarily rely on static datasets, making it challenging to assess model performance in dynamic interactions with users. Moreover, these benchmarks often depend on specific background knowledge, complicating the measurement of a model's logical reasoning capabilities. Other dynamic evaluation methods based on strong models or manual efforts may introduce biases and incur high costs and time demands, hindering large-scale application. To address these issues, we propose TurtleBench. TurtleBench collects real user guesses from our online Turtle Soup Puzzle platform that we developed. This approach allows for the relatively dynamic generation of evaluation datasets, mitigating the risk of model cheating while aligning assessments more closely with genuine user needs for reasoning capabilities, thus enhancing the reliability of evaluations. TurtleBench includes 1,532 user guesses along with the correctness of guesses after annotation. Using this dataset, we thoroughly evaluated nine of the most advanced LLMs available today. Notably, the OpenAI o1 series models did not achieve leading results in these evaluations. We propose several hypotheses for further research, such as "the latent reasoning of o1 utilizes trivial Chain-of-Thought (CoT) techniques" and "increasing CoT length not only provides reasoning benefits but also incurs noise costs."