 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSquare$χ$PO: Differentially Private and Robust $χ^2$-Preference Optimization in Offline Direct Alignment
May 27, 2025In this paper, we theoretically study the offline alignment of language models with human preference feedback, under both preference label corruption and privacy protections. To this end, we propose Square$\chi$PO, a simple one-line change to $\chi$PO where the standard log-loss is replaced by a new square loss over probability. Thanks to the inherent properties of this new loss, we have advanced the state-of-the-art of differentially private and robust offline direct alignment. Specifically, for the local model of label privacy, Square$\chi$PO is the first algorithm that attains an optimal rate based on single-policy concentrability even with general function approximations. It also gives the first result under the central model of privacy protection over both prompts (responses) and labels. On the robustness side against Huber label corruption, Square$\chi$PO is the first alignment method that has a meaningful theoretical guarantee under general function approximations. More importantly, Square$\chi$PO can address privacy protection and corruption simultaneously, where an interesting separation is observed, implying that the order of privacy and corruption matters. Furthermore, we show that Square$\chi$PO can also be easily extended to handle the scenario of the general preference model with state-of-the-art guarantees under corruption and privacy. Last but not least, all of our theoretical guarantees enjoy a unified analysis, building upon a new result on the generalization error bounds of least-square regression under corruption and privacy constraints, which we believe is of independent interest to the community.
A Unified Theoretical Analysis of Private and Robust Offline Alignment: from RLHF to DPO
May 21, 2025In this paper, we theoretically investigate the effects of noisy labels in offline alignment, with a focus on the interplay between privacy and robustness against adversarial corruption. Specifically, under linear modeling assumptions, we present a unified analysis covering both reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO) under different privacy-corruption scenarios, such as Local differential privacy-then-Corruption (LTC), where human preference labels are privatized before being corrupted by an adversary, and Corruption-then-Local differential privacy (CTL), where labels are corrupted before privacy protection. Our analysis leverages a reduction framework that reduces the offline alignment problem under linear modeling assumptions to parameter estimation in logistic regression. This framework allows us to establish an interesting separation result between LTC and CTL, demonstrating that LTC presents a greater challenge than CTL in offline alignment, even under linear models. As important by-products, our findings also advance the state-of-the-art theoretical results in offline alignment under privacy-only or corruption-only scenarios.
Optimal Regret of Bernoulli Bandits under Global Differential Privacy
May 08, 2025As sequential learning algorithms are increasingly applied to real life, ensuring data privacy while maintaining their utilities emerges as a timely question. In this context, regret minimisation in stochastic bandits under $\epsilon$-global Differential Privacy (DP) has been widely studied. Unlike bandits without DP, there is a significant gap between the best-known regret lower and upper bound in this setting, though they "match" in order. Thus, we revisit the regret lower and upper bounds of $\epsilon$-global DP algorithms for Bernoulli bandits and improve both. First, we prove a tighter regret lower bound involving a novel information-theoretic quantity characterising the hardness of $\epsilon$-global DP in stochastic bandits. Our lower bound strictly improves on the existing ones across all $\epsilon$ values. Then, we choose two asymptotically optimal bandit algorithms, i.e. DP-KLUCB and DP-IMED, and propose their DP versions using a unified blueprint, i.e., (a) running in arm-dependent phases, and (b) adding Laplace noise to achieve privacy. For Bernoulli bandits, we analyse the regrets of these algorithms and show that their regrets asymptotically match our lower bound up to a constant arbitrary close to 1. This refutes the conjecture that forgetting past rewards is necessary to design optimal bandit algorithms under global DP. At the core of our algorithms lies a new concentration inequality for sums of Bernoulli variables under Laplace mechanism, which is a new DP version of the Chernoff bound. This result is universally useful as the DP literature commonly treats the concentrations of Laplace noise and random variables separately, while we couple them to yield a tighter bound.
Better-than-KL PAC-Bayes Bounds
Feb 14, 2024Let $f(\theta, X_1),$ $ \dots,$ $ f(\theta, X_n)$ be a sequence of random elements, where $f$ is a fixed scalar function, $X_1, \dots, X_n$ are independent random variables (data), and $\theta$ is a random parameter distributed according to some data-dependent posterior distribution $P_n$. In this paper, we consider the problem of proving concentration inequalities to estimate the mean of the sequence. An example of such a problem is the estimation of the generalization error of some predictor trained by a stochastic algorithm, such as a neural network where $f$ is a loss function. Classically, this problem is approached through a PAC-Bayes analysis where, in addition to the posterior, we choose a prior distribution which captures our belief about the inductive bias of the learning problem. Then, the key quantity in PAC-Bayes concentration bounds is a divergence that captures the complexity of the learning problem where the de facto standard choice is the KL divergence. However, the tightness of this choice has rarely been questioned. In this paper, we challenge the tightness of the KL-divergence-based bounds by showing that it is possible to achieve a strictly tighter bound. In particular, we demonstrate new high-probability PAC-Bayes bounds with a novel and better-than-KL divergence that is inspired by Zhang et al. (2022). Our proof is inspired by recent advances in regret analysis of gambling algorithms, and its use to derive concentration inequalities. Our result is first-of-its-kind in that existing PAC-Bayes bounds with non-KL divergences are not known to be strictly better than KL. Thus, we believe our work marks the first step towards identifying optimal rates of PAC-Bayes bounds.
