 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLRecon: Robust Markerless Freehand 3D Ultrasound Reconstruction via Coarse-to-Fine Pose Estimation
Mar 01, 2026Freehand 3D ultrasound (US) reconstruction promises volumetric imaging with the flexibility of standard 2D probes, yet existing tracking paradigms face a restrictive trilemma: marker-based systems demand prohibitive costs, inside-out methods require intrusive sensor attachment, and sensorless approaches suffer from severe cumulative drift. To overcome these limitations, we present MLRecon, a robust markerless 3D US reconstruction framework delivering drift-resilient 6D probe pose tracking using a single commodity RGB-D camera. Leveraging the generalization power of vision foundation models, our pipeline enables continuous markerless tracking of the probe, augmented by a vision-guided divergence detector that autonomously monitors tracking integrity and triggers failure recovery to ensure uninterrupted scanning. Crucially, we further propose a dual-stage pose refinement network that explicitly disentangles high-frequency jitter from low-frequency bias, effectively denoising the trajectory while maintaining the kinematic fidelity of operator maneuvers. Experiments demonstrate that MLRecon significantly outperforms competing sensorless and sensor-aided methods, achieving average position errors as low as 0.88 mm on complex trajectories and yielding high-quality 3D reconstructions with sub-millimeter mean surface accuracy. This establishes a new benchmark for low-cost, accessible volumetric US imaging in resource-limited clinical settings.
Google street view and deep learning: a new ground truthing approach for crop mapping
Dec 03, 2019

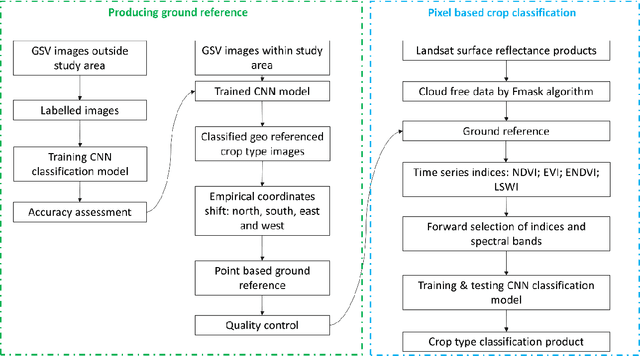

Ground referencing is essential for supervised crop mapping. However, conventional ground truthing involves extensive field surveys and post processing, which is costly in terms of time and labor. In this study, we applied a convolutional neural network (CNN) model to explore the efficacy of automatic ground truthing via Google street view (GSV) images in two distinct farming regions: central Illinois and southern California. We demonstrated the feasibility and reliability of the new ground referencing technique further by performing pixel-based crop mapping with vegetation indices as the model input. The results were evaluated using the United States Department of Agriculture (USDA) crop data layer (CDL) products. From 8,514 GSV images, the CNN model screened out 2,645 target crop images. These images were well classified into crop types, including alfalfa, almond, corn, cotton, grape, soybean, and pistachio. The overall GSV image classification accuracy reached 93% in California and 97% in Illinois. We then shifted the image geographic coordinates using fixed empirical coefficients to produce 8,173 crop reference points including 1,764 in Illinois and 6,409 in California. Evaluation of these new reference points with CDL products showed satisfactory coherence, with 94 to 97% agreement. CNN-based mapping also captured the general pattern of crop type distributions. The overall differences between CDL products and our mapping results were 4% in California and 5% in Illinois. Thus, using these deep learning and GSV image techniques, we have provided an efficient and cost-effective alternative method for ground referencing and crop mapping.