 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassFace: an efficient implementation using triplet loss for face recognition
Feb 28, 2019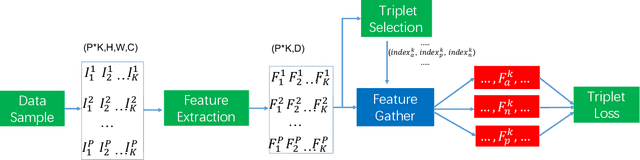
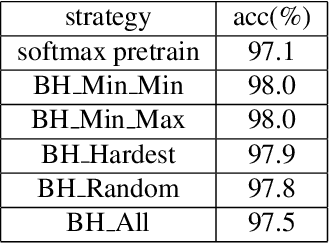
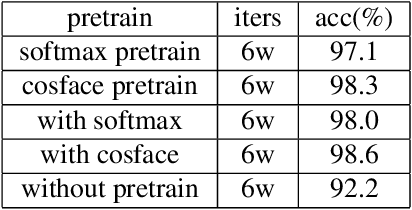
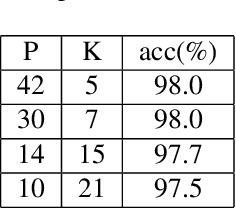
In this paper we present an efficient implementation using triplet loss for face recognition. We conduct the practical experiment to analyze the factors that influence the training of triplet loss. All models are trained on CASIA-Webface dataset and tested on LFW. We analyze the experiment results and give some insights to help others balance the factors when they apply triplet loss to their own problem especially for face recognition task. Code has been released in https://github.com/yule-li/MassFace.
Low-Latency Video Semantic Segmentation
Apr 02, 2018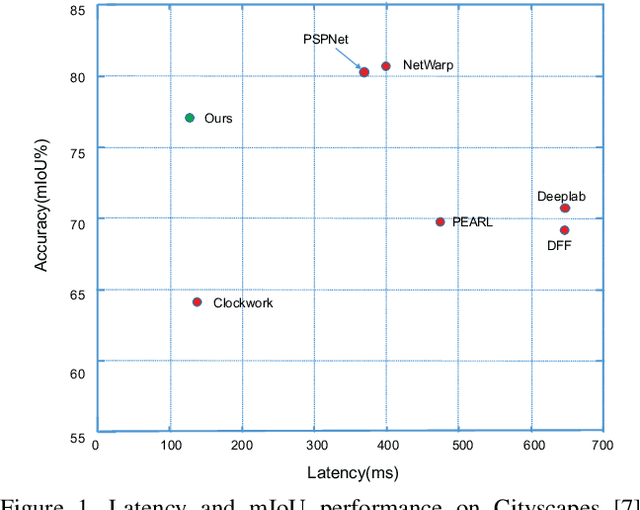
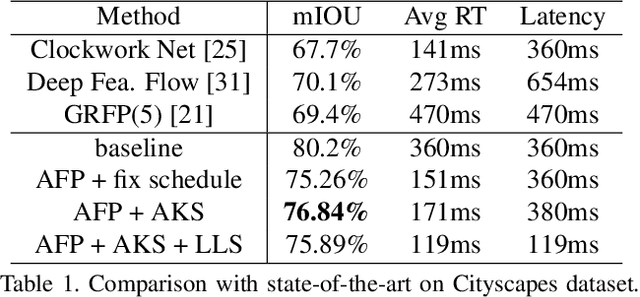
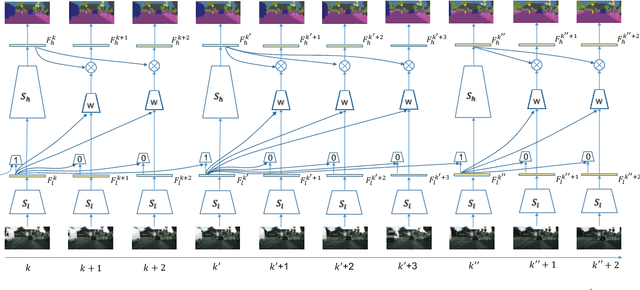

Recent years have seen remarkable progress in semantic segmentation. Yet, it remains a challenging task to apply segmentation techniques to video-based applications. Specifically, the high throughput of video streams, the sheer cost of running fully convolutional networks, together with the low-latency requirements in many real-world applications, e.g. autonomous driving, present a significant challenge to the design of the video segmentation framework. To tackle this combined challenge, we develop a framework for video semantic segmentation, which incorporates two novel components: (1) a feature propagation module that adaptively fuses features over time via spatially variant convolution, thus reducing the cost of per-frame computation; and (2) an adaptive scheduler that dynamically allocate computation based on accuracy prediction. Both components work together to ensure low latency while maintaining high segmentation quality. On both Cityscapes and CamVid, the proposed framework obtained competitive performance compared to the state of the art, while substantially reducing the latency, from 360 ms to 119 ms.