Differentially Private Episodic Reinforcement Learning with Heavy-tailed Rewards
Jun 05, 2023



In this paper, we study the problem of (finite horizon tabular) Markov decision processes (MDPs) with heavy-tailed rewards under the constraint of differential privacy (DP). Compared with the previous studies for private reinforcement learning that typically assume rewards are sampled from some bounded or sub-Gaussian distributions to ensure DP, we consider the setting where reward distributions have only finite $(1+v)$-th moments with some $v \in (0,1]$. By resorting to robust mean estimators for rewards, we first propose two frameworks for heavy-tailed MDPs, i.e., one is for value iteration and another is for policy optimization. Under each framework, we consider both joint differential privacy (JDP) and local differential privacy (LDP) models. Based on our frameworks, we provide regret upper bounds for both JDP and LDP cases and show that the moment of distribution and privacy budget both have significant impacts on regrets. Finally, we establish a lower bound of regret minimization for heavy-tailed MDPs in JDP model by reducing it to the instance-independent lower bound of heavy-tailed multi-armed bandits in DP model. We also show the lower bound for the problem in LDP by adopting some private minimax methods. Our results reveal that there are fundamental differences between the problem of private RL with sub-Gaussian and that with heavy-tailed rewards.
Quantum Computing Provides Exponential Regret Improvement in Episodic Reinforcement Learning
Feb 16, 2023

In this paper, we investigate the problem of \textit{episodic reinforcement learning} with quantum oracles for state evolution. To this end, we propose an \textit{Upper Confidence Bound} (UCB) based quantum algorithmic framework to facilitate learning of a finite-horizon MDP. Our quantum algorithm achieves an exponential improvement in regret as compared to the classical counterparts, achieving a regret of $\Tilde{\mathcal{O}}(1)$ as compared to $\Tilde{\mathcal{O}}(\sqrt{K})$ \footnote{$\Tilde{\mathcal{O}}(\cdot)$ hides logarithmic terms.}, $K$ being the number of training episodes. In order to achieve this advantage, we exploit efficient quantum mean estimation technique that provides quadratic improvement in the number of i.i.d. samples needed to estimate the mean of sub-Gaussian random variables as compared to classical mean estimation. This improvement is a key to the significant regret improvement in quantum reinforcement learning. We provide proof-of-concept experiments on various RL environments that in turn demonstrate performance gains of the proposed algorithmic framework.
On Private and Robust Bandits
Feb 06, 2023
We study private and robust multi-armed bandits (MABs), where the agent receives Huber's contaminated heavy-tailed rewards and meanwhile needs to ensure differential privacy. We first present its minimax lower bound, characterizing the information-theoretic limit of regret with respect to privacy budget, contamination level and heavy-tailedness. Then, we propose a meta-algorithm that builds on a private and robust mean estimation sub-routine \texttt{PRM} that essentially relies on reward truncation and the Laplace mechanism only. For two different heavy-tailed settings, we give specific schemes of \texttt{PRM}, which enable us to achieve nearly-optimal regret. As by-products of our main results, we also give the first minimax lower bound for private heavy-tailed MABs (i.e., without contamination). Moreover, our two proposed truncation-based \texttt{PRM} achieve the optimal trade-off between estimation accuracy, privacy and robustness. Finally, we support our theoretical results with experimental studies.
Quantum Heavy-tailed Bandits
Jan 23, 2023



In this paper, we study multi-armed bandits (MAB) and stochastic linear bandits (SLB) with heavy-tailed rewards and quantum reward oracle. Unlike the previous work on quantum bandits that assumes bounded/sub-Gaussian distributions for rewards, here we investigate the quantum bandits problem under a weaker assumption that the distributions of rewards only have bounded $(1+v)$-th moment for some $v\in (0,1]$. In order to achieve regret improvements for heavy-tailed bandits, we first propose a new quantum mean estimator for heavy-tailed distributions, which is based on the Quantum Monte Carlo Mean Estimator and achieves a quadratic improvement of estimation error compared to the classical one. Based on our quantum mean estimator, we focus on quantum heavy-tailed MAB and SLB and propose quantum algorithms based on the Upper Confidence Bound (UCB) framework for both problems with $\Tilde{O}(T^{\frac{1-v}{1+v}})$ regrets, polynomially improving the dependence in terms of $T$ as compared to classical (near) optimal regrets of $\Tilde{O}(T^{\frac{1}{1+v}})$, where $T$ is the number of rounds. Finally, experiments also support our theoretical results and show the effectiveness of our proposed methods.
Optimal Rates of (Locally) Differentially Private Heavy-tailed Multi-Armed Bandits
Jun 07, 2021
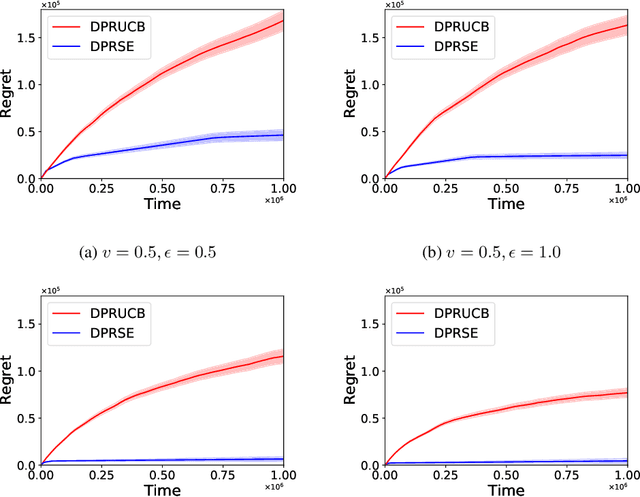
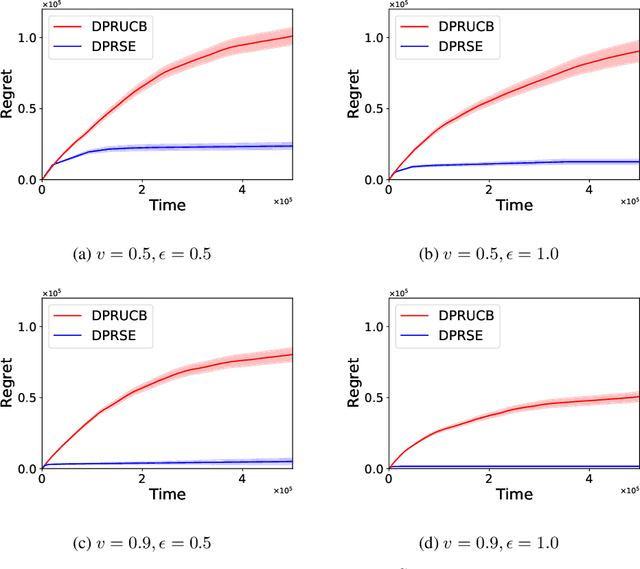
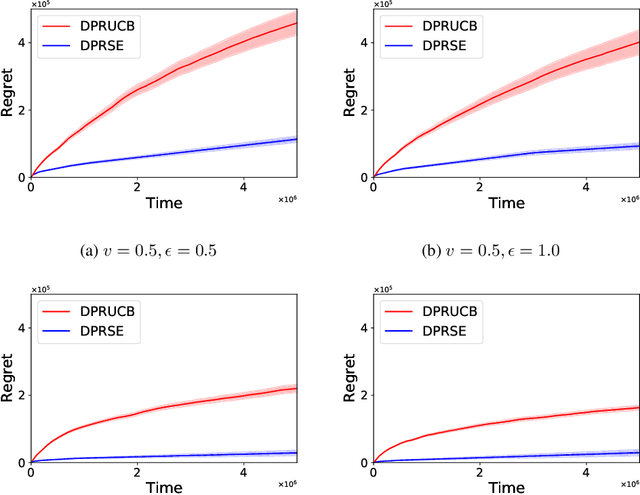
In this paper we study the problem of stochastic multi-armed bandits (MAB) in the (local) differential privacy (DP/LDP) model. Unlike the previous results which need to assume bounded reward distributions, here we mainly focus on the case the reward distribution of each arm only has $(1+v)$-th moment with some $v\in (0, 1]$. In the first part, we study the problem in the central $\epsilon$-DP model. We first provide a near-optimal result by developing a private and robust Upper Confidence Bound (UCB) algorithm. Then, we improve the result via a private and robust version of the Successive Elimination (SE) algorithm. Finally, we show that the instance-dependent regret bound of our improved algorithm is optimal by showing its lower bound. In the second part of the paper, we study the problem in the $\epsilon$-LDP model. We propose an algorithm which could be seen as locally private and robust version of the SE algorithm, and show it could achieve (near) optimal rates for both instance-dependent and instance-independent regrets. All of the above results can also reveal the differences between the problem of private MAB with bounded rewards and heavy-tailed rewards. To achieve these (near) optimal rates, we develop several new hard instances and private robust estimators as byproducts, which might could be used to other related problems. Finally, experimental results also support our theoretical analysis and show the effectiveness of our algorithms